Why Train What You Can Code? Rekall: A Compositional Approach to Video Analysis
Many real-world video analysis applications require the ability to identify domain-specific events in video, such as interviews and commercials in TV news broadcasts, or action sequences in film. Pre-trained models to detect all events of interest often do not exist, and training new models from scratch can be costly and labor-intensive. In this blog post, we discuss an alternative approach to specifying new events in video: by writing queries that compose the outputs of existing, pre-trained models using a new programming model for video analysis called Rekall.
Research is ongoing; check out our paper on arXiv for more details, the Rekall repository on GitHub for tutorials and examples, and our website for demo videos.
Real-World Video Analysis Requires Detecting Domain-Specific Events
Modern machine learning techniques can robustly annotate large video collections with basic information such as face positions and identities, people/object locations, time-aligned transcripts, and more. However, real-world video analysis applications often require exploring and detecting domain-specific events. For example, our recent efforts to analyze cable TV news broadcasts required models to detect interview segments and commercials. A film production team may wish to quickly find common segments such as action sequences to put into a movie trailer. An autonomous vehicle development team may wish to mine video collections for events like traffic light changes or obstructed left turns to debug the car’s prediction and control systems.




The standard machine learning approach to detecting these new events would be to gather a large amount of training data, and train a new model (probably a deep network) to detect each new event. But this can be expensive – collecting training data is labor-intensive, and training accurate models can require significant compute, time, and human skill.
From conversations with practitioners in industry and academia, along with our own experiences analyzing the past decade of cable TV news and the past century of Hollywood film in an ongoing research project, we realized that it is increasingly important to enable much more agile video analysis workflows. We want to enable an analyst to come up with an event they want to detect in the morning and be exploring a result set by the afternoon.
To achieve these goals, we’ve been working on a system at Stanford that embraces a more traditional approach to specifying events of interest in video: by using queries that programmatically compose the outputs of existing, pre-trained models. This approach hearkens back to computer vision systems pre-deep learning – when heuristics-based model design was the common case. In this project, we wanted to look back on these techniques and adapt them to the modern learning landscape, where off-the-shelf computer vision models give you the ability to annotate videos with meaningful semantic information. We believe that in this landscape, programmatic compositions can be an effective way to encode domain knowledge.
To explore this approach, we developed Rekall, a library that exposes a data model and programming model for compositional video event specification. Writing Rekall queries does not require additional model training and is cheap to evaluate, so analysts can immediately inspect query results and iteratively refine the queries to describe desired events.
Rekall queries have helped drive video analysis tasks in a number of application domains, from media bias studies on TV news and film to analysis of vehicle data. In these efforts, users were able to quickly write Rekall queries to detect new events (often in a single afternoon). These queries were often competitive with ML models – read on to see how Rekall enables rapid video analysis!
An Analysis Example: Interview Detection
Problem Setup
Let’s consider a task from our own experiences doing video analysis as a running example. In a recent project at Stanford, we had a need to identify interviews of major political candidates in a large corpus of cable TV news video, to help understand sources of bias in coverage. We didn’t have access to a pre-trained model for interview detection, so we needed some way of creating a detector from scratch. However, we did have access to off-the-shelf face detection and identity models. We needed some way to bridge the gap.

How Rekall Helps
With Rekall, we started off by using face detection and identity models to locate and identify faces in the video. We used Rekall to ingest this data and then used it to detect interviews.
Next, we wrote Rekall queries to compose these annotations. We knew (from watching some TV) that interview segments in TV news broadcasts tend to feature shots containing faces of the candidate and the show’s host framed together, so our first try at an interview detector query searched for frames with the host and the guest together. But then we realized that interview segments also tend to cut away to shots of the candidate alone, so we refined the initial query by allowing for segments with the candidate shown alone. Further refinements could also ingest caption data from the video broadcasts and require parts of the detection to align with common frames like “welcome” and “thank you very much” (although we did not need to for our efforts).
Arriving at an accurate query for a dataset often requires multiple iterations of the analyst reviewing query results and modifying the query; Rekall’s programmatic interface allows rapid iteration and interpretable fine-tuning (in our experience, users can often write accurate Rekall queries in an afternoon). In contrast, the standard machine learning approach would be to gather a large amount of training data and train up new models (and possibly a new set of training data and a new model for each candidate).
Compositional Video Event Specification with Rekall
Let’s take a deeper dive into the data model and programming model that allowed us to write these queries.
Rekall’s Data Model
To write queries over video annotations from multiple modalities (image, audio, text, etc), Rekall adopts a unified representation for all data: a spatiotemporal label (or label). Each Rekall label is associated with a continuous, axis-aligned interval of spacetime (3D or N-D volumes) that locates the label in the video, and potentially additional metadata:
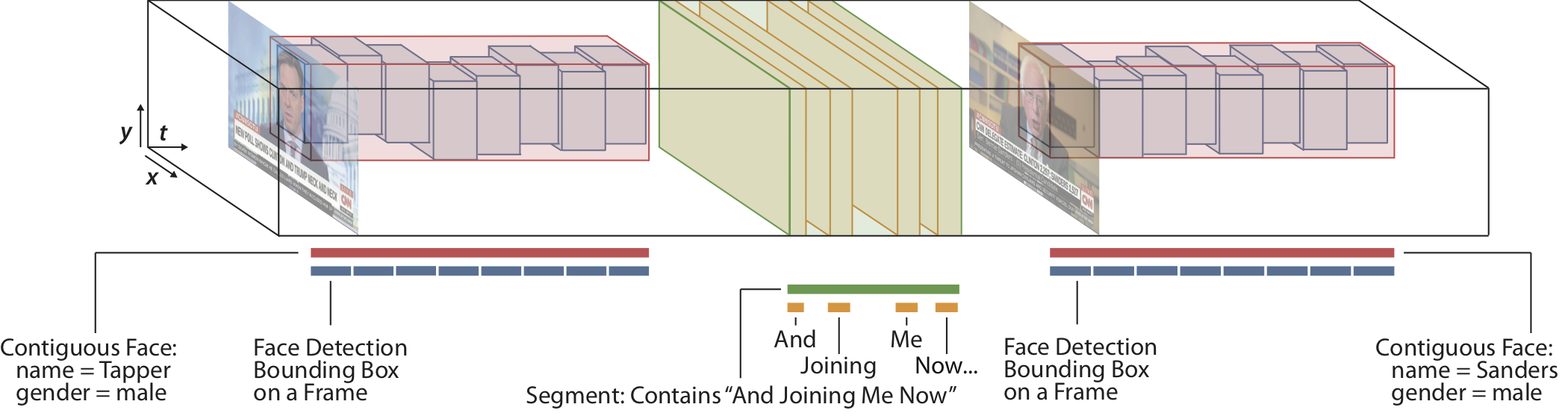
The above figure illustrates examples of labels generated for the interview detection task:
- Face detection performed on each frame yields labels (one per detected face, blue boxes) that span one frame of time.
- The results of time-aligning the video’s transcript yields a label per word that extends for the length of the utterance (with the word as metadata, yellow boxes).
- Rekall’s labels are often nested; for example, the red boxes indicate segments where anchor Jake Tapper or guest Bernie Sanders are on screen for some consecutive amount of time, and the green label corresponds to the phrase “And joining me now.” Rekall uses sets of these spatiotemporal labels to represent all occurrences of an event in a video.
Rekall’s Programming Model
Rekall queries use a series of operations that produce and consume sets of labels to define new events; for example, an interview detection query might start by loading up all face detections into a label set, and end by producing a label set containing every instance of an interview.
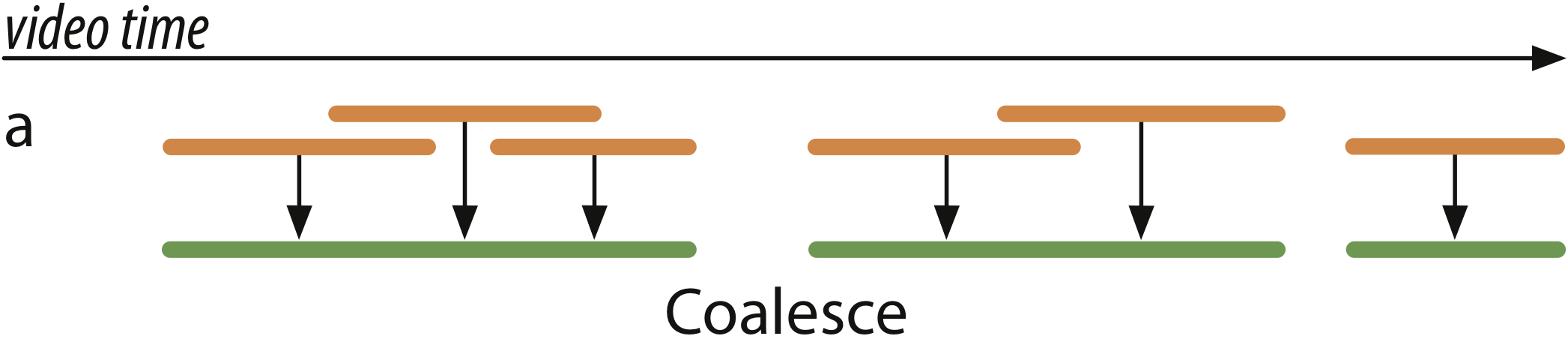
Rekall provides standard data-parallel operations like map, filter, and group_by to manipulate label sets. But many video analysis tasks involve reasoning about sequences of labels or spatially adjacent labels; Rekall’s coalesce operator serves to merge fine-grained labels in close proximity in time or space into new labels that correspond to higher-level concepts. coalesce recursively merges labels in an input set:
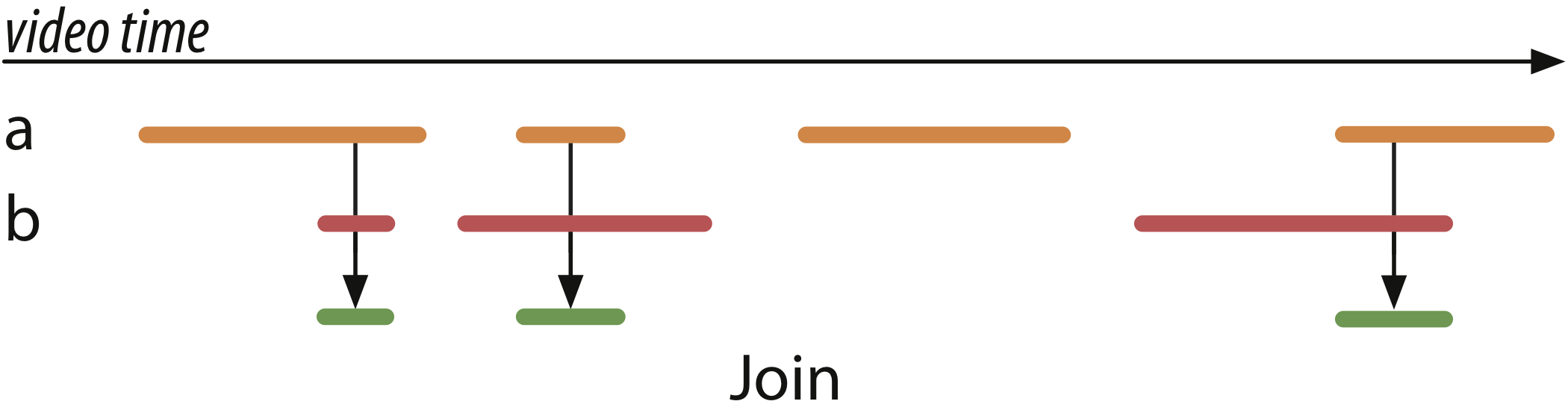
Video analysis tasks also often involve reasoning about multiple concurrent label streams; Rekall provides standard join operators to combine multiple streams together and construct new labels from spatiotemporal relationships between existing labels. Rekall’s inner join is parameterized by a join predicate and a label merge function that specifies how to merge matching pairs of labels. The below figure shows two label streams (orange and red), and a join operation that finds all the times when an event in orange and an event in red happen at the same time:
Finally, since Rekall is all about algebras over label sets, it also exposes a minus operation that takes two label sets and removes intervals associated with the labels in the second set from the intervals of labels in the first. Formally, this is known as an anti-semi-join. For a visual depiction:
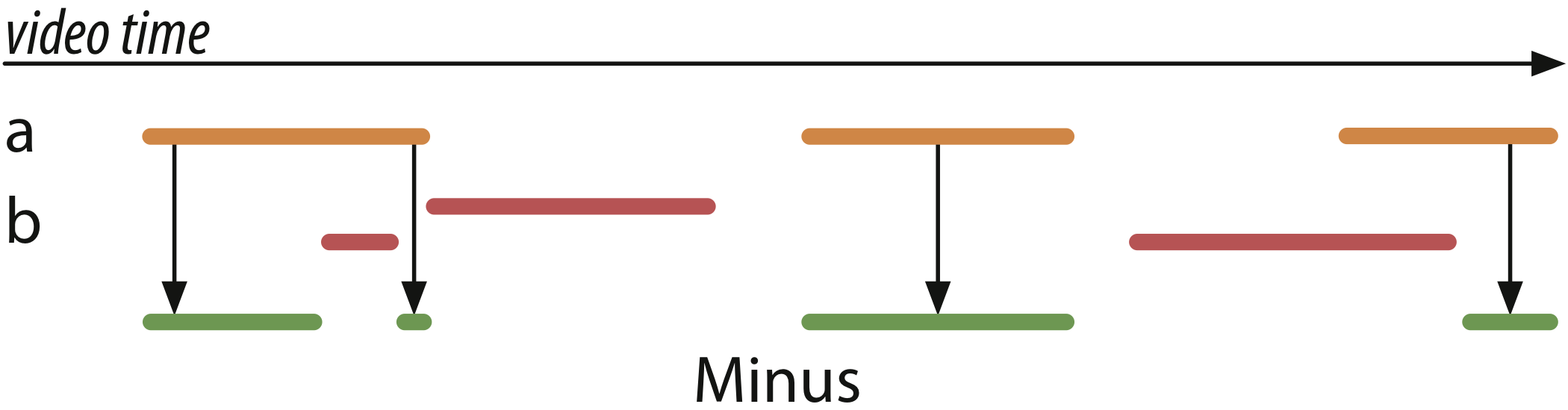
The result set (green) maximally covers the intervals in a (orange) without overlapping with any interval in b (red).
Those that are familiar with modern temporal data processing engines, like Microsoft Trill or complex event processing systems, might find many of these primitives familiar. This is very intentional - these communities can think about Rekall as adopting and extending these data stream analysis ideas to the spatiotemporal domain of video analysis.
Interview Detection, Reprise
Now that we’ve introduced Rekall’s data model and programming model, let’s bring it all together by returning to the interview detection query we described before. Here’s a code listing and visual depiction that uses Rekall’s composition operations to detect interviews between Bernie Sanders and Jake Tapper (just using face detections and identities):

- The query starts by loading up pre-computed face detections from an off-the-shelf face detector (line 1, blue squares).
- Then it uses
filter(lines 3, 11) andcoalesce(lines 6, 14) to get contiguous segments of time where Bernie Sanders or Jake Tapper is on screen. Note that thecoalesceoperations purposefully cover small gaps where someone is not detected; this both serves to smooth over errors in the face detector, and include segments where the interview cuts away to B-roll footage (in this case, the interview cut away to an SNL clip). - Next the query uses a
joinoperation (line 19) to get segments where Bernie Sanders and Jake Tapper are on screen together, and aminusoperation (line 25) to get segments where Bernie Sanders is on screen alone. - The query ends with one last
join(line 28) and acoalesceoperation (line 34) to get sequences where Bernie Sanders and Jake Tapper are shown together on screen, before or after Bernie Sanders is shown alone.
The final algorithm is only 34 lines of code – but it took domain knowledge and query iteration to get there. We started by using our domain knowledge about what an interview looks like to write an initial query, and then inspected query results and iterated towards a good solution. In contrast to the traditional learning pipeline, Rekall queries are interpretable, and query evaluation is fast enough to enable interactive iterations – which are both important for enabling more agile video analysis workflows!
As Good as Deep Learning Models in Label-Poor Regimes
We have written Rekall queries for video analysis tasks such as media bias studies of cable TV news broadcasts, analysis of cinematography studies in feature-length films, event detection in static-camera vehicular video streams, and data mining the contents of commercial autonomous vehicle logs.
We evaluated a number of these queries against learned approaches by annotating a small amount of ground truth data (ranging from dozens of minutes to hours, depending on labeling effort required) and training various deep networks on ground truth annotations (withholding part of the ground truth data for a test set). We intended these comparisons to represent a “reasonable-effort” learned solutions that follow common practice; it’s likely that a machine learning expert, given sufficient time to collect more training data and try out different architectures, could achieve better results.
But in an exploratory, label-poor regime, Rekall queries often matched or outperformed the accuracies of learned approaches (F1 scores for the top tasks, mAP for bottom task; we report results from five random-weight initializations for the learned approaches):
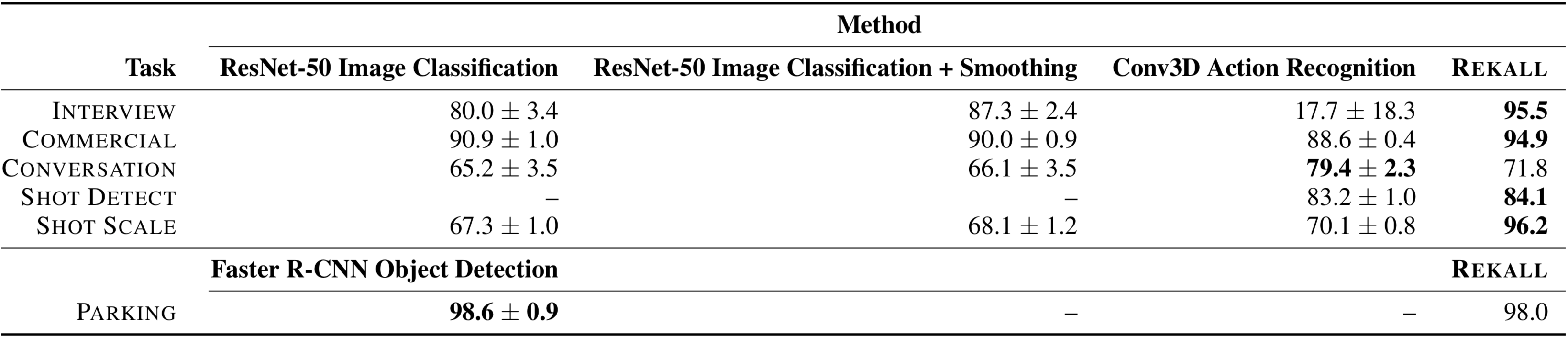
Critically, many of these Rekall queries were written by domain experts who had no previous experience using Rekall, in programming efforts that ranged from an afternoon to two days (time to learn how to use Rekall). In other words, Rekall enabled domain experts to quickly build accurate models by encoding their domain knowledge as queries.
For more details on other Rekall queries we’ve written and our evaluation methodology, check out our paper!
Demo: Mining Clips for a Film Trailer
We’ve just shown that Rekall queries can be pretty accurate, but they are also very helpful when you’re just trying to get back any reasonable result quickly from a rough query. As a cool example, consider this viral YouTube video presenting a template for how to make a Blockbuster film trailer – this template points out some common tropes in movie trailers, like hero shots of the main characters, VFX shots, and “statements of fatalism” from the main villain. When we first saw this trailer template, we thought it might be possible to search for clips for each item of the template using Rekall queries. Using Rekall, you can quickly hack up queries that embody these concepts, because given your domain knowledge you can translate those high-level concepts into compositional queries:

If you look at the above queries, they’re not terribly “accurate” by traditional metrics – not every frame with a main character whose face is a certain height will be a hero shot, for example. But if you look at the results and show them to a human, it turns out you can pick out a few clips that actually are hero shots. Rekall enabled us to take some simple intuition about how to extract the main events in the trailer template, and encode them in simple queries. When we started putting some of these clips together with some music, we were able to get something that starts to resemble a trailer (for context, this entire trailer was thrown together in about four hours for a class project):
To Conclude, the Bigger Picture
In this blog post, we’ve discussed manual composition of the outputs of pre-trained models using Rekall as an approach for rapidly detecting new events in video. Of course, the notion of authoring code in a domain-specific query language is not new, but adopting this approach for video analysis contrasts with current trends in modern machine learning, which pursue advances in video event detection through end-to-end learning from raw data (e.g. pixels, audio, text). We’ve seen that Rekall allows users to rapidly build accurate queries to find new events in video without incurring the costs of large-scale human annotation and model training. These queries allow users to express domain knowledge (via programming), and in an exploratory, data-poor regime, these queries can often be more accurate than learned approaches.
We believe productive systems for compositional video event specification stand to play an important role in the development of traditional machine learning pipelines, and we are excited to continue exploring the relationship between programmatic composition and learning. In our paper, we discuss examples where machine learning engineers use Rekall queries to surface training examples to focus human labeler effort on important situations, and to search for anomalous model outputs (potentially feeding active learning loops). We are also excited about connections to weak supervision; how can Rekall queries be used to bootstrap model training? We hope that our experiences encourage the community to explore techniques that allow video analysis efforts to more effectively utilize human domain expertise and more seamlessly provide solutions that move along a spectrum between traditional query programs and learned models.