Butterflies Are All You Need: A Universal Building Block for Structured Linear Maps
We use a type of structured matrix known as a butterfly matrix to learn fast algorithms for discrete linear transforms such as the Discrete Fourier Transform. We further introduce a hierarchy of matrix families based on composing butterfly matrices, which is capable of efficiently representing any structured matrix (any matrix with a fast matrix-vector multiplication algorithm, such as low rank or sparse matrices), with a nearly optimal number of parameters. We experiment with the usage of butterfly matrices for a diverse set of applications including learning several types of special linear transforms, learning latent permutations, and as a generic approach for compressing neural networks.
Our paper was accepted to ICML 2019! Our code is also available here.
Structured linear maps such as discrete transforms (like the Discrete Fourier Transform), permutations, convolutions, low-rank matrices, and sparse matrices are workhorses of machine learning. Below is just a sampling of different types of structured matrices and their uses in machine learning and related fields.

Each particular structure has a compressed representation and correspondingly admits an efficient multiplication algorithm, instead of the generic matrix-vector multiplication algorithm which takes \(O(N^2)\) time for an \(N \times N\) matrix. However, these representations and algorithms all differ drastically from each other. Two important and broadly useful classes of such structured matrices – sparse and low-rank – are displayed in Figure 1.

Imposing structure on a transformation entails choosing from the variety of structures available, requires specialized algorithms, and may not perform well across all use cases. In some cases, a specific transform is hand-crafted using human domain expertise (e.g. signal processing, feature preprocessing). In other cases where a number of methods seem reasonable – for example, many structures have been proposed for model compression – each candidate type requires a specialized implementation, a different training procedure, and a different tuning protocol. There seems to be no principled way to choose a parameterization other than trial and error.
This raises the question: is there a way to automatically learn the type of structured linear map needed for an application, obviating the need for hand-selection? Successfully doing so unlocks a range of possibilities, from improving feature extraction pipelines to unifying highly specialized neural network architectures. More broadly, this probes at the fundamental question of understanding the minimal structural priors needed for effective linear maps.
In this post, we address this question and introduce our approach, which involves a structured matrix known as a butterfly matrix. We show how butterfly matrices can be used to learn specific types of recursive linear transforms, and then that they actually form a universal building block that captures all structured matrices.
A Recursive Structural Prior
The challenge is to find a parametrization that is capable of representing the above structured matrix classes, without using too many parameters. Although a normal unconstrained matrix can obviously represent any structured matrix, this forfeits the inductive biases and efficiency benefits offered by the above examples. For example, although Fourier-like transforms are dense and full-rank, there is clearly structure in them, as they have efficient O(N log N) algorithms.
To address this challenge, we draw two lessons from the work of De Sa et al. (SODA 2018):
- Matrices that admit structured representations and fast algorithms can be factored into products of matrices with a small total number of nonzeros. Roughly speaking, a matrix which has a matrix-vector multiplication algorithm that uses S total flops1 has a factorization with O(S) total nonzeros (nnz). This observation alone isn’t sufficient, as learning over products of general sparse matrices is still difficult due to the non-differentiability of the locations of the nonzeros.
- A surprisingly general set of structured matrices have recursive structure, i.e. multiplication algorithms involving divide-and-conquer strategies.
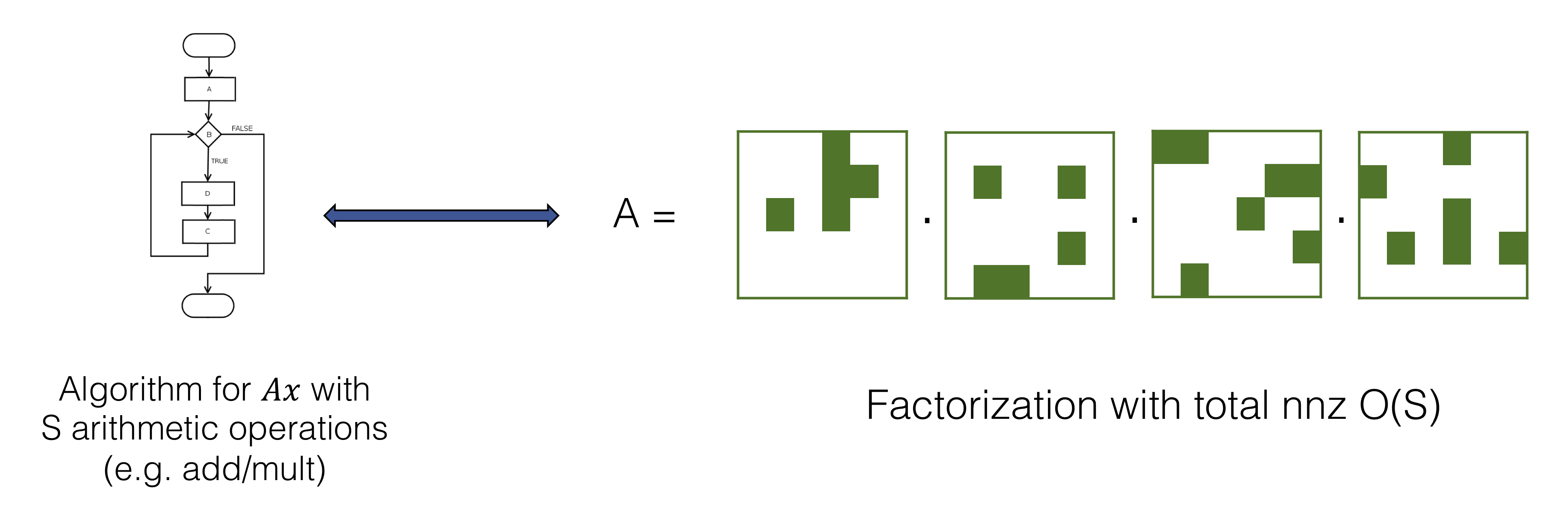
These observations suggest using a recursive structural prior, where the parametrization is a product of sparse matrices that together model a recursive algorithm. To motivate this further, let’s first step through the famous Fast Fourier Transform (FFT) algorithm as a case study to see how the idea of recursive divide-and-conquer translates to the language of matrix factorization.
Case Study: the Fast Fourier Transform
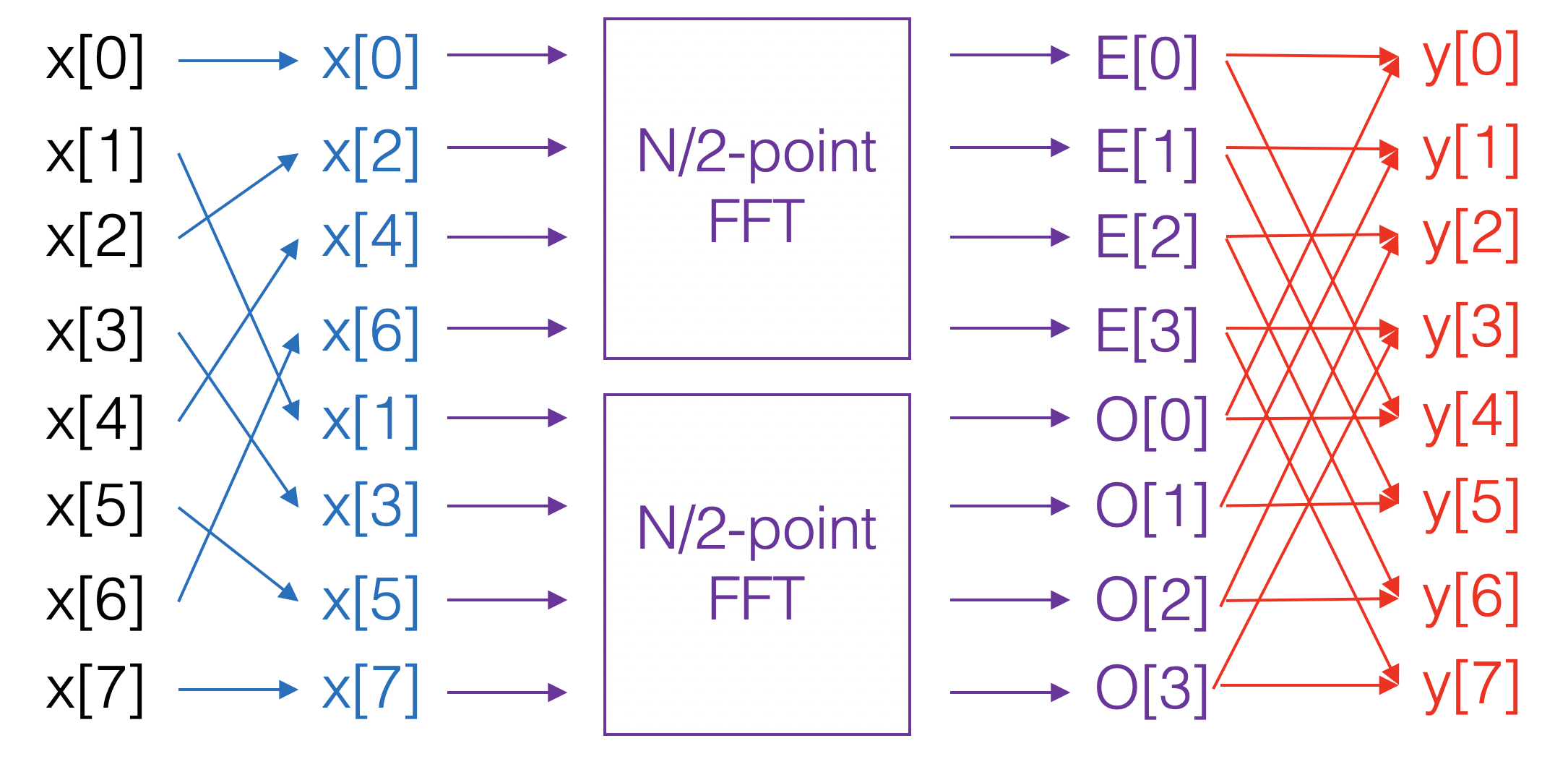
The FFT algorithm for computing the Discrete Fourier Transform works, in short, by
- Separating the even and odd indices of the input
- Performing an FFT of half the size on each half
- Re-combining pairs of indices using a “butterfly” structure, i.e. multiplication by a 2x2 matrix.2
This procedure is illustrated in Figure 3.
By unrolling this recursion and analyzing the sparsity pattern, a recursive factorization of the FFT matrix emerges. The resulting factorization’s sparsity pattern is called a butterfly matrix, and each individual sparse matrix in the product is a butterfly factor.
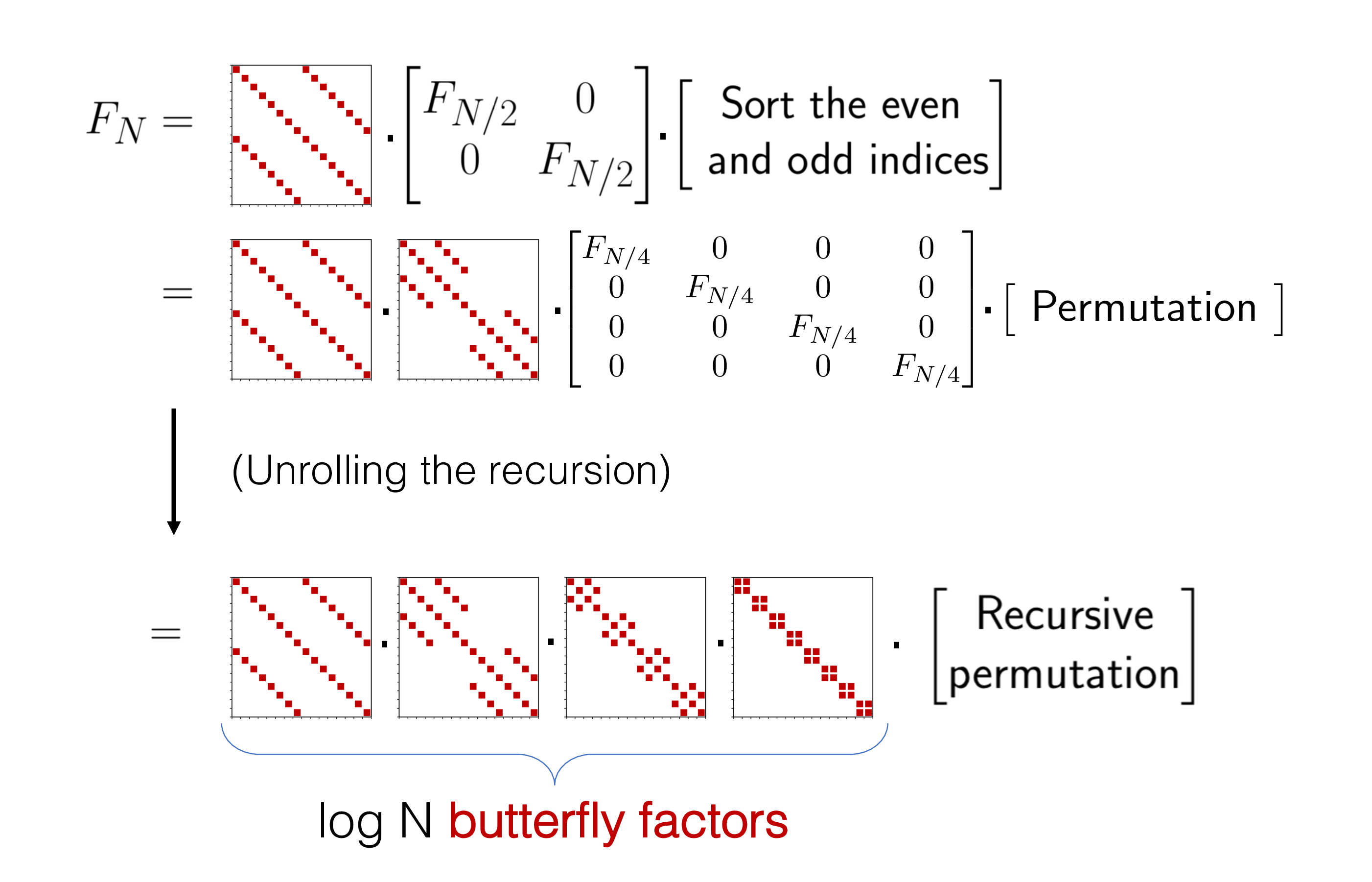
More specifically, a butterfly matrix is one that can be expressed as the product of the log(N) butterfly factors with sparsity patterns depicted in Figure 4; this factorization is the parametrization of the butterfly matrix. Note that the sparsity pattern of each butterfly factor is fixed, so when using a butterfly matrix in an end-to-end model, the entries of the factorization can simply be trained using standard gradient-based methods such as SGD.
Learning discrete transforms using butterfly
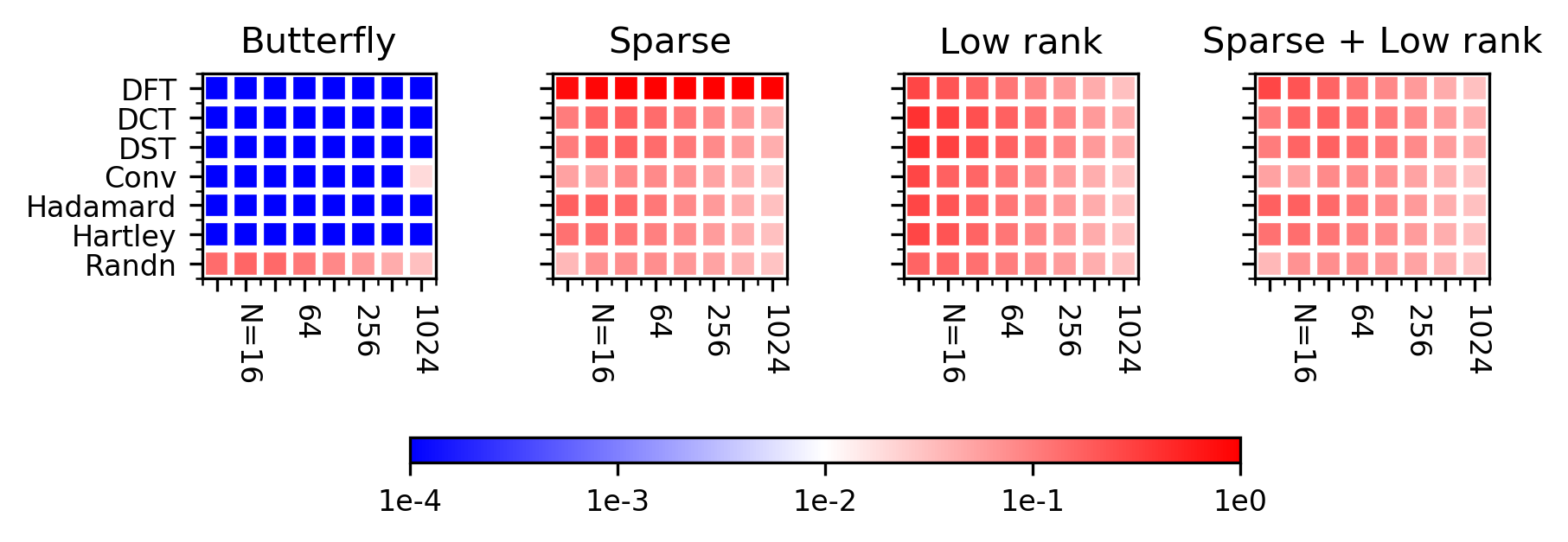
The proposed butterfly parametrization captures the FFT by design, but it is also capable of modeling a family of related transforms such as the Discrete Cosine Transform, the Hadamard transform, and more. In Figure 5, we show that this representation can indeed learn such transforms through optimization. In short, using gradient descent and L-BFGS, we minimized the distance from a butterfly matrix to a fixed transform, as measured by the RMSE (i.e. the Frobenius norm of the difference). We also compare against standard matrix approximation baselines using sparse and low-rank representations, which are unable to recover these transforms. More detailed descriptions of these structured transforms and our methodology is described in the paper.
Butterflies are all you need: A universal parametrization that captures any structured matrix!
So far so good – we can learn important recursive transforms such as the Discrete Fourier Transform and Discrete Cosine Transform using a single parametrization. But what about the other types of structure, such as the ubiquitous sparse and low-rank, or more complicated structured matrices? The previous experiment found that sparse or low-rank matrices cannot really represent butterfly matrices – is the converse also true?
The surprising news is that all of these structures can be represented (with a nearly tight parameter count) by simply composing butterfly matrices. In other words, the butterfly matrix is a universal building block for structured matrices. More specifically, we define a hierarchy of structured matrices by simply stacking butterflies: \(B_1B_2^T, B_1B_2^TB_3B_4^T, B_1B_2^TB_3B_4^TB_5B_6^T,\) etc. Here, \(B_1B_2^T\), for instance, refers to the composition of a butterfly matrix, \(B_1\), and the transpose of another butterfly matrix, \(B_2^T\). Note the similarity to the "rank hierarchy", wherein the set of rank-1 matrices is included in the set of rank-2 matrices and so on, but instead of parameterizing matrices from low to high rank, this butterfly hierarchy smoothly parameterizes matrices with multiplication algorithms from simple to complex.

Our most general result shows that any matrix with a fast matrix-vector multiplication algorithm, formalized as an arithmetic circuit with \(s\) total gates and depth \(d\), can be represented in this butterfly hierarchy with \(O(d s \log s)\) parameters. In most cases, \(d = O(\log N)\) where \(N\) is the dimension of the matrix, so we get \(O(s \log s \log N)\) parameters, almost tight up to logarithmic factors!
Applications: Butterfly in Action
This universality property is quite elegant – but what can we do with it? We might expect the ability to represent arbitrary structure to be useful either
- to approximate unstructured data well – at least, better than other parametrizations – by capturing whatever structure might exist in it, or
- to learn existing latent structure given to us.
Below we show fun examples of both of these ideas.
Neural Network Compression
A common application of structured matrices is to compress various linear components of machine learning models. In particular, it is well established that neural networks are highly overparameterized, and many compression techniques using structured matrices have been proposed. A simple approach is replacing fully-connected layers with low-rank maps. More commonly, many variants of pruning have been proposed. These can be seen as examples of structured matrix-based compression involving sparse matrices.
Due to the butterfly’s ability to capture any structure, it provides a principled way to perform this style of compression. For example, although it is more general than sparsity, it avoids the discreteness inherent to sparse representations that leads to the heuristic and iterative pruning approaches seen today.
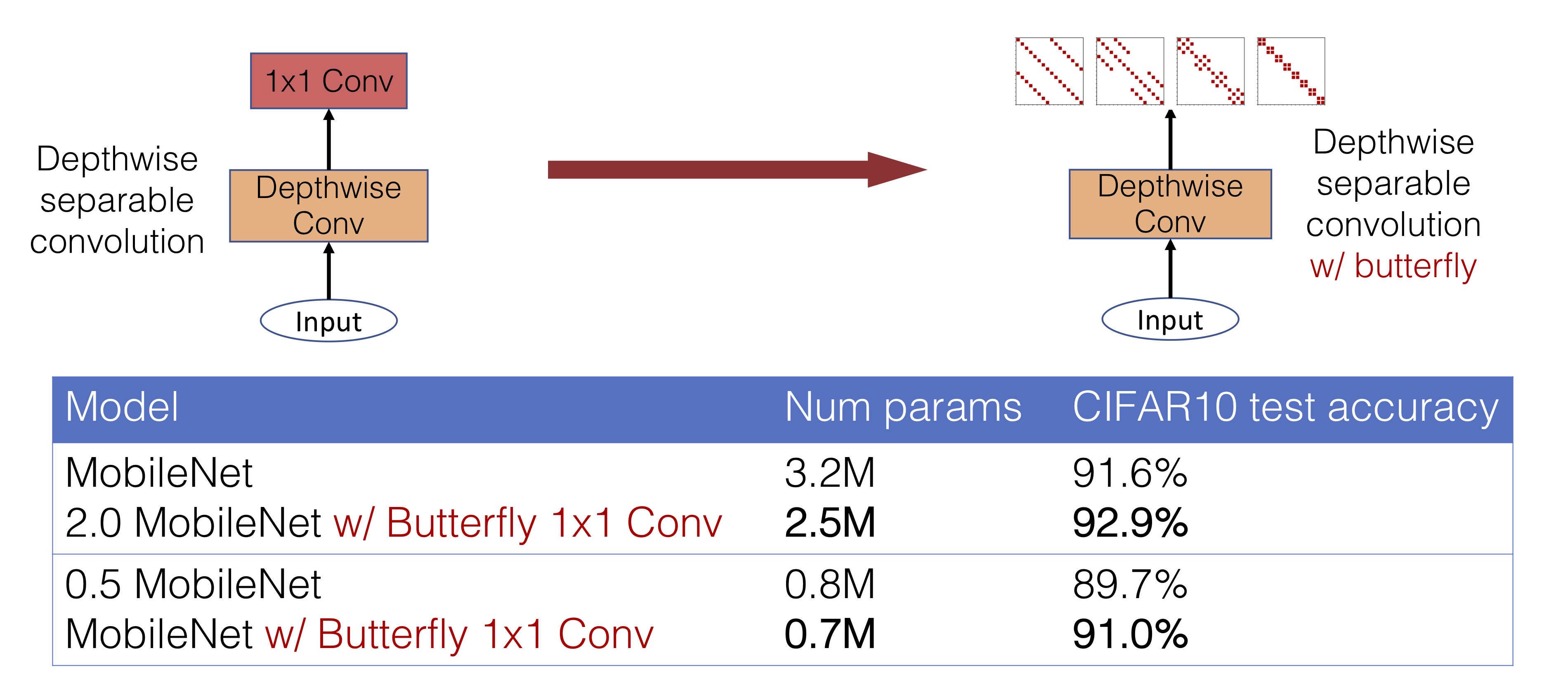
In Figure 6, we show an example of how butterfly matrices can be effectively used to improve modern neural network architectures. More specifically, we look at replacing 1x1 convolution layers in CNNs with butterfly transformations. Used in architectures such as MobileNet which have depthwise-separable convolutions, these 1x1 convolutions can be seen as just basic matrix multiplication across the “channel” dimension, so an alternate matrix parametrization can be substituted quite easily. Note that MobileNet was already designed to be an efficient architecture; with butterfly matrices, we can further reduce the parameter count while increasing accuracy of about 1.3% on CIFAR-10 at the same time, just by doubling the number of channels (i.e. network width) and replacing dense 1x1 convs with butterfly matrices. For more experiments, including the effectiveness of butterfly in replacing standard fully-connected layers in the “spatial” dimensions, see the paper.
Permutation Learning
We’ve seen that the butterfly layer is effective in end-to-end models, and is better able to capture or compress generic structured linear maps than other approaches, due to its universality properties.
However, although the theory says that this fixed parametrization is expressive enough to capture a wide variety of named structures, including examples of non-continuous structure such as sparsity and permutations, the matrices learned in CNNs do not necessarily have any special structure.
Here we try a fun application to see if butterfly is able to recover a specific instance of a latent structured linear map in an end-to-end model. We investigate the problem of learning a latent permutation, which is a difficult problem given the discreteness and exponentially large size of the constraint set. In particular, we use a permuted image classification dataset (permuted-CIFAR-10), where a fixed global permutation is applied to the pixels of every image in the original input set; this type of task is a popular benchmark in areas such as continual learning and long-range RNN architecture design.
Previously, only fully-connected and recurrent models have been tested on permuted datasets, because the permutation destroys spatial locality in the image, preventing CNNs from working as intended. However, these models are not well-suited for image tasks; we’d thus expect that learning the permutation with a differentiable butterfly layer and then applying a standard CNN is much more effective than the baselines.
Our architecture is simply a ResNet18 with an extra linear layer inserted at the very beginning, which attempts to learn the latent permutation before feeding the images to the convolutional layers.
It can be observed that the butterfly factors have a particularly simple structure – each one is just a permuted block-2x2-diagonal matrix. Therefore, it is easy to use additional techniques to help the butterfly transform better model permutations:
- We constrain the butterfly matrix to be positive doubly-stochastic by giving each \(2 \times 2\) block the form \(\begin{bmatrix} a & 1-a \\ 1-a & a \end{bmatrix}\).
- We use it to induce a distribution over permutations, where each \(2 \times 2\) block generates the "identity" \(\begin{bmatrix} 1 & 0 \\ 0 & 1 \end{bmatrix}\) with probability \(a\) and the "swap" \(\begin{bmatrix} 0 & 1 \\ 1 & 0 \end{bmatrix}\) with probability \(1-a\).
- Samples \(Px\), generated by applying permutation samples on the (permuted) inputs, are fed into an additional unsupervised reconstruction loss measuring total variation smoothness of the de-noised inputs: \[ \sum_{0 \le i, j < n} \left\| \begin{bmatrix} (Px)[i+1,j]-(Px)[i,j] \\ (Px)[i,j+1]-(Px)[i,j] \end{bmatrix} \right\|_2 \] Essentially, this loss function penalizes images that vary significantly between adjacent pixels.
Such techniques are inapplicable to a general linear layer. Note also that other structures mentioned such as low-rank, circulant, and so on, are simply unsuited to this task, as they are incapable of modeling permutations.
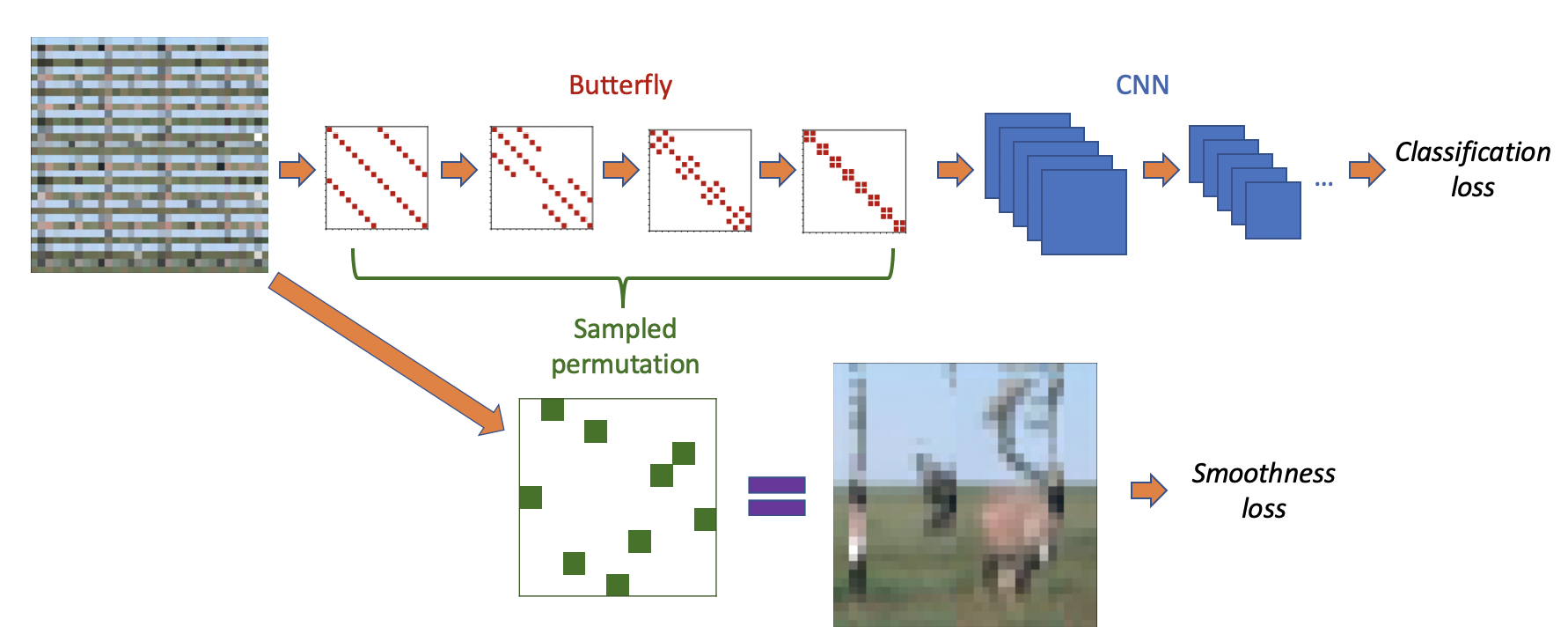
The full architecture is depicted in Figure 7. Overall, the model achieves 92.48% accuracy on this permuted dataset using a ResNet18 CNN. In comparison, the CNN itself, without the stochastic butterfly layer, achieves 73.71% accuracy; the CNN with an unconstrained linear layer inserted achieves 84.38% accuracy; and the reference CNN on the un-permuted dataset achieves 94.85% accuracy. This showcases the butterfly parametrization’s ability not only to represent weird structures like permutations, but model distributions over them!
It’s fast, too!
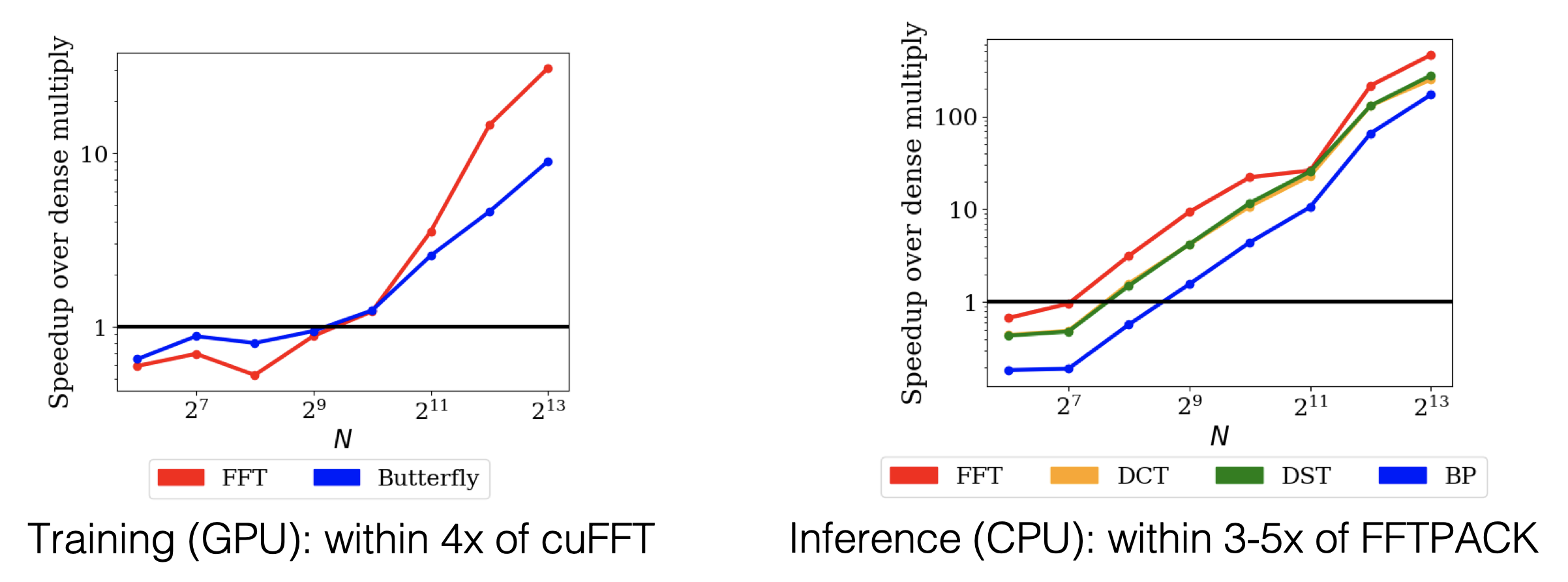
So far we’ve discussed mainly the parameter count of the butterfly representation. But this translates into fast algorithms by design,3 matching the O(N log N) operation count of the FFT algorithm. In fact, the low FLOP count and simple recursive structure of the butterfly also translates to a practical and efficient implementation! This is a significant improvement over the existing structured matrix approaches, as some of the most expressive structured matrices previously proposed, despite having a good tradeoff between model quality and parameter count, are too slow to be practically useful. The plots in Figure 8 show the speedup of butterfly over standard dense matrix multiply (GEMM/GEMV) during training and inference. Butterfly’s speed is competitive with optimized implementations for the FFT, discrete cosine transform, and discrete sine transform, which are all hand-crafted for particular transforms. For large matrix dimensions, butterfly matrix multiplication is an order of magnitude faster than dense matrix-matrix or matrix-vector multiplication.
Try it out
The code reproducing experiments in the paper is available here.
It additionally comes with efficient implementations of butterfly matrices using C++/CUDA, with an easy-to-use PyTorch interface that can be used as a drop-in replacement of other linear components:
simply replace nn.Linear(m, n) with Butterfly(m, n) in your own models!
Footnotes
-
This is restricted to algorithms that use arithmetic operations, e.g. addition/subtraction/multiplication/division. ↩
-
The terminology butterfly is named after the shape of the wire diagram where it appears, such as in the Fast Fourier Transform algorithm. ↩
-
As a butterfly matrix is a product of O(log N) factors, each with O(N) nonzero entries, one can multiply a butterfly matrix with an input vector by multiplying that vector with each factor, starting from the rightmost factor. This gives an O(N log N) algorithm. ↩