Accelerating Queries over Unstructured Data with ML, Part 3 (Preprocessing-aware Optimizations for Visual Analytics)
In this blog post, we’ll describe our recent work on benchmarking recent progress on deep neural network (DNN) execution and optimizing end-to-end DNN inference for visual DNNs. While this blog post will be self-contained, please see our other blog posts (part 1, part 2) for other exciting developments and more context!
DNNs now power a range of visual analytics applications because they can produce high quality annotations over visual data. However, they can cost billions of float-point operations to execute or more, so systems designers have proposed a range of optimizations to reduce the cost of DNN execution. These optimizations span the range of more efficient DNN hardware, better compilers, and proxy models, which are cheap approximations to expensive target DNNs. In particular, several of these optimizations use the key fact that there is a fundamental tradeoff between accuracy and throughput. Due to extensive work by systems builders, the cost of DNN execution has dropped orders of magnitude.
Unfortunately, this work ignores a key bottleneck in end-to-end DNN inference: the preprocessing of visual data, in which visual data is decoded, transformed, and transferred to the DNN accelerator. As we show below, the preprocessing of visual data can bottleneck even for ResNet-50, which has historically been considered expensive (we describe the full hardware setup in the following section). Just the decoding of visual data can bottleneck ResNet-50. For batch analytics tasks, where preprocessing and DNN execution can be pipelined, this results in throughputs that are limited by preprocessing of visual data.
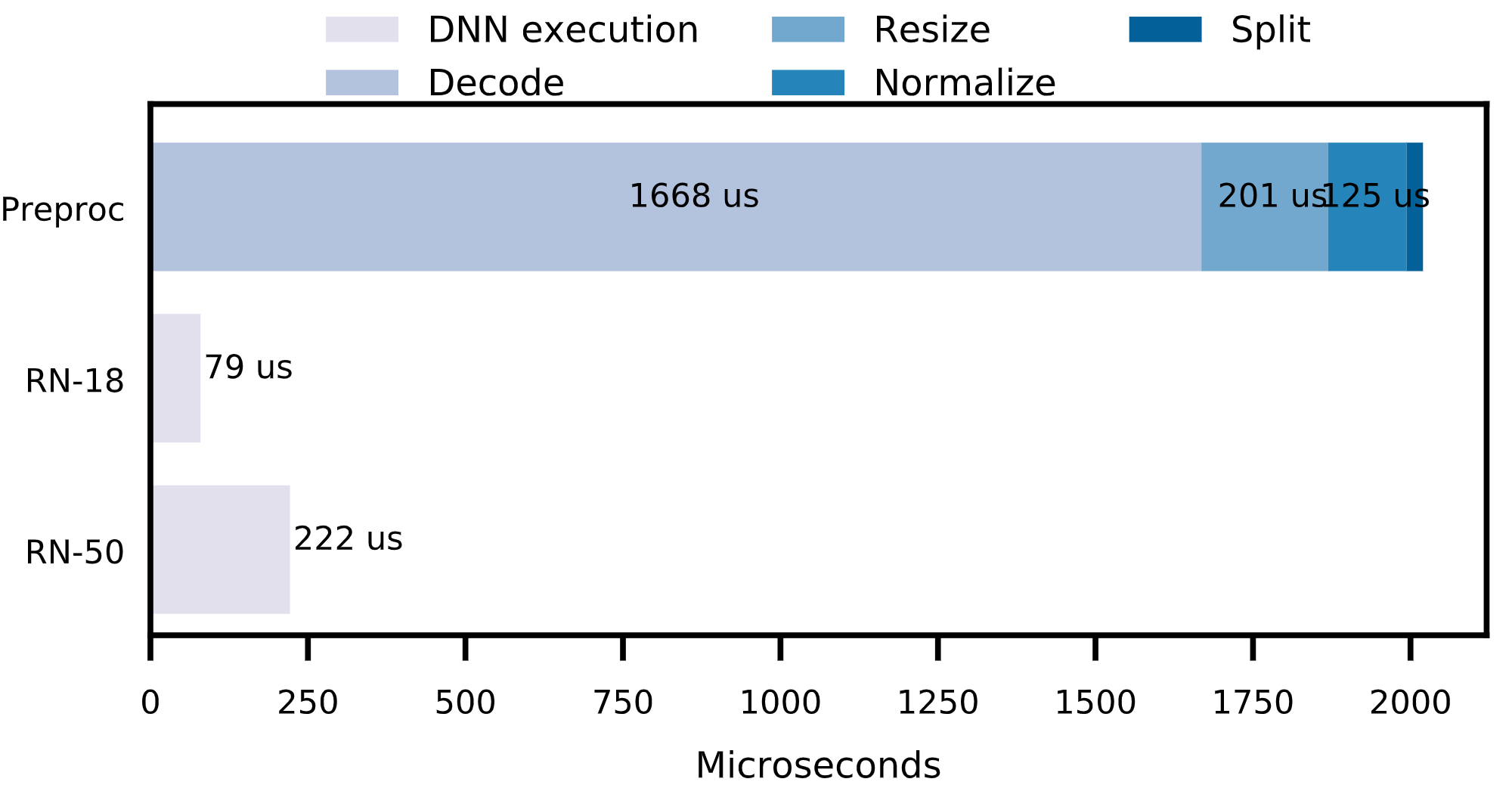
To address the bottleneck of preprocessing, we built Smol, a system that optimizes end-to-end DNN inference, improving throughputs by as much as 5.9x. Smol leverages low resolution visual data and partial decoding of visual data to increase the throughput of preprocessing, which improves overall throughput. We also describe corrected cost models to better select proxy models for visual analytics tasks. Smol can be directly integrated into existing systems, such as NoScope or BlazeIt, to produce end-to-end speedups.
Benchmarking End-to-End DNN Inference
DNN execution has historically been considered expensive, which has prompted a race to create better DNN accelerators, compilers, and analytics methods. Because DNN execution has been historically expensive, much of this work only focuses on DNN execution and ignores preprocessing. As we’ll show, these trends have reversed. Throughout, we benchmark on the g4dn.xlarge instance CPU types and a variety of DNN accelerators.
We first benchmarked ResNet-50 inference throughput on the NVIDIA K80, P100, T4, and V100 GPUs. We also show the reported throughput for the newly released NVIDIA A100 GPU. As we can see, ResNet-50 inference throughput has dramatically improved 150x in just the span of 6 years! We expect these trends to continue, as more efficient accelerators are released.
| Accelerator | Release Date | Throughput (images / second) |
|---|---|---|
| K80 | 2014 | 159 |
| P100 | 2016 | 1,955 |
| T4 | 2019 | 4,513 |
| V100 | 2017 | 7,151 |
| A100 | 2020 | 23,973 |
Throughput of ResNet-50 on different accelerators. The T4 is inference-optimized and substantially more power efficient than the V100.
We also show the effect of the DNN compiler on the throughput by showing the throughput of ResNet-50 on the T4 using Keras, PyTorch, and TensorRT. We use the T4 as it is a widely available, inference-optimized accelerator. Similar to how more efficient accelerators have dramatically improved throughput, using inference-optimized DNN compilers also substantially improves throughput.
| Framework | Throughput (images / second) |
|---|---|
| Keras | 243 |
| PyTorch | 424 |
| TensorRT | 4,513 |
Throughput of ResNet-50 with different DNN compilers/frameworks on the inference-optimized T4 accelerator.
Finally, we benchmark the throughput of preprocessing visual data. We use the standard ResNet-50 preprocessing steps, which consists of: 1) decoding a JPEG compressed image, 2) resizing the image, 3) normalizing the image, and 4) rearranging the pixels to channels first. We show the latency of the preprocessing steps when using optimized C++ code parallelized across the vCPUs and the latency of ResNet-50 on the g4dn.xlarge instance. These results show that preprocessing is now the overwhelming bottleneck in end-to-end DNN inference!
We expect the trends of more efficient systems to continue, so these we foresee the bottleneck of preprocessing to only grow larger. For example, the recently released A100 GPU achieves far higher throughput than the T4. Finally, we defer a discussion of increasing the number of vCPUs to the full paper.
Optimizing End-to-End DNN inference
To address the bottleneck of preprocessing, we built Smol, which leverages three techniques to optimize end-to-end DNN-based visual analytics applications.
Low-resolution visual data
Smol first leverages low-resolution visual data, which is often natively present in applications as thumbnails or low-resolution videos. For example, Instagram stores thumbnails of images and YouTube has a variety of resolutions for variable bandwidth scenarios. Since decoding is the most expensive preprocessing step, decoding low-resolution visual data substantially reduces the cost of preprocessing.
However, naively using low resolution visual data can harm accuracy by up to 10% (see the chart below). To recover accuracy, we use data augmentation. Given a fully trained model, we fine-tune with data that is first downsampled to the appropriate resolution, then upsampled. This fine-tuning can fully recover accuracy in certain scenarios and is also more computationally efficient than training on low-resolution visual data from scratch.
Partial decoding
Smol also leverages partial decoding of visual data where possible. Many applications only require a fraction of the image. For example, standard classification models use central crops and positional visual queries may only require, e.g., the left side of a video.
If an application only requires a portion of the visual data, Smol will decode the smallest possible portion of the visual data possible, given the encoding format. For example, JPEG compression allows specific “macroblocks” (8x8 blocks of pixels) to be decoded independently. By only decoding the necessary parts of the image, Smol can reduce the amount of preprocessing computation, improving throughputs.
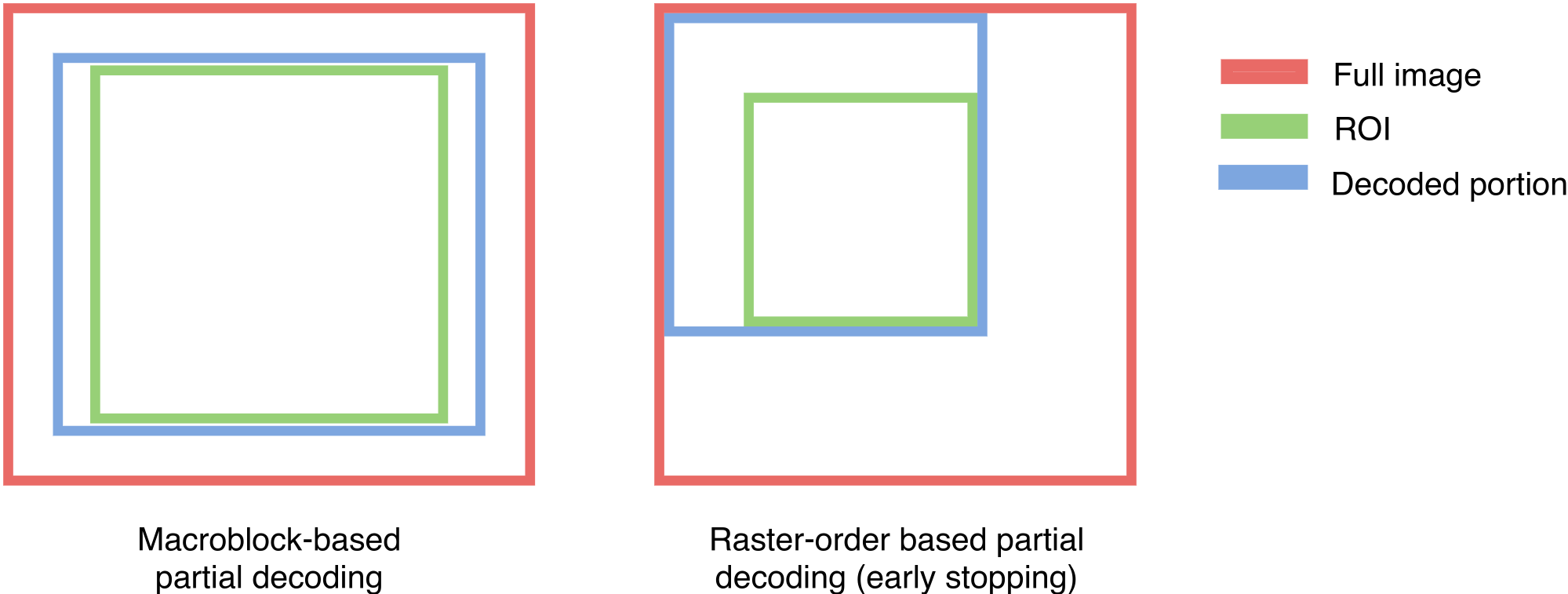
Selecting proxy models
Prior work on visual analytics uses what are known as proxy models to improve throughput of visual analytics queries. Proxy models are approximations of more expensive target DNNs: as proxy models are more accurate, they can accelerate queries more efficiently. Please see our other blog posts (part 1, part 2) to understand how proxy models are used to accelerate visual analytics queries.
A key component in selecting proxy models is to approximate the relative cost of executing the proxy model compared to the relative gain query execution speeds. To select these proxy models, prior work has used cost models to approximate the cost of executing a proxy model. These cost models either ignore the cost of preprocessing or ignore that preprocessing can be pipelined with DNN execution. As a result, these cost models select proxy models that are far more efficient than preprocessing costs, but this speed trades off against proxy model accuracy.
In contrast Smol, more accurately accounts for preprocessing costs. As a result, Smol will select more expensive models that are consequently more accurate. This accuracy will then translate to faster queries.
Results
By combining these techniques, Smol can dramatically improve throughputs, by up to 5.9x at a fixed accuracy. We show the Pareto frontier of accuracy and throughput on the ImageNet dataset (and 3 others) for standard ResNet models and Smol. As we can see, all standard ResNet models are bottlenecked by preprocessing, but Smol can alleviate this bottleneck.
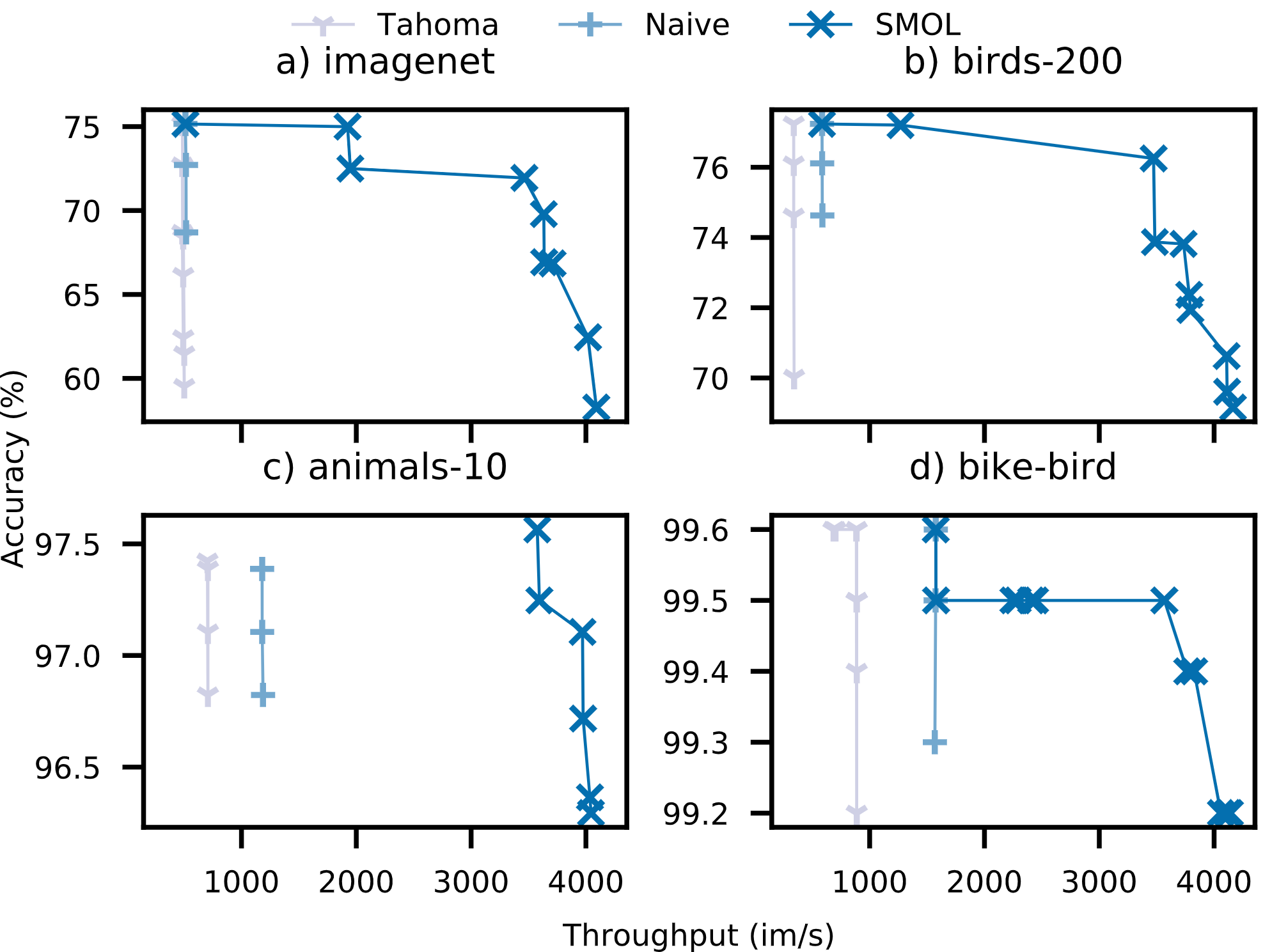
Conclusion
In this blog post, we’ve shown that DNN execution is no longer the bottleneck for many applications, causing the preprocessing of the data to be the bottleneck. We also described techniques to alleviate the bottleneck of preprocessing, which results in up to 5.9x improvements in throughput. Our paper will be forthcoming in VLDB 2021, with a preprint available here. Stay tuned for the open-source release of our code!