Selection via Proxy: Efficient Data Selection for Deep Learning
Given massive amounts of data available to train deep networks for many tasks, how can we quickly determine which data should actually be used in training? Data selection methods like active learning and core-set selection techniques are powerful ways to curate data for training, but these approaches can be computationally expensive and struggle to scale.
In recent work at ICLR 2020, we show how to speed up data selection by up to 41.9x: we use a small, less accurate model as an inexpensive proxy for a larger target model to select “hard” data points for training. Even though these proxy models are less accurate, we find they select high-quality data that doesn’t significantly impact the accuracy of the final model (often within 0.1%). Also, we find a proxy can remove over 50% of the CIFAR-10 training data without impacting the accuracy of ResNet-164, resulting in a 40% speed-up in end-to-end training time.
We published a paper on this “selection via proxy” (SVP) approach at ICLR 2020, and code is available on Github.
Intuition: Model architectures rank examples similarly
At a high-level, data selection methods use an iterative process that involves 3 steps:
- Ranking examples based on some measure of informativeness (e.g., entropy)
- Selecting the highest ranking example or examples
- Updating the model based on selected examples
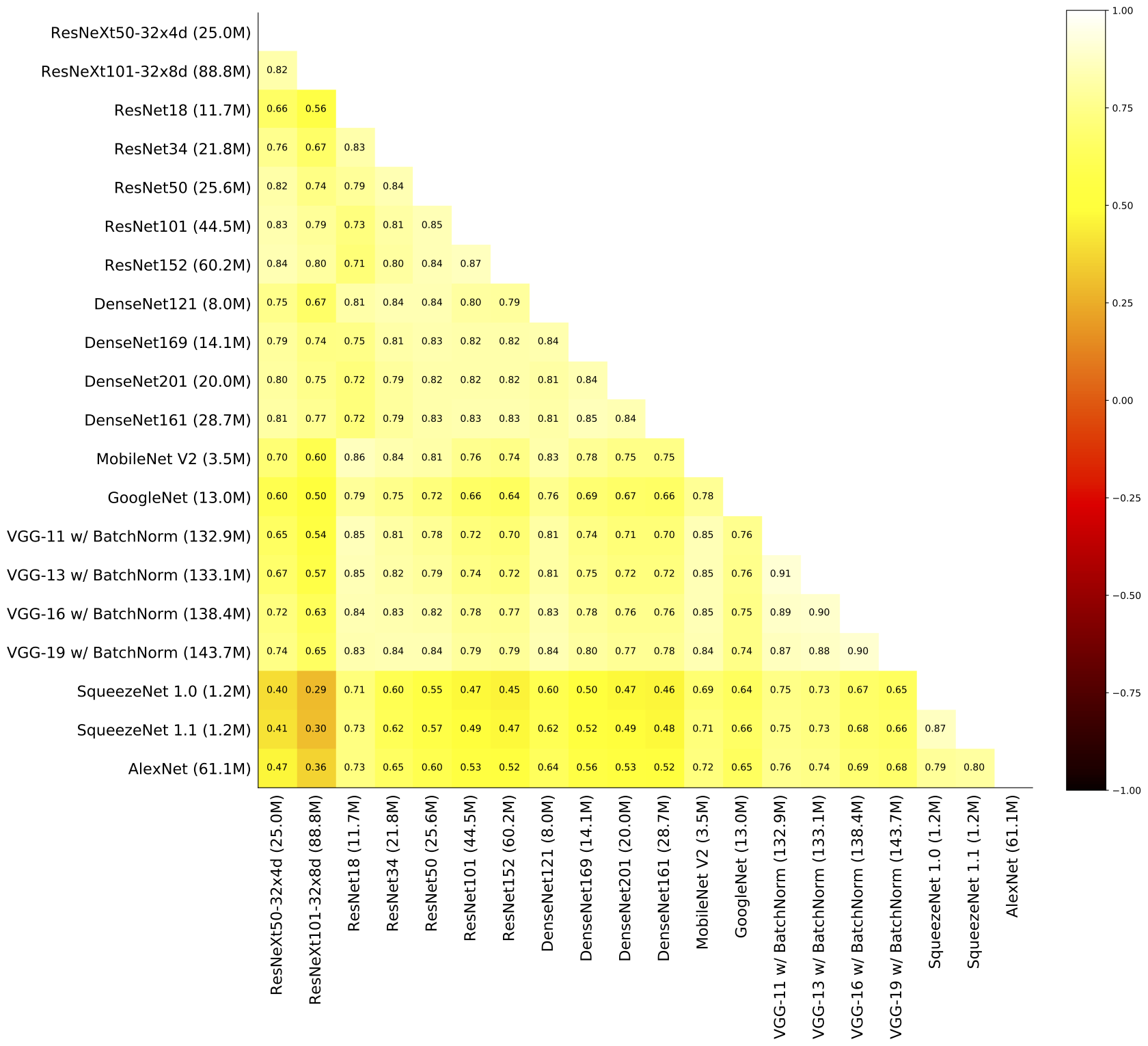
This third step is a major bottleneck in deep learning. Models can take hours or days to train, so it’s not cost effective to retrain the model for each example we select. Our key insight behind SVP is that while larger models are more accurate, they rank and select similar examples as smaller, less accurate models. For example, the figure shows the degree of correlation between many different models from similar architectures. We can exploit these high correlations to create proxies that speed up data selection by an order of magnitude.
Creating Efficient and Useful Proxies
We explored two main methods to create our proxy models:
- Scaling down. For deep models with many layers, we can reduce the dimension or the number of hidden layers as an easy way to trade-off accuracy to reduce training time. For example, a ResNet20 model achieves a top-1 error of 7.6% on CIFAR10 in 26 minutes, while a larger ResNet164 model takes 4 hours and reduces error by 2.5%.
- Training for fewer epochs. During training, most of the time is spent on achieving a relatively small reduction in error. For example, while training ResNet20, almost half of the training time (i.e., 12 minutes out of 26 minutes) is spent on a 1.4% improvement in test error. Based on this observation, we also explored training proxy models for a smaller number of epochs to get good approximations of the decision boundary of the target model even faster.
Results
To evaluate the impact of SVP on data selection runtime and quality, we applied SVP to data selection methods from active learning and core-set selection on five datasets: CIFAR10, CIFAR100, ImageNet, Amazon Review Polarity, and Amazon Review Full. For active learning, SVP achieved similar or higher accuracy across dataset and labeling budgets with up to a 41.9x improvement in data selection runtime:
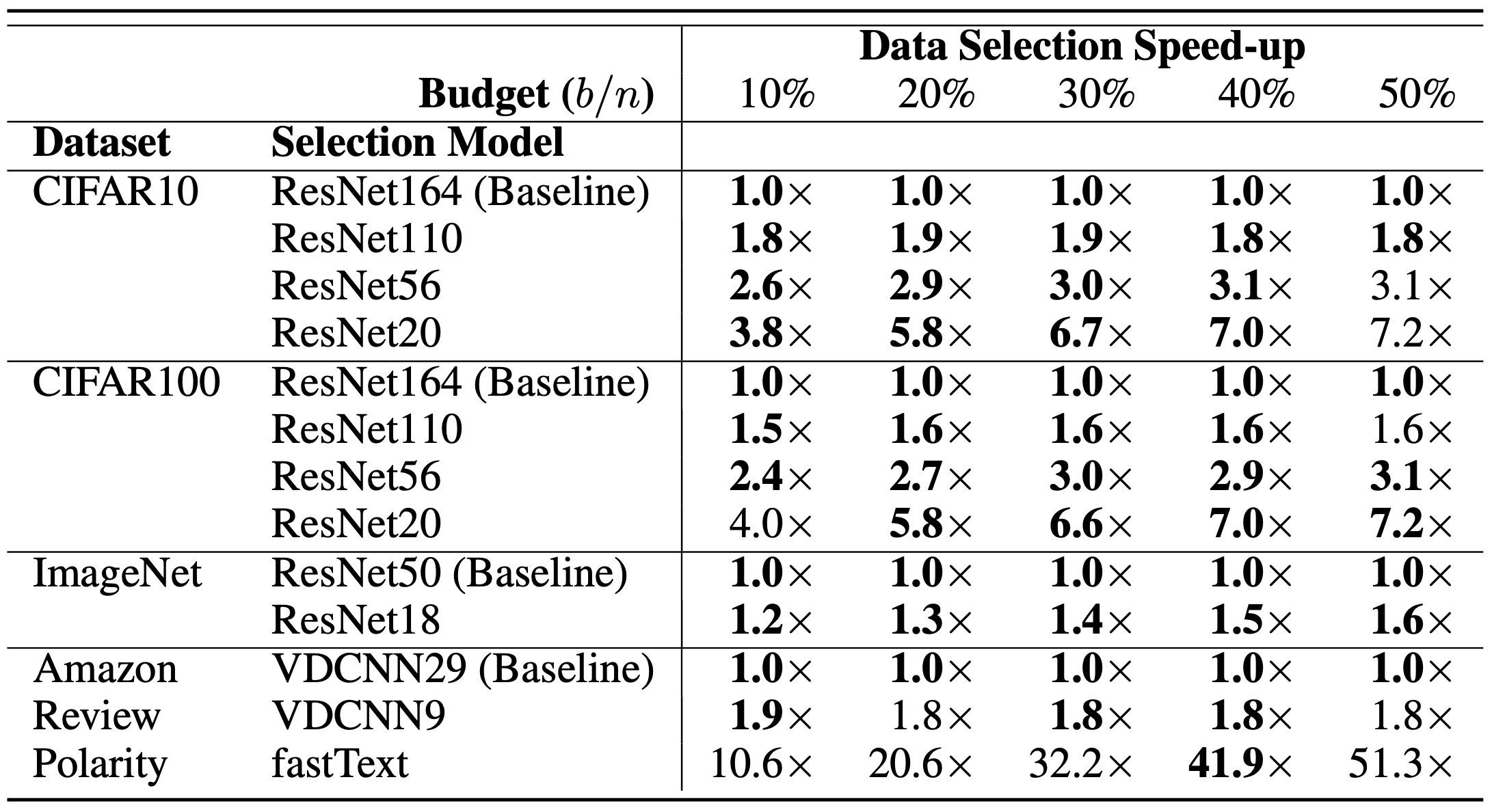
For core-set selection, proxy models performed nearly as well as or better than the target model at selecting a subset of data that maintained high accuracy.
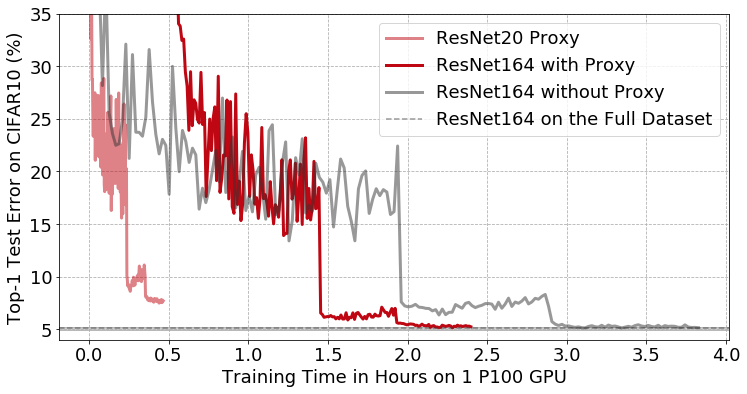
On CIFAR10 in particular, a small proxy model removed 50% of the data without affecting the final accuracy of a much larger, more accurate model trained on the subset. Moreover, the entire process of training the proxy on all the data, selecting which examples to keep, and training the target model on the subset only took 2 hours and 23 minutes, giving a 1.6x end-to-end speed-up over the standard approach of training the target model over the full dataset, as shown below:
Summary
Selection via proxy (SVP) can improve the computational efficiency of active learning and core-set selection in deep learning by substituting a cheaper proxy model’s representation for an expensive model’s during data selection. Applied to active learning, SVP achieves up to a 41.9x improvement in data selection runtime with no significant increase in error (often within 0.1%). For core-set selection, we find that SVP can remove up to 50% of the data from CIFAR10 in 10x less time than it takes to train the target model, achieving a 1.6x speed-up in end-to-end training.