Powerful Abstractions for Programming Your Training Data
Using standard models (i.e. pretrained BERT) and minimal tuning, we leverage key abstractions for programmatically building and managing training data to achieve a state-of-the-art result on SuperGLUE—a a newly curated benchmark with six tasks for evaluating “general-purpose language understanding technologies.”1 We also give updates on Snorkel’s use in the real world with even more applications—from industrial scale at Google in Snorkel Drybell to scientific work in MRI classification and automated Genome-wide association study (GWAS) curation (both accepted in Nature Comms)!
Motivation
Programming abstractions in machine learning are changing: practitioners are spending less time on architectures and hardware optimizations and, instead, focusing on training data. In this post, we describe three powerful abstractions that practitioners can use to program their training data. We ran an experiment to test the efficacy of a basic model + training data operations—applying a handful of these to the SuperGLUE Benchmark yields new state-of-the-art score results overall and the highest reported score anywhere on a majority of component tasks.
We will be releasing code in the Snorkel repo for reproducing and building on our results in conjunction with a 2-day Snorkel workshop during the last week of June with collaborators from science, industry, and government. This workshop is unfortunately already completely full, but if you would like to be notified of future Snorkel workshops, give us your name and contact information here.
Three key abstractions
In our result, as well as more generally, we find that spending our time programmatically building and manipulating the training data—rather than the models—provides a powerful and effective strategy to achieve high performance in ML pipelines. In a past post, we talked about the value of incorporating more supervision signal from more sources, e.g. multi-task learning and transfer learning, as we achieved SOTA on the GLUE Benchmark (a precursor to SuperGLUE). In this post, we focus on three key abstractions for building and modifying training datasets:
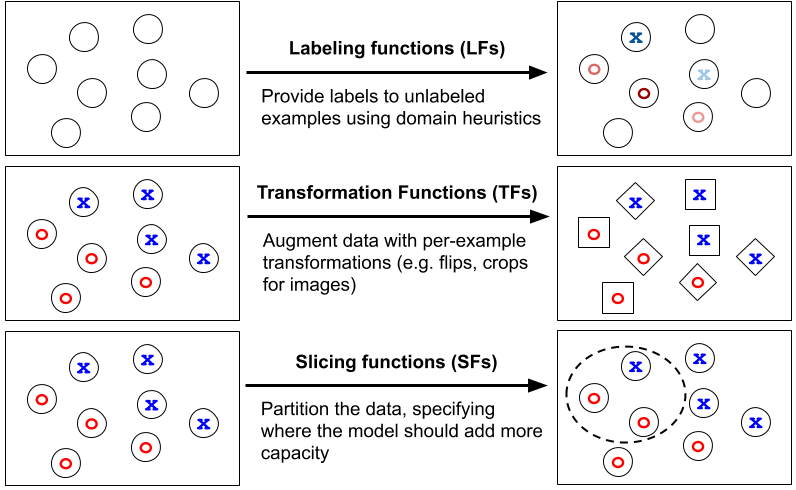
- Labeling data with labeling functions (LFs) 2
- Transforming data with transformation functions (TFs) 3 4
- Partitioning data with slicing functions (SFs) 5
Running Example
For the remainder of this post, we use a running example from the Words in Context (WiC) task from SuperGLUE: is the target word being used in the same way in both sentences?

1. Weak labeling with labeling functions
In many applications, unlabeled data is abundant—it may come from fleets of autonomous vehicles, or large corpuses of unstructured data. Modern architectures are largely unable to take advantage of such potentially rich datasets because labeling them might be intractable, as they are too time or cost ineffective.
With Snorkel, we’ve studied for years the use of labeling functions (LFs) for heuristically labeling training examples. LFs provide domain experts or machine learning practitioners with an intuitive interface for denoising and combining supervision sources from existing datasets, models, or crowd labelers.

2. Augmenting data with transformation functions
Often, people think about data augmentation in terms of simple transformations—randomly rotating or stretching images—but they can often refer to much more diverse range of operations. We see transformation functions (TFs) as a powerful abstraction that heuristically generates new, modified examples from existing ones. For instance, for a medical imaging task, we might write TFs to perform transformations that are specific to our imaging modality—e.g. resampling segmenting tumor masses or resampling background tissue.
We have explored this abstraction in our own work, TANDA 3, which seeks to learn compositions of transformations across domain-specific tasks. AutoAugment 4 from Google builds on this work to automatically learn policies for augmentation strategies.

3. Partitioning data with slicing functions (new idea!)
In many datasets, especially in real-world applications, there are subsets of the data that our model underperforms on, or that we care more about performing well on than others. For example, a model may underperform on lower-frequency healthcare demographics (e.g. younger patients with certain cancers) or we may care extra about model performance on safety-critical but rare scenarios in an autonomous driving setting, such as detecting cyclists. We call these data subsets slices. The technical challenge often faced by practitioners is to improve performance on these slices while maintaining overall performance.
Slicing functions (SFs) provide an interface for users to coarsely identify data subsets for which the model should commit additional representational capacity. To address slice-specific representations, practitioners might train many models that each specialize on particular subsets, and then combine these with a mixture-of-experts (MoE) approach 6. However, with the growing size of ML models, MoE is often impractical. Another strategy would be to train a single model in the style of multi-task learning (MTL) with hard parameter sharing 7. While more computationally efficient, this approach expects representation bias across many slice-specific tasks to improve performance—an often unreliable approach. As a quick overview 5 — we model slices in the style of multi-task learning, in which slice-based “expert-heads” are used to learn slice-specific representations. Then, an attention mechanism is learned over expert heads to determine when and how to combine the representations learned by these slice heads on a per-example basis.
We consider the following properties of our approach:
- Our approach is model-agnostic — expert heads are learned on top of any backbone architecture (e.g. BERT, ResNET). As a result, practitioners can focus only on the data, and not the model architecture.
- By learning in a multi-task fashion, we efficiently learn representations without the need to make many copies of the model (i.e. MoE requires too much memory)!
- By incorporating the attention mechanism, we avoid manual tuning of expert-heads—an otherwise significant developer cost.

Key properties of LFs, TFs, and SFs
- Intuitive interfaces: These abstractions provide intuitive interfaces to existing practitioner workflows. They allow insights from debugging/error analysis to be directly encoded to improve models.
- Programming abstractions as weak supervision: Furthermore, in practice, many of these techniques can be viewed as a form of weak supervision, as users specify them in noisy, heuristic, and imprecise ways. Dealing with this is one of the core technical challenges we tackle in frameworks like Snorkel.
- Supervision as code: These types of inputs are ways of supervising a model (i.e. they specify training sets). Concretely, they are also code, and thus carry many of the advantages of code—reusability, modifiability, etc.
SuperGLUE Results
Using these programming abstractions, we achieve new SOTA on the SuperGLUE Benchmark and 4 of its components tasks. SuperGLUE is similar to GLUE, but contains “more difficult tasks…chosen to maximize difficulty and diversity, and…selected to show a substantial headroom gap between a strong BERT-based baseline and human performance.” After reproducing the BERT++ baselines, we minimally tune these models (baseline models, default learning rate, etc.) and find that with applications of the above programming abstractions, we see improvements of +4.0 points on the SuperGLUE benchmark (21% reduction of the gap to human performance).
Snorkel in the Real World
These Snorkel programming abstractions have also been used to fuel progress in high-impact real-world applications.
In March of this year, we published a paper and blog post with Google on the lessons learned from deploying Snorkel at industrial scale. Relying on diverse sources of knowledge across the organization—heuristics, taggers, knowledge graphs, legacy systems, etc.—they saw significant improvements in quality, by as much as 17.5 F1 points.
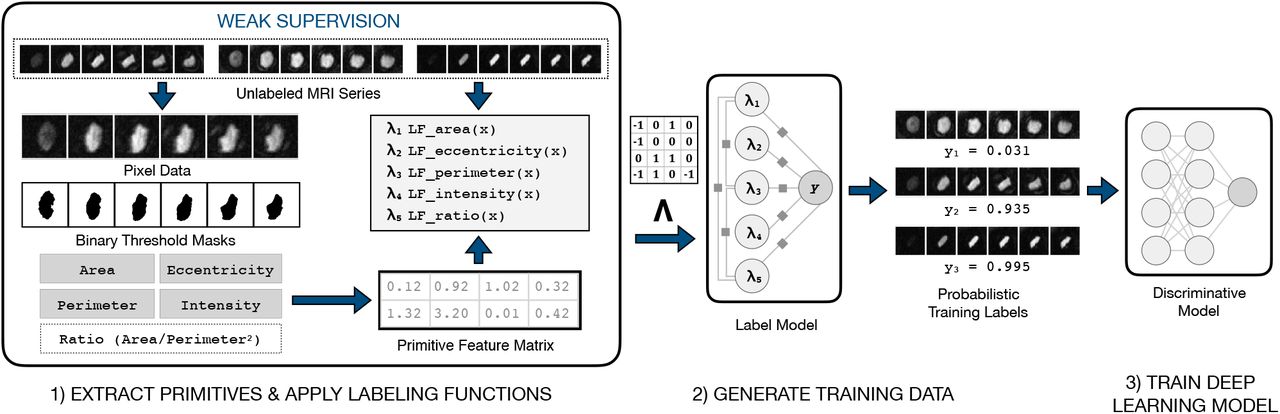
In recent work that was accepted to Nature Communications, Snorkel was deployed in an ongoing collaboration with Stanford University Pediatric Cardiology, where labeled training data is a significant practical roadblock to developing automated methods. We focused on bicuspid aortic valve (BAV), the most common congenital heart malformation (with an incidence rate of 0.5-2% in the general population), with risk of adverse downstream health effects. Instead of relying on costly MRI labels from cardiologists, we worked directly with domain experts to develop LFs to generate large-scale training sets for downstream deep learning models. In patients identified by our end-to-end approach, an independent evaluation determined a 1.8-fold increase in risk for major adverse cardiac events.
In another forthcoming Nature Communications paper, we showed how Snorkel can be used to automate Gene-Wide Association Study (GWAS) curation. On a collection of hundreds of previously published studies reporting significant genotype-phenotype pairs, we auto-labeled a large training set using only labeling functions. The resulting classifier applied to a collection of 598 studies recovered over 3,000 previously documented open-access relations (with an estimated recall of 60-80%) as well as over 2,000 associations not present in existing human curated repositories (with an estimated precision of 82-89%). The resulting database is available for exploration with a user interface at http://gwaskb.stanford.edu/.
Stay Tuned
The Snorkel project is active and ongoing! A code release later this month will include significant infrastructural improvements and tutorials for how to apply LFs, TFs, and SFs to SuperGLUE and other tasks. If you’ve used Snorkel for your own applications, we’d love to hear about it! For updates on Snorkel developments and applications, you can always visit the Snorkel landing page or open-source repository.
Acknowledgements
The authors would like to thank Feng Niu and Charles Srisuwananukorn for many helpful discussions, tests, and collaborations throughout the development of slicing!
References
-
Wang, Alex, et al. “SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems”. 2019. SuperGLUE consists of 6 datasets: the Commitment Bank (CB, De Marneffe et al., 2019), Choice Of Plausible Alternatives (COPA, Roemmele et al., 2011), the Multi-Sentence Reading Comprehension dataset (MultiRC, Khashabi et al., 2018), Recognizing Textual Entailment (merged from RTE1, Dagan et al. 2006, RTE2, Bar Haim et al., 2006, RTE3, Giampiccolo et al., 2007, and RTE5, Bentivogli et al., 2009), Word in Context (WiC, Pilehvar and Camacho-Collados, 2019), and the Winograd Schema Challenge (WSC, Levesque et al., 2012). ↩
-
Ratner, Alexander J., et al. “Data programming: Creating large training sets, quickly”. 2016. ↩
-
Ratner, Alexander J., et al. “Learning to compose domain-specific transformations for data augmentation”. 2017. ↩ ↩2
-
Cubuk, Ekin D., et al. “Autoaugment: Learning augmentation policies from data”. 2018. ↩ ↩2
-
Chen, Vincent S., et al. “Slice-based Learning: A Programming Model for Residual Learning in Critical Data Slices”. 2019. ↩ ↩2
-
Robert A Jacobs, Michael I Jordan, Steven J Nowlan, and Geoffrey E Hinton. “Adaptive mixtures of local experts”. 1991. ↩
-
Rich Caruana. “Multitask learning”. 1997. ↩