Accelerating Queries over Unstructured Data with ML, Part 5 (Semantic Indexes for Machine Learning-based Queries over Unstructured Data)
In this blog post, we’ll describe our recent work on constructing indexes for unstructured data. As a sneak preview, our index can reduce ingest costs by 10x while simultaneously improving query costs by up to 24x over prior work! While this blog post will be self-contained, please see our other blog posts (part 1, part 2, part 3, part 4 for other exciting developments and more context!
As we described in part 1, unstructured data records (e.g., videos, text) are becoming increasingly possible to automatically query with the proliferation of power deep neural networks (DNNs), which we refer to as target DNNs. These target DNNs are used to extract structured information from unstructured data records. For example, an object detection method can extract object types and positions from frames of a video. Unfortunately, these target DNNs are too expensive to exhaustively annotate all the unstructured data records.
As we’ve described in previous blog posts, we can use proxy scores to accelerate queries (selection queries with guarantees, selection queries without guarantees, aggregation queries with predicates, whole dataset aggregation, and limit queries). Proxy scores approximate the result of the target DNN and are cheaper to generate than executing the target DNN. For example, consider the query of counting the average number of cars per frame of a video. The proxy score would approximate the number of cars in a given frame of video. A key question which we have not addressed is how to generate these proxy scores, which will be the main focus of this post.
Other systems generate these proxy scores by annotating a set of records with the target DNN and training a new proxy model per query; these proxy models are often small NNs (specialized NNs). This process is expensive at ingest time because it requires a large number of labels for training data and can be expensive at query time because it often requires training a new proxy model. Furthermore, ad-hoc methods of training proxy models give no guarantees on query accuracy.
To address these issues, we propose TASTI, a method for constructing indexes for unstructured data. TASTI can be used to answer all the queries discussed above, including selection queries, aggregation queries, aggregation queries with predicates, and limit queries!
We show that TASTI can be up to 10x cheaper at ingest time and can produce query results with up to 24x improved performance at query time. TASTI works by directly using target DNN annotations and a notion of similarity between data records. We’ll describe how to construct TASTI indexes and how to use them at query time below.
TASTI Overview
TASTI’s (trainable, semantic index) goal is to accelerate proxy score-based queries over unstructured data records by cheaply constructing an index at ingest time. At query time, TASTI will efficiently produce proxy scores for the given query and use downstream query processing algorithms to answer queries.
To do this, TASTI takes as input the target DNN, the schema induced by the target DNN, and a notion of similarity of records under this schema. At ingest time, TASTI will generate embeddings per data record with the property that close data records are close under the notion of similarity and annotate a small sample of records with the target DNN. At query time, TASTI will use the embedding distances and the sampled records to generate proxy scores.
Example
Before we dive into the full details, we’ll walk through an example of how TASTI works for a visual analytics use case. Our target DNN would be Mask R-CNN for predicting bounding boxes over video data. Given these bounding boxes, an analyst could ask queries of the form “count the number of cars per frame” (aggregation query) or “select frames with cars in the bottom right” (selection query).
TASTI requires a heuristic for “close” and “far” frames. Intuitively, frames with boxes that are close together should be close. We can specify this in code easily:
def is_close (frame1: List[Box], frame2: List [Box]) -> bool:
if len(frame1) != len(frame2):
return False
return all_boxes_close(frame1, frame2)
Given this notion of closeness, TASTI will do the work under the hood to produce proxy scores to answer a range of queries. As a concrete example, let’s say we want to count the number of cars per frame. TASTI will assign similar scores to the following two frames:


Now that we’ve seen an example, let’s see how TASTI works under the hood.
Constructing Indexes for Unstructured Data
We leverage two key insights in TASTI. First, we leverage that the target DNN induces a schema over the unstructured data records. For example, an object DNN will produce records about object types and positions (structured schema) given frames of a video (unstructured records). Second, we leverage that many applications have a natural notion of similarity under the schema. For example, we may consider frames of a video with similar object types and locations to be similar. Much of the prior work does not leverage the similarity between records, which results in inefficient index creation!
TASTI will first optionally train an embedding DNN that embeds data records with the desired property of similar records being similar in embedding space, which we show below. To do this, TASTI uses the triplet loss. While we won’t show it in this blog post, we prove in our paper that low triplet loss guarantees query accuracy under certain conditions. TASTI uses a small sample of records annotated by the target DNN to do this training procedure. We also show that TASTI can use pretrained DNNs as embedding DNNs if training is expensive.
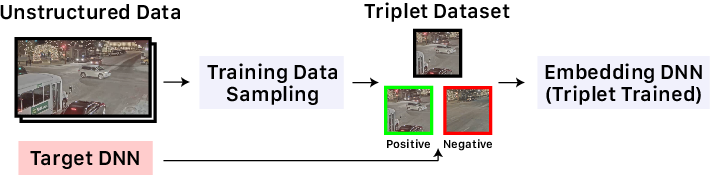
Given the embedding DNN, TASTI will generate embeddings per data record and select a set of records to annotate with the target DNN. We refer to the annotated records as cluster representatives. TASTI will additionally store distances to the cluster representatives. These cluster representatives will ideally both cover the “average” case but also rare events. To do this, TASTI selects cluster representatives using the farthest-point first algorithm, which selects a distinct set of points, mixed with randomly selected points. We show the overall procedure in the diagram below.

Our index construction procedure is also naturally amenable to database cracking, in which the index improves over repeated queries. As the target DNN is executed, TASTI can cache the results and store them as new cluster representatives. The distance computations are cheap relative to target DNN execution, so this procedure is cheap.
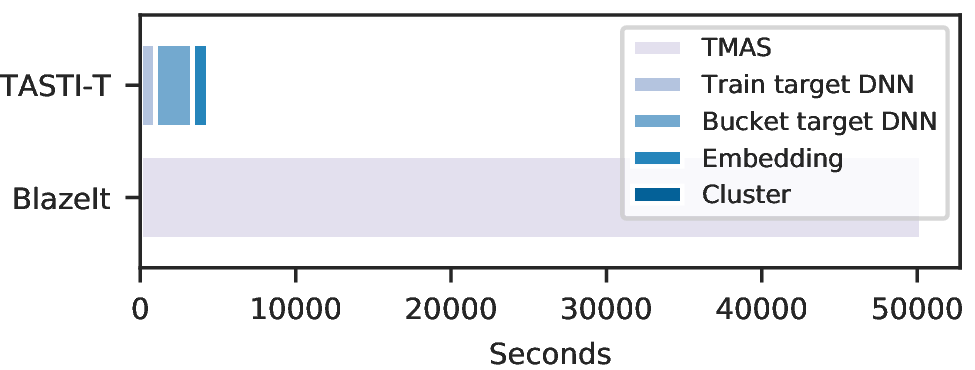
TASTI’s index construction procedure is also substantially cheaper than prior work. As an example, we show the overall index construction time (including training and embedding) for TASTI compared to BlazeIt. As we can see, TASTI is over 10x more efficient to construct than prior work.
Answering Queries with TASTI
TASTI is designed to accelerate query processing algorithms that require access to proxy scores. For example, we have designed algorithms for selection, aggregation, and limit queries, which we describe in previous posts. At a high level, these algorithms use the proxy score to approximate the ground truth and combine these approximations with statistical methods to return valid query results. Proxy scores can also be used to directly answer queries if statistical guarantees are not required.
To understand proxy scores, consider the example query of counting the number of cars per frame of a video. Given the output from an object detection method, the “ground truth” would be the total number of cars and a proxy score would approximate this quantity. More generally, the output from the target DNN is transformed to a numeric value, which the proxy score approximates.
For a given unannotated data record, TASTI generates proxy scores by averaging the values of the ground truth values of nearest cluster representatives. Since distance has semantic meaning for TASTI’s embeddings, we use the distance weighted average. We prove in the full paper that this procedure can give guarantees on query accuracy in certain cases. Furthermore, this procedure only requires distance computations, which is substantially cheaper than training and executing a proxy model per query.

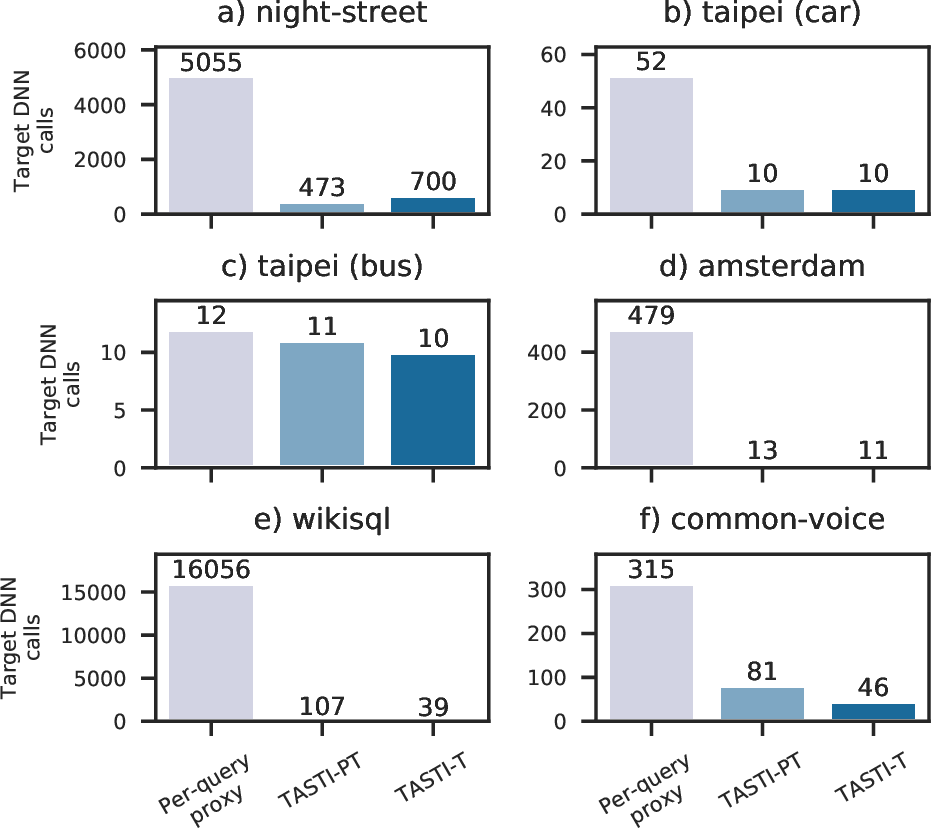
We show results when using TASTI’s proxy scores and proxy scores from a per-query proxy model for three classes of queries: selection queries with guarantees (SUPG queries), aggregation, and limit queries. As we can see, TASTI’s proxy scores outperform in all settings! We also show that TASTI can be used to answer other types of queries more effectively than prior work in the full paper.
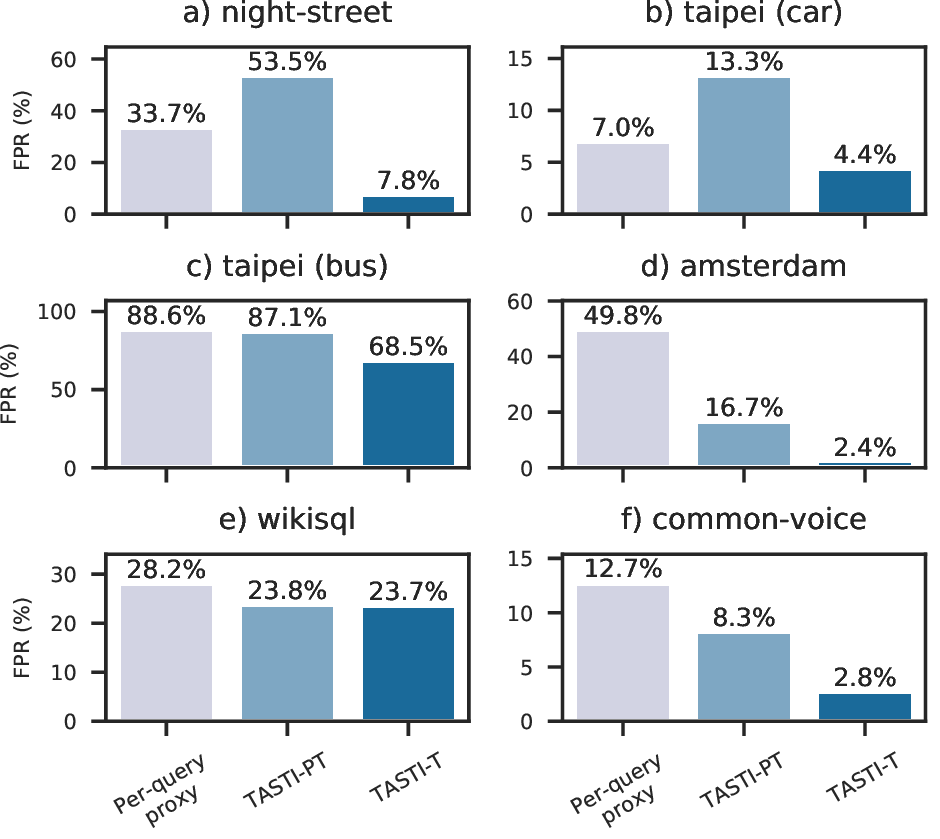
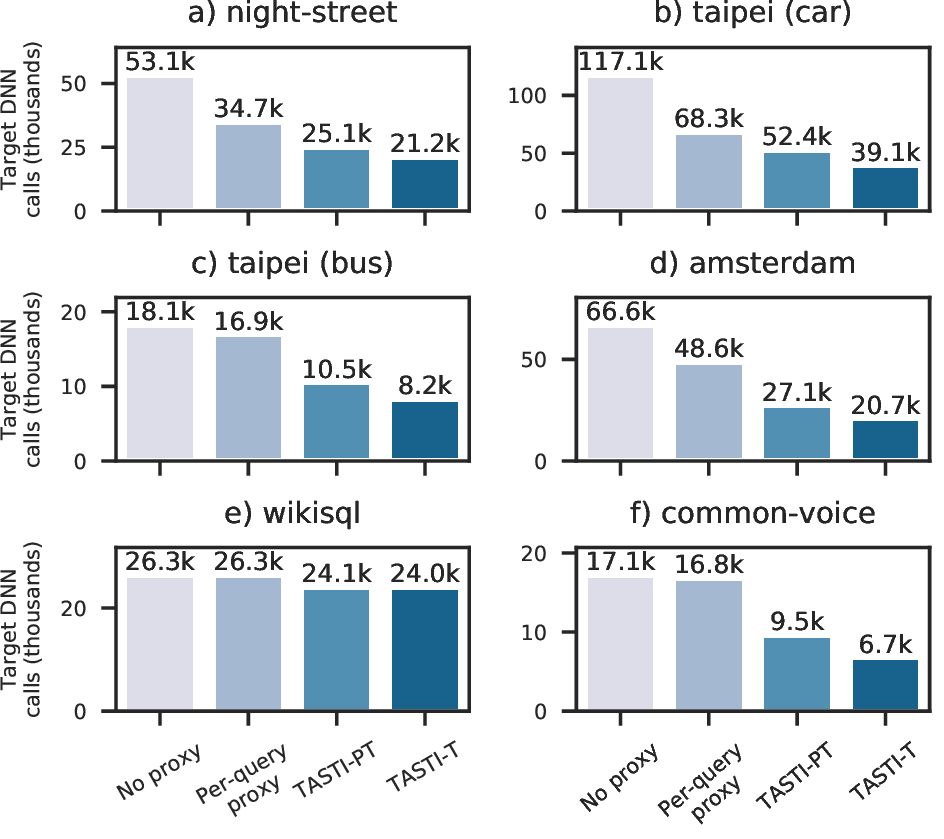
Conclusion
In this blog post, we’ve described how to generate indexes for unstructured data up to 10x faster than alternative methods. TASTI accomplishes this by leveraging schema-specific similarity between records, which previous ML-based analytics methods have not done! We’ve also described how to use this index to efficiently queries that use proxy scores with up to 24x improved results. Our code is open sourced and we have a preprint available here. If you’re interested in using or extending our work, please get in touch!