Accelerating Queries over Unstructured Data with ML, Part 4 (Accelerating Aggregation Queries with Expensive Predicates)
In this blog post, we’ll describe our recent work on accelerating approximate aggregation queries with expensive predicates. While this blog post will be self-contained, please see our other blog posts for other exciting developments and more context (part 1, part 2, part 3)!
Analysts and researchers are increasingly interested in using powerful machine learning models and human labeling services (which we’ll refer to as “oracles”) to compute statistics over their datasets. For example, a media studies researcher may want to understand how the presence of different presidential candidates on TV news affects viewership. They would like to be able to ask questions like “what is the average viewership when Joe Biden is on TV?” over the past year of news video and second-by-second viewership data.
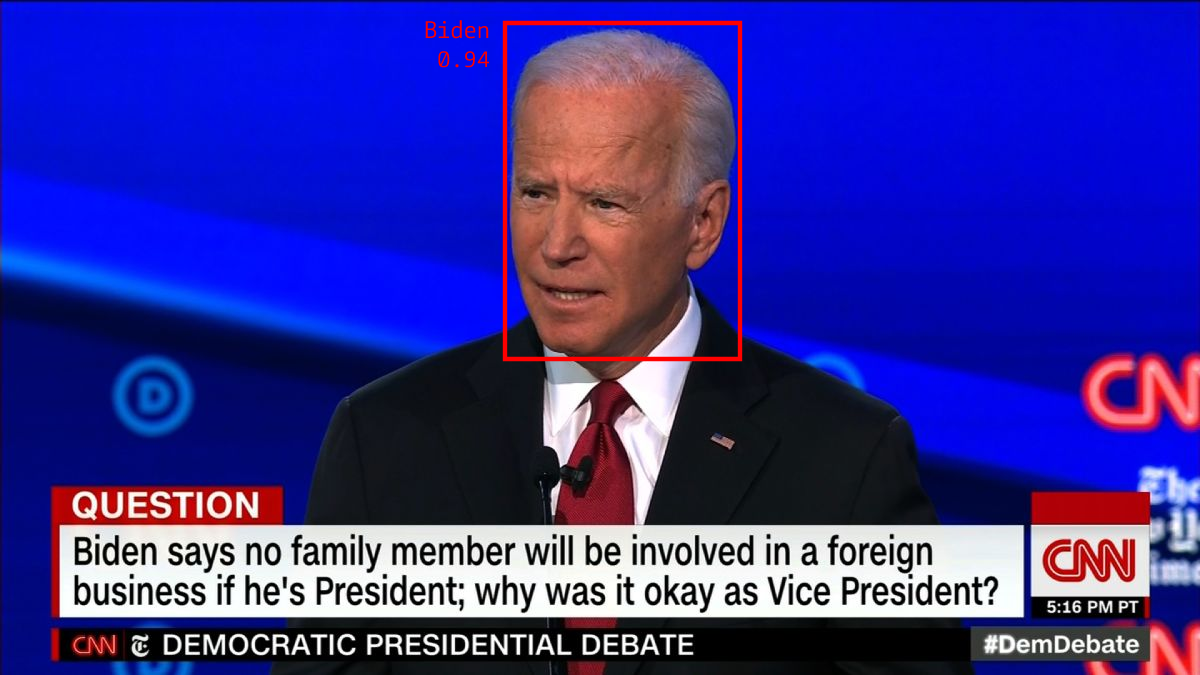
The naive way of answering this query requires annotating all of this data, filtering the dataset down to frames that contain Biden, and then computing the average. As you might guess, this process is too expensive for many organizations. Executing a state-of-the-art face detection model on cloud compute infrastructure (NVIDIA V100, Amazon Web Services) would cost $262,000 over the past year of news.
So, what can we do to make computing this statistic cheaper? What if we also had access to a face detection model which doesn’t perform as well as the state-of-the-art but runs much faster? While we could rely directly on the outputs of this worse model, analysts often need statistical guarantees in order to make scientific conclusions. Could we somehow use this model to our advantage while keeping the accuracy of the state-of-the-art?
Yes, we can! We refer to these models as “proxy models” (cheaper but less accurate models for the same task) and they have been used in the past to accelerate queries including aggregation, limit, and selection. Building on this work, we introduce ABae (Aggregation with Expensive Binary Predicates), a query processing algorithm, which can significantly accelerate the process of computing averages over subsets of large datasets by leveraging these proxy models.
In the remainder of this post, we’ll walk through an example of ABae accelerating a query and explain how ABae works. Finally, we’ll show that ABae can reduce compute costs and labeling costs by more than 2x!
Using ABae
ABae targets aggregation queries (e.g., averages, sums, and counts) that contain one or more predicates that are expensive to evaluate. Thus, to control the cost of the query, the user defines an oracle limit, which limits the number of times the predicate can be computed.
To accelerate these queries, it is necessary for the user to provide a proxy model. A proxy model should be much cheaper to execute than the predicate and provide a guess (in the form of a probability between 0 to 1) as to whether a given data record satisfies the predicate.
Let’s see what we have to provide to ABae if we want to compute “what is the average viewership when Joe Biden is on TV?” over the past year of news.
SELECT AVG(views)
FROM CNN_DATASET
WHERE Mask-RCNN(image) = 'Joe Biden' AND 2020 < year < 2021
ORACLE LIMIT 1000
USING PROXY ResNet18
WITH PROBABILITY 0.95
Estimate: 1,535,346.37
Confidence Interval: [1,500,466.97, 1,75,216.73] with 95% Probability
As you can see, for this example query, we use a Mask-RCNN model to verify whether Joe Biden is in the frame, which is prohibitively expensive to use over the entire dataset as the model can only process around six images per second on an NVIDIA T4 GPU. As a result, we limit the execution of this model to 1,000 times (up to thirty minutes of GPU time).
For the proxy model, we utilize a small ResNet18 model which can run at over 12,000 FPS, which makes it possible to execute the model over the entire dataset. As long as the model provides reasonable guesses, ABae can significantly accelerate the query while retaining statistical guarantees with respect to the accuracy of the Mask-RCNN model.
After the query has been executed, ABae returns the estimated answer along with a confidence interval at the specified confidence level.
How ABae Works
Now that we understand what the inputs and outputs to ABae are, we’ll now take some time to explore how ABae works. The key challenge in answering these queries is that the user will often define a restrictive oracle limit (the number of times the expensive predicate can be computed). As a result, the quality of our answers is bottlenecked by finding enough predicate-matching records to make a good estimate.
This bottleneck becomes worse when we are dealing with predicates that are selective. For the running example with the media studies researcher, Biden is likely to appear in less than 1% of all TV news. Hence, if our oracle limit is 1,000, we should expect to find less than 10 frames with Biden in it. To be more concrete about this challenge, let’s consider how we may answer the query if we did not have access to a proxy.
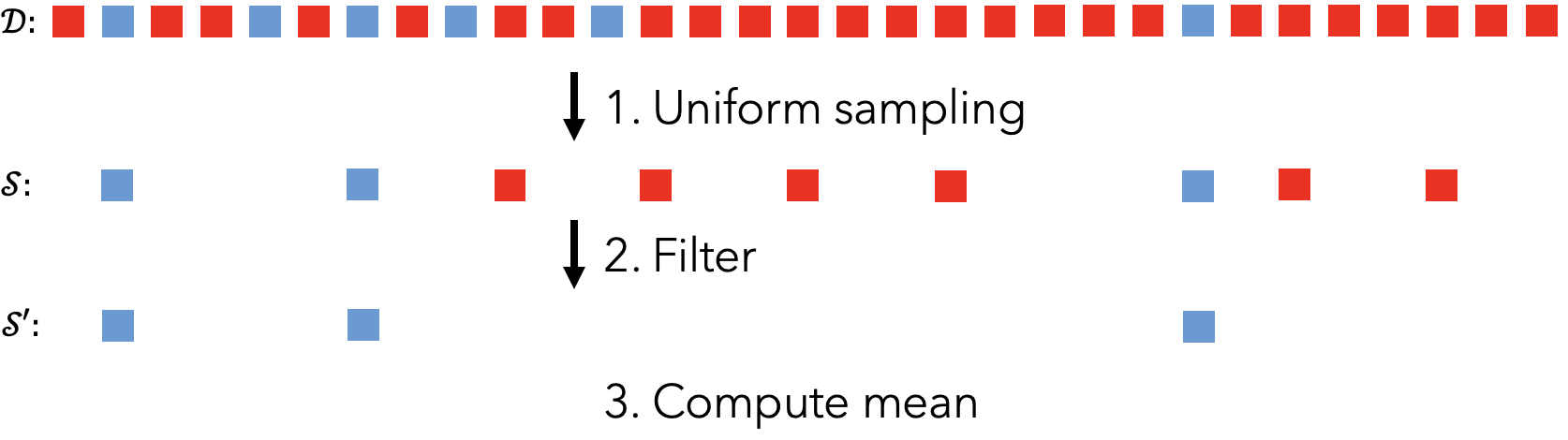
The naive way to answer this query would be to use uniform sampling. In the first step, we could uniformly sample N data records, where N refers to our oracle limit. Then, we could execute the expensive oracle method to filter out records that do not contain Biden. Finally, with the remaining records, we could compute an estimate of the average number of views. However, as mentioned before, because the percentage of frames that contain Biden is so small, we are likely to produce bad estimates.
The key to producing better estimates is to sample from a better distribution. By “better distribution,” we mean we want to use a sampling strategy that is more likely to get us data records with Biden in it than uniform sampling. ABae accomplishes this via the outputs of proxy models known as proxy scores.
In contrast to uniform sampling, ABae sorts the dataset by proxy score and splits the dataset into groups based on the ordering. If the proxy is reasonable, some groups should be more likely to contain predicate-matching records than others. So, by sampling more from these groups than others, we can get better estimates than uniform sampling.
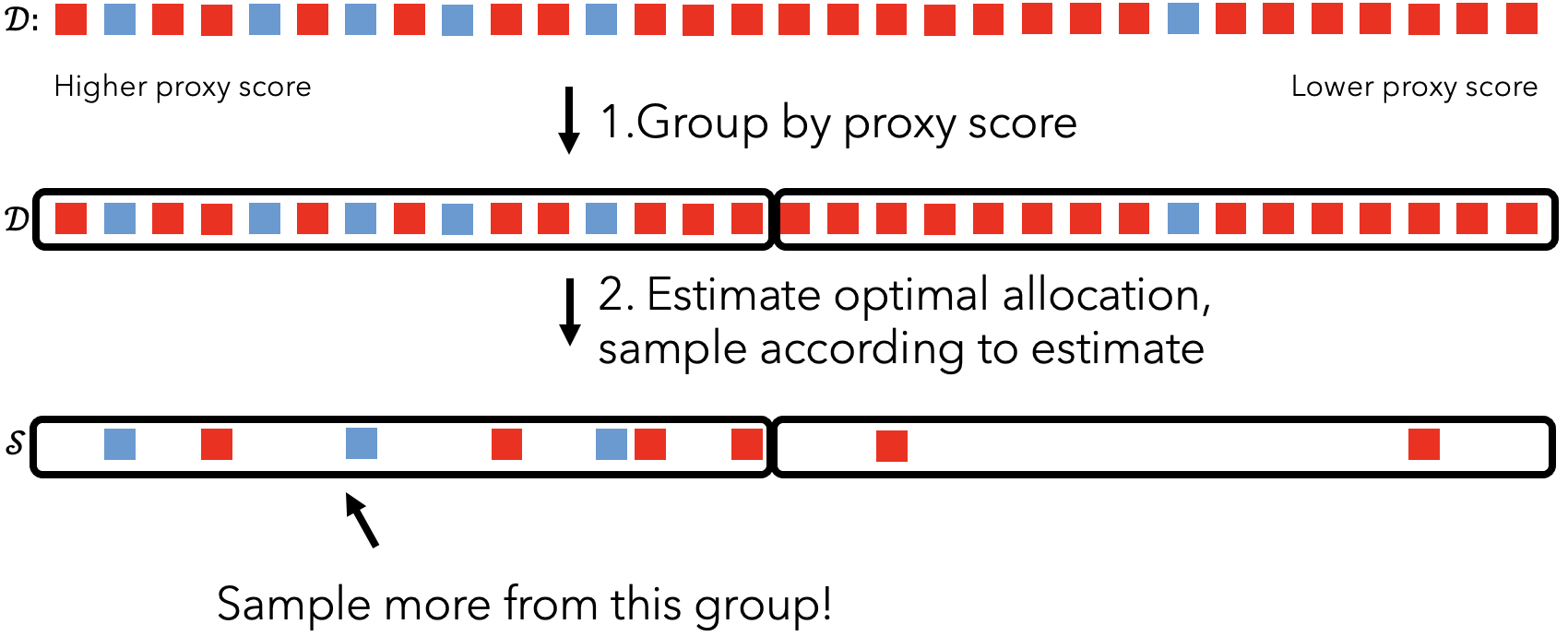
However, because ABae assumes nothing about the performance of the proxy, we cannot blindly use the groups associated with higher proxy scores. Instead, we use a fraction of the oracle limit to sample records from all groups, and then estimate the fraction of records that match the predicate and the variance of the statistic of interest for each group.
Using these two estimated quantities, we can then calculate the optimal sampling strategy that will minimize the squared error of our final estimate. We find that the optimal allocation is to sample proportional to the square root of the fraction of predicate-matching records in a group multiplied by the standard deviation of the statistic.
Results
To show the effectiveness of ABae, we conducted empirical experiments to measure how the root mean squared error of estimates from ABae compared to uniform sampling.
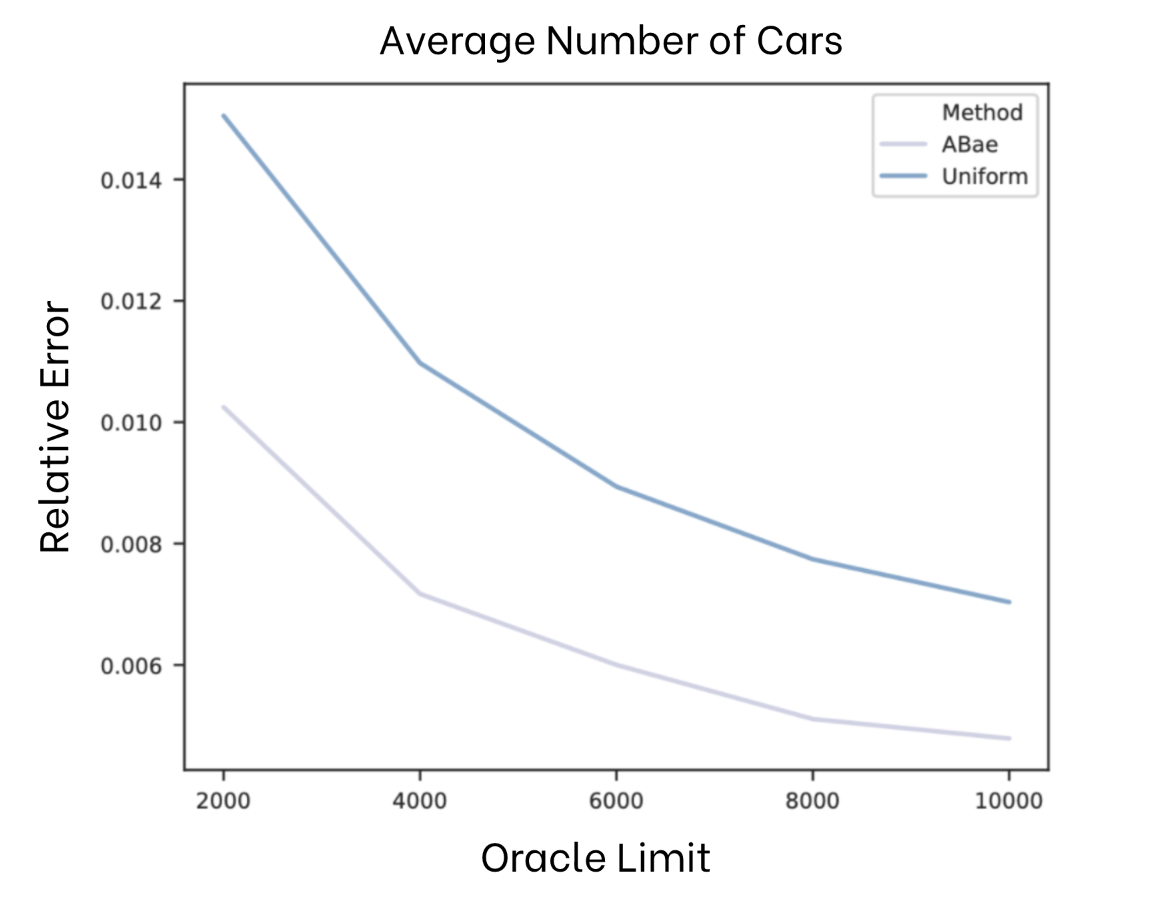
In one of these experiments, we studied how ABae could be used to compute the average number of cars across frames in traffic camera footage (Jackson Hole) given that there was at least one car in the frame. We utilize Mask-RCNN as the oracle and ResNet18 which runs more than 1,000x faster as the proxy. These models both estimate the number of cars in the frame.
SELECT AVG(Mask-RCNN(frame_img))
FROM jackson_hole
WHERE Mask-RCNN(frame_img) > 0
ORACLE LIMIT 4000
USING ResNet18
As you can see below, we vary the oracle limit and show the resulting RMSE of the query with lower RMSE being better. ABAe outperforms uniform sampling across all oracle limits we considered. Most importantly, these results imply that ABae can reduce annotation costs by up to 2x to match the results of uniform sampling.
Code
ABae can be easily used via our publicly available python package. It can be installed via
pip install -e . after cloning the repo. Below is an example of how to get started.
from abae import abae
data_records = None # list of your data
proxy_scores = None # list of proxy scores corresponding to data
oracle_fn = None # given a data record, returns (statistic (float), predicate (bool))
k = 5 # number of strata to use in ABae, five is a good choice
n = 10000 # oracle limit
n1 = int(n * 0.5 / k) # number of oracle calls to use for pilot sampling in each stratum
n2 = int(n* 0.5) # number of oracle calls to allocate optimally
alpha = 0.95 # confidence level for confidence interval
estimate, ci = abae(data_records, proxy_scores, oracle_fn, n1, n2, k, alpha)
Conclusion
There’s a lot we didn’t go into in this blog post. For more details about ABae–including how we return confidence intervals, support group by queries, and a theoretical analysis–please check out the paper!
In this blog post, we’ve described ABae, a query processing algorithm accelerating approximate aggregation queries with expensive predicates via proxy models. We’ll also be presenting our work on August 18th at 12:00 AM to 1:30 AM–please drop by our presentation! Finally, our code is open-sourced and we’re interested in hearing about new applications and use cases; contact us at ddkang@stanford.edu if you’d like to talk about our work.