Accelerating Queries over Unstructured Data with ML, Part 1 (Accelerating Aggregation and Limit Queries with BlazeIt)
Unstructured data (e.g., videos, text) has become increasingly possible to automatically query with the proliferation of powerful deep neural networks (DNNs) and human-powered labeling services (which we collectively refer to as “oracle methods”). For example, an urban planner may query videos of street cameras to count vehicles to understand traffic patterns. As another example, a lawyer may be interested in extracting emails mentioning employee/employer information (“relation extraction”) for legal discovery.
One naive method to execute such queries is to use these oracle methods to fully materialize structured information from unstructured data records. For example, an object detection DNN can extract object types and object positions from a frame of a video or a BERT-based DNN could extract employee/employer information.
Unfortunately, this naive method of executing queries can be extremely costly: object detection DNNs can execute slower than 10x real-time and human labels can cost hundreds of thousands of dollars. To reduce the cost of such queries, NoScope, probabilistic predicates, and other recent work has proposed using proxy models, in which a cheap model is trained to approximate the oracle method and produce proxy scores, primarily in ad-hoc ways for binary predicates. However, there’s much more work to be done for executing queries over unstructured data. We’re excited to present several new projects from our group that tackles big problems in this space.
We’ll have a series of blog posts describing our recent work on accelerating queries over unstructured data:
- In this blog post, we’ll describe our recent work, BlazeIt, that will be presented at VLDB 2020. We’ll describe how to accelerate aggregation and limit queries.
- In part 2, we’ll describe a new class of queries: approximate selection queries with statistical guarantees (SUPG queries). We’ll describe why we need statistical guarantees, its semantics, and efficient algorithms for these queries. SUPG will also be presented at VLDB 2020!
- In part 3, we’ll describe systems bottlenecks in DNN-based queries over visual data. We’ll show that preprocessing of visual data is now a major bottleneck and how to alleviate this bottleneck. Our paper on this work will be forthcoming in VLDB 2021.
- In part 4, we’ll describe how to index unstructured data for a variety of queries over the same data. We’ll show how to use our index to efficiently answer all of the queries in the previous blog posts and more.
Proxy Scores
Prior work in query processing has studied using proxy models in the context of approximating binary predicates. These algorithms follow the same general strategy: they train a smaller, cheaper proxy model using labels from the oracle method. This proxy model then produces a score per data record that estimates the likelihood of the oracle predicate holding. For example, we might train a small DNN to estimate whether a car is in a frame of video.
However, many queries do not simply execute binary predicates. For example, a query counting the number of cars per frame of video would not benefit from knowing if there are cars in the frame or not.
To rectify this problem, we introduce proxy models beyond binary predicates. In this post, we’ll focus on proxy models for approximating arbitrary values produced by the oracle method over unstructured data records. At ingest time, our system processes a small fraction of records with the oracle method: these records are then used at query time to train a proxy model to estimate the result of the oracle.
Using Proxy Scores in Query Processing
Now that we can generate proxy scores to approximate the result of the oracle methods for computing statistics, how can we use these scores to answer queries? We’ll briefly describe how to answer approximate aggregation and cardinality-limited selection queries.
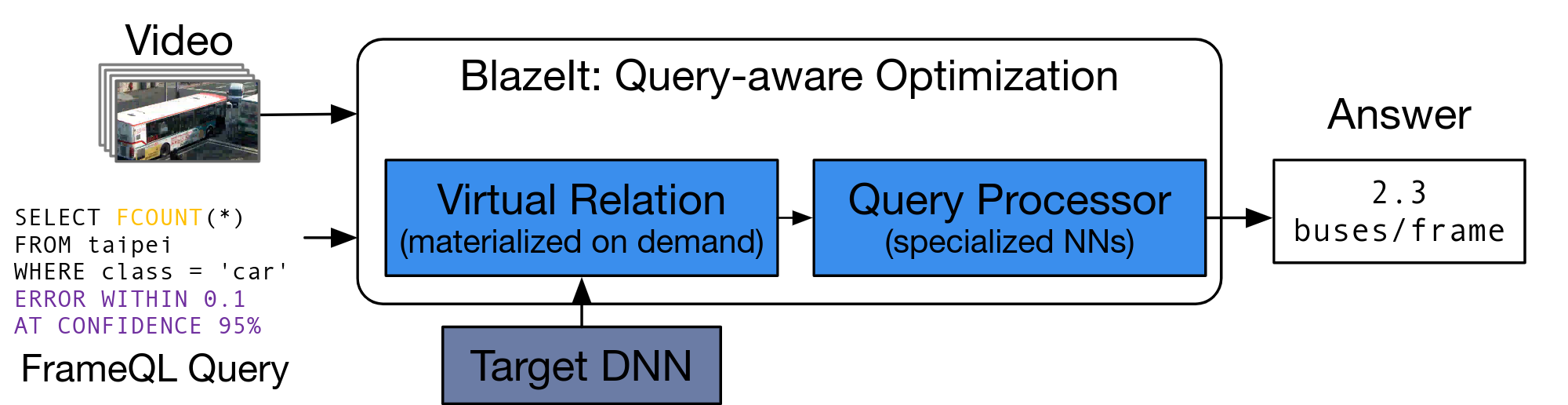
System overview
BlazeIt has two key components: an ingest (offline) component and a query processing component. In its offline component, BlazeIt will annotate a sample of unstructured data records with the oracle method: these annotations are used to train the proxy models. BlazeIt’s query processing component will execute queries, training a new proxy model per query. We show a system diagram below.
Approximate Aggregation
The first query type we describe how to accelerate are approximate aggregation queries, in which the query approximates some per-record statistic over the dataset (e.g., counting the number of cars per frame of video). We focus on approximate aggregation since providing exact answers to queries requires exhaustively executing the oracle method, which is prohibitively expensive. To avoid exhaustive materialization, we provide two query processing algorithms.
We show that we can directly use proxy scores to answer approximate aggregation queries. Since the proxy score approximates the ground truth, we can aggregate the scores directly. For example, to compute a per-record average, we can sum the proxy scores and divide sum by the total number of records. Since the proxy model was trained from the oracle method, errors between the proxy and oracle will ideally average out. We show that directly using proxy scores can be substantially more efficient than alternative methods of answering aggregation queries.
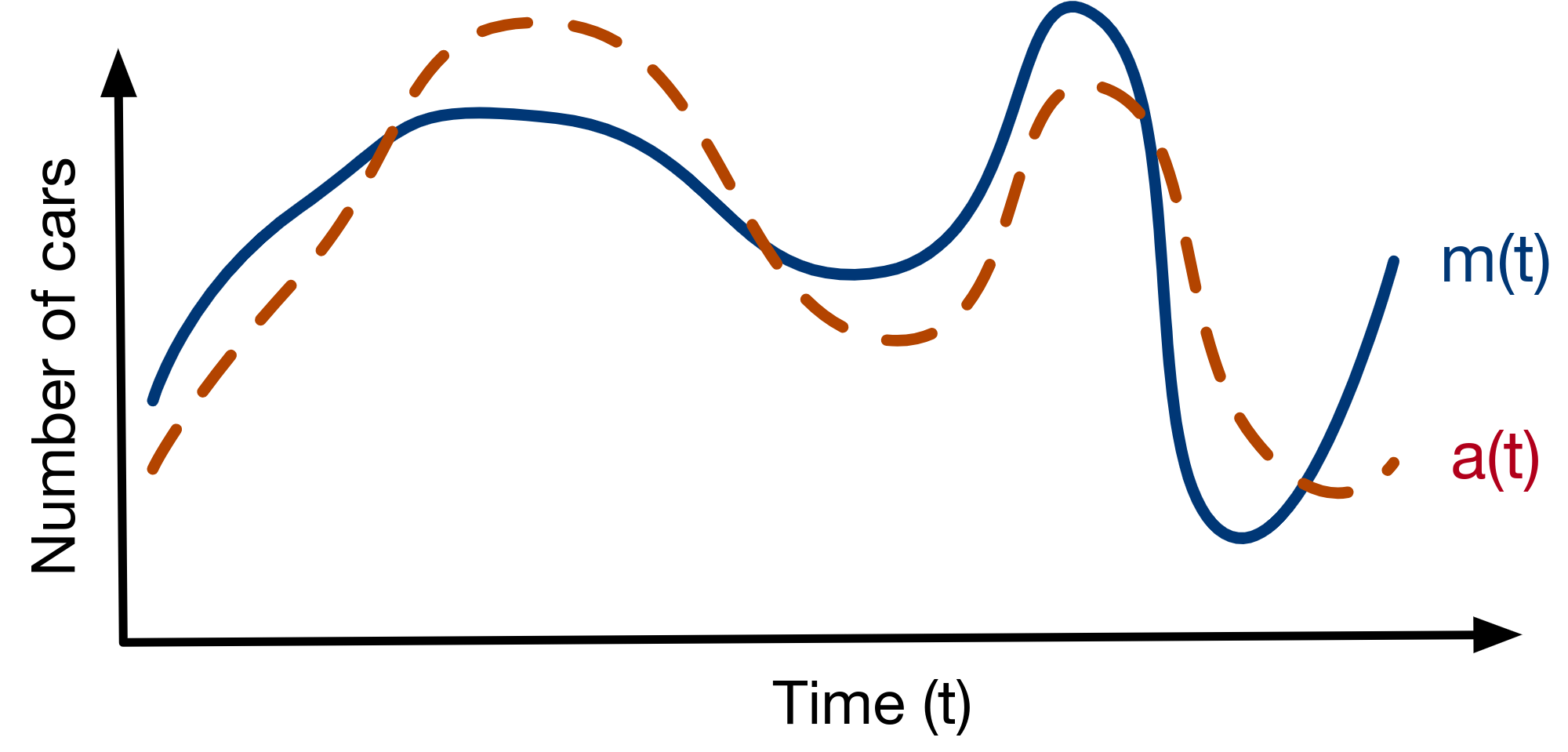
While directly using proxy scores can be efficient, certain applications require statistical guarantees on query accuracy. To provide such guarantees, we can use sampling techniques to accelerate approximate aggregation queries, inspired by techniques in approximate query processing (AQP). By appropriately using confidence intervals, we can achieve statistical guarantees on queries. However, standard AQP techniques do not use proxy scores in sampling, which are a valuable source of information. To leverage proxy scores, we use them as a control variate, which is a statistical method to reduce the variance of sampling. Finally, we combine control variates with an always-valid stopping algorithm that uses fewer samples with lower variance, called EBS stopping. Combined, this allows our system to use fewer samples for a given error level. We show a schematic of control variates and the algorithm overview below - the key part of the algorithm is that it is always valid and terminates based on the sample variance.
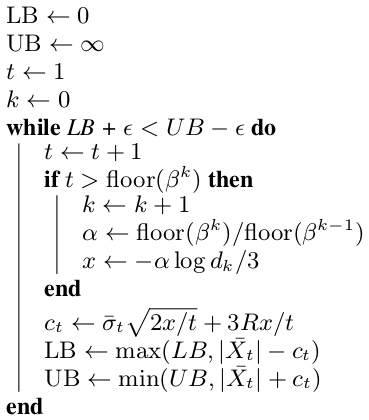
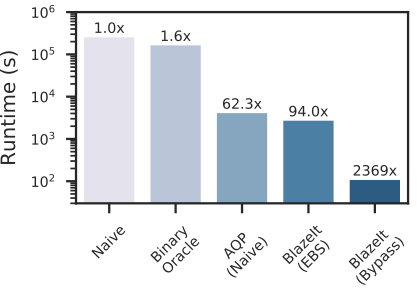
To show the utility of our algorithms, we show how they perform on approximating the number of cars per frame of video. We compare against the naive method and prior work using proxy models for determining if a car is in a frame or not. As we can see in the plot below, our methods strongly outperform baselines. In particular, knowing if a car is in the frame or not does not help if the video mostly contains cars.
Cardinality-limited Selection
The second query type we describe how to accelerate are cardinality limited selection queries, in which a limited number of records that satisfy some conditions. These queries are typically used to manually study rare events.
To accelerate these queries, we use the proxy scores to rank records of interest. In particular, we train a proxy model to estimate the quantities of interest (e.g., the number of cars in a frame) and rank by these scores. We find that even if such events are particularly rare, proxy models can have high precision among the top ranked data records.
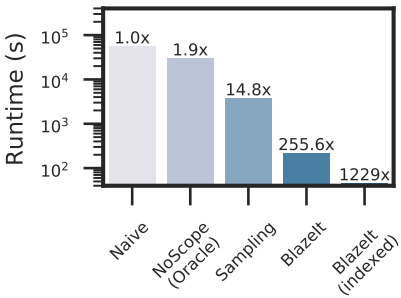
We show the performance of our algorithms (with and without the proxy model cached) and baselines in the plot below. As with approximate aggregation, our algorithm can strongly outperform the naive method and random sampling for cardinality-limited selection for rare events.
Conclusion
Queries over unstructured data are increasingly becoming feasible due to advances in machine learning. However, due to the high costs of deploying oracle methods, executing such queries can be prohibitively expensive. We’ve described methods of using proxy scores to accelerate aggregation and limit queries in this blog post, which we hope will begin to enable queries over unstructured data. In the next blog post, we’ll describe how to execute approximate selection queries with statistical guarantees.