Model Assertions as a Tool for Quality Assurance and Improving ML Models
Machine learning is increasingly being used in real-world domains, such as self driving cars or healthcare. However, ML models can fail in confusing or complicated ways. For example, autonomous vehicles have suffered multiple incidents where they accelerated into one type of highway lane divider. We believe it is critical to develop tools for ensure model quality and to improve models over time, especially as ML is deployed in mission-critical domains.
Prior work on quality assurance for machine learning has focused on training data validation/cleaning [1], [2], [3], [4], [5] , training data visualization [1], [2] , and formal verification [1], [2] .
In this blog post, we report our work on adapting software assertions for monitoring deployed ML models and collecting data to improve ML models. In contrast to prior work, model assertions allow domain experts to specify structural constraints over the output of models, without needing to understand the internals of an ML model.
Similar to ML, traditional software can be complex and difficult to reason about, but has been successfully deployed in mission critical settings, ranging from medical devices to spaceships. These successful deployments are, in part, due to rigorous quality assurance tools - including assertions, unit tests, fuzzing, and regression tests. We propose model assertions, an extension of assertions to ML applications. We show how this concept can be used in powerful ways, both for monitoring models at deployment time, and for improving models at training time.
Introducing Model Assertions
Model assertions adapt traditional program assertions for use in ML deployment.
Traditional program assertions (e.g., assert(len(array) > 0)) are used to check invariants about program state.
They are used as a first line of defense in traditional software and
can significantly reduce the number of
bugs.
In contrast, model assertions allow domain experts to specify constraints over the inputs and
outputs of machine learning models.
Similar to how assertions are used in software engineering, model assertions can be used for monitoring purposes.
In addition, we propose several ways to use assertions in ML contexts that allow them to help improve model accuracy, with active learning
[1],
[2]
and weak supervision
[1],
[2],
[3]
.
Example
In video analytics, users might run pretrained object detection models (such as SSD) to identify entities such as cars. One common problem with these models is flickering, where the model may see objects that disappear in between consecutive frames, leading to clearly incorrect results. The video example below demonstrates the problem, where we ran a pretrained SSD on footage from a security camera. The bounding box surrounding the car flickers in and out between consecutive frames:

Although the model’s internals are complex, a simple assertion over the output of the model could easily detect this error. Object detection models output a list of bounding boxes at each frame. If there is a car bounding box at frame n, the assertion would need to check whether, if the box was present in any of the recent frames, if there were any gaps in the predictions. The following pseudocode, written in Python, shows how to check for the incorrect flickering behavior programmatically:
cur_boxes = boxes(cur_frame)
for i in range(cur_frame - 1, cur_frame - 10):
similar_boxes = get_similar_cars(cur_boxes, boxes(i))
if len(similar_cars) == 0: # no similar boxes, check for flickering
for j in range(i-1, cur_frame - 10):
overlapping_boxes = get_similar_cars(cur_boxes, boxes(j))
if len(overlapping_boxes) == 0: # car doesn't appear in this frame either
continue
else: # car appeared in some, but not all of the previous frames
raise FlickerException
else:
cur_boxes = similar_boxes
We implemented this flickering check within a prototype assertion system for video analytics. In addition to identifying flickering, we wrote assertions that checked for other incorrect behavior, such as multiple objects overlapping or being nested with each other in an incorrect way.
Using Model Assertions
We explore four ways to use model assertions at runtime and training time:
-
Runtime Monitoring: Model assertions can be used in an analytics pipeline to collect statistics on incorrect behavior, to identify classes of errors where models make mistakes.
-
Corrective action: At runtime, if a model assertion fires, it can trigger a corrective action, such as returning control to a human operator.
-
Active Learning: Assertions can find inputs that cause the model to fail. The analyst could take the frames that trigger the flickering assertion, send them to a human for relabeling, and then retrain the model with these frames.
-
Weak Supervision: If access to human labelers is expensive, assertions could be associated with simple automatic corrective rules, that automatically relabel the incorrect model outputs. For flickering, a corrective rule could fill in the location of the missing bounding box by interpolating between the bounding boxes in the adjacent frames, as pictured below. These automatically labeled frames could then be used to retrain the model.

Bottom Row: A simple automatic correction rule might fill in the location of the missing bounding box using the bounding boxes in the adjacent frames.
Improving Model Quality with Assertions
We evaluate the effectiveness of using assertions, such as the ones discussed earlier, to improve object detection models for video analytics using active learning and weak supervision. For a more complete evaluation of our results, where we also discuss the accuracy of assertions, please see our workshop paper.
The dataset contains several days of video from a security camera of a traffic intersection in Wyoming. To evaluate model assertions, we retrain SSD, pretrained on MS-COCO, using assertions. We evaluate the accuracy of the retrained models to the baseline pretrained model by comparing to ground truth labels from a more accurate model, Mask-RCNN.
We first ran the pretrained model on one day of video as our baseline. We then ran the flickering and multibox assertion over these outputs to catch the frames that triggered these mistakes. For the active learning experiments, we relabeled these frames using the ground truth data. For the weak supervision experiment, we constructed a corrective rule for flickering that interpolates the location of missing bounding boxes from adjacent frames, and relabeled the incorrect frames with this rule. We then improved the baseline model by retraining with these relabeled frames.
Quantitative Improvements
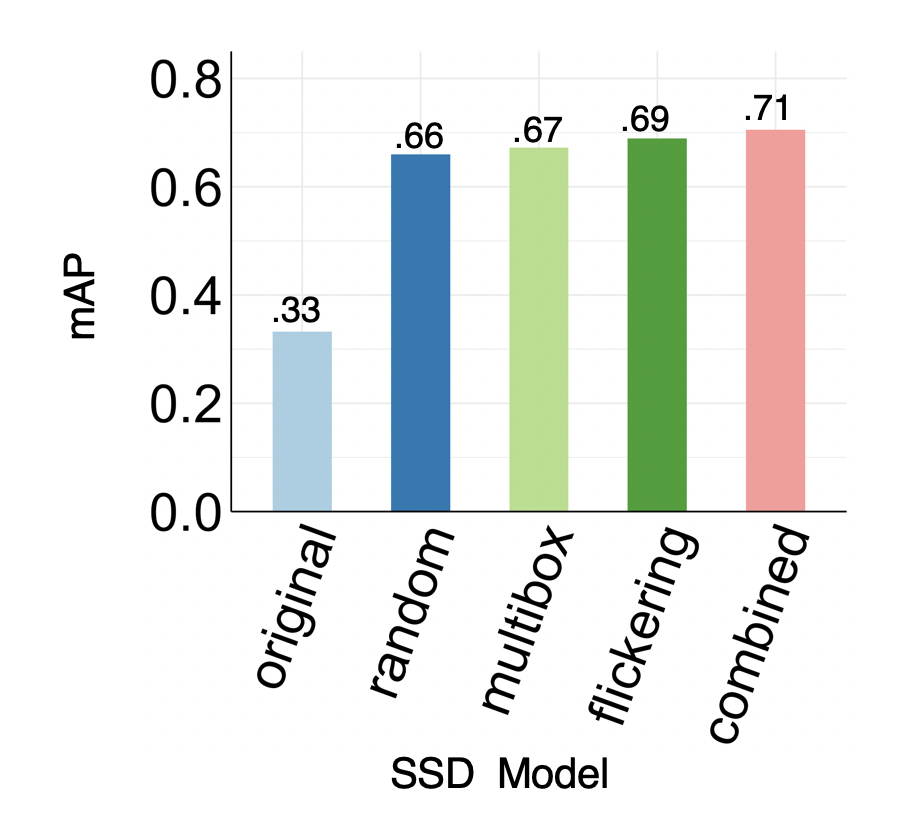
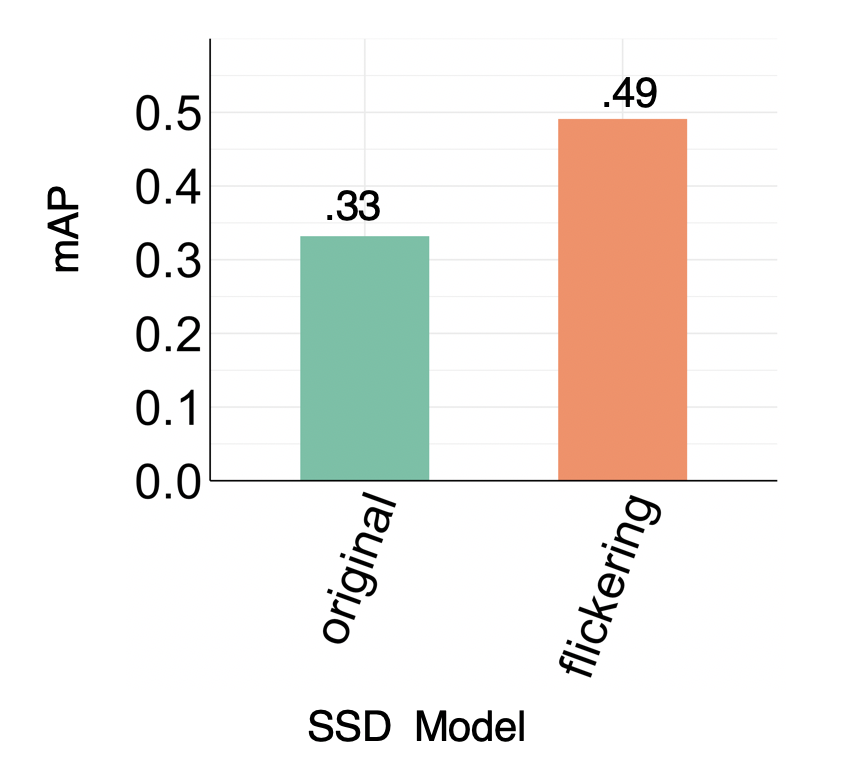
The two graphs below show the improvement of model accuracy via active learning and weak supervision. The baseline model achieves .33 in mAP, which is a precision metric commonly used to judge object detection models.
Active learning: For active learning, we also compare against retraining with randomly sampled frames as a simple baseline. We find that retraining with frames that triggered each assertion individually and with both assertions combined can yield large improvements in mAP over the pretrained model and the random baseline.
Weak Supervision: When access to ground truth labels is expensive, using the flickering assertion, along with the associated corrective rule, to retrain the model can also yield improvements in mAP.
Qualitative Improvements
The two videos below show the baseline pretrained model (left) and the best retrained model, the model retrained via active learning with both assertions (right), labeling a segment of the video. We observe that the retrained model makes fewer mistakes; it does not yield predictions that flicker or contain incorrectly overlapping bounding boxes (from the multibox assertion, mentioned above).
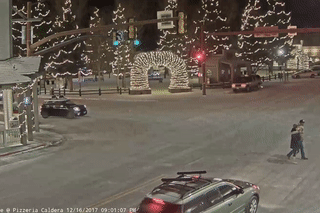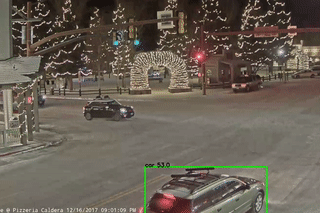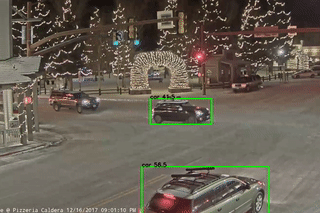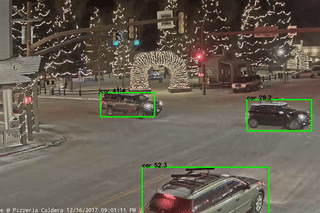

Help us Test Model Assertions!
The early results with model assertions on video are promising, but we’re really interested in testing this technique at larger scale on meaningful ML problems. If you face model quality assurance problems or need to improve your ML models and would like to try model assertions, or just to tell us what kind of problems you see, we’d love to hear from you. Please shoot us an email at modelassertions@cs.stanford.edu!