Learning Dependency Structures in Weak Supervision
Recently, weak supervision has been used to efficiently label large-scale training sets without traditional hand-labeled data across applications in academia and industry. However, users cannot always specify which dependencies (i.e., correlations) exist among the weak supervision sources, which could potentially number in the hundreds.
We discuss a method to learn the dependency structure of weak supervision sources without using traditional hand-labeled data. A few of our benefits:
- Improved sample-complexity: sublinear, and in some cases, logarithmic in the number of sources,
- Up to 4.64 F1 point improvement over an existing model that assumes conditional independence
Our paper was accepted to ICML 2019! Our code is also available as part of Snorkel MeTaL.
Why Care about Correlations?
Sources are correlated if they use the same information or label data points in a similar manner. Without knowledge of their structure, we can incorrectly learn high accuracies for these sources that always agree—and potentially overcount them.
In the weak supervision setting, we want to learn the accuracies of the imperfect weak supervision sources based on the labels they assign to the data at hand, without using hand-labeled data. To do so, we rely on the agreements and disagreements among independent sources with the intuition that sources that agree with each other more probably have high accuracies.
In real-world settings, sources can be correlated for various reasons:
- Sources that use the same underlying information about the data: e.g., two sources that rely on the area of a segmented area in the image to assign a label
- Sources that rely on the same external knowledge base, and are therefore susceptible to making the same errors
- Sources developed by different users based on the same logic: e.g., looking for the same words in a sentence
Not accounting for these correlations can result in the model overestimating the accuracies of sources that tend to agree, therefore leading to low quality training labels.
Learning Structures in Weak Supervision
We use a robust PCA-based approach to learn the dependency structure among the weak supervision sources without using any ground truth labels. Unlike previous approaches for the weak supervision setting, we exploit the sparsity of the dependency structure to more accurately and efficiently learn dependency structures.
We model the sources as a graphical model, with each source (along with the latent label) being a node. In many situations, the graph is sparse — a characteristic we should be able to exploit when learning the edges for these graphs in the weak supervision setting.

Instead of iterating over each node individually to learn the dependency structure (the node-wise approach), we operate over the entire covariance matrix of the observable sources. Graphs like the ones shown have inverse covariance matrices that reflect the structure of the graph, i.e., they are graph structured.
Getting discrete random vectors to exhibit graph-structured behavior in their inverse covariance matrices is often challenging—unlike in the Gaussian case, where no additional work is necessary. Fortunately, a simple (and natural, in the weak supervision setting) assumption—the singleton separator set assumption—gives us this behavior. We assume that the sources form fully connected clusters, all of which are connected to the latent label \(Y\), but none of which are connected to each other. An example, along with the resulting inverse covariance matrix is
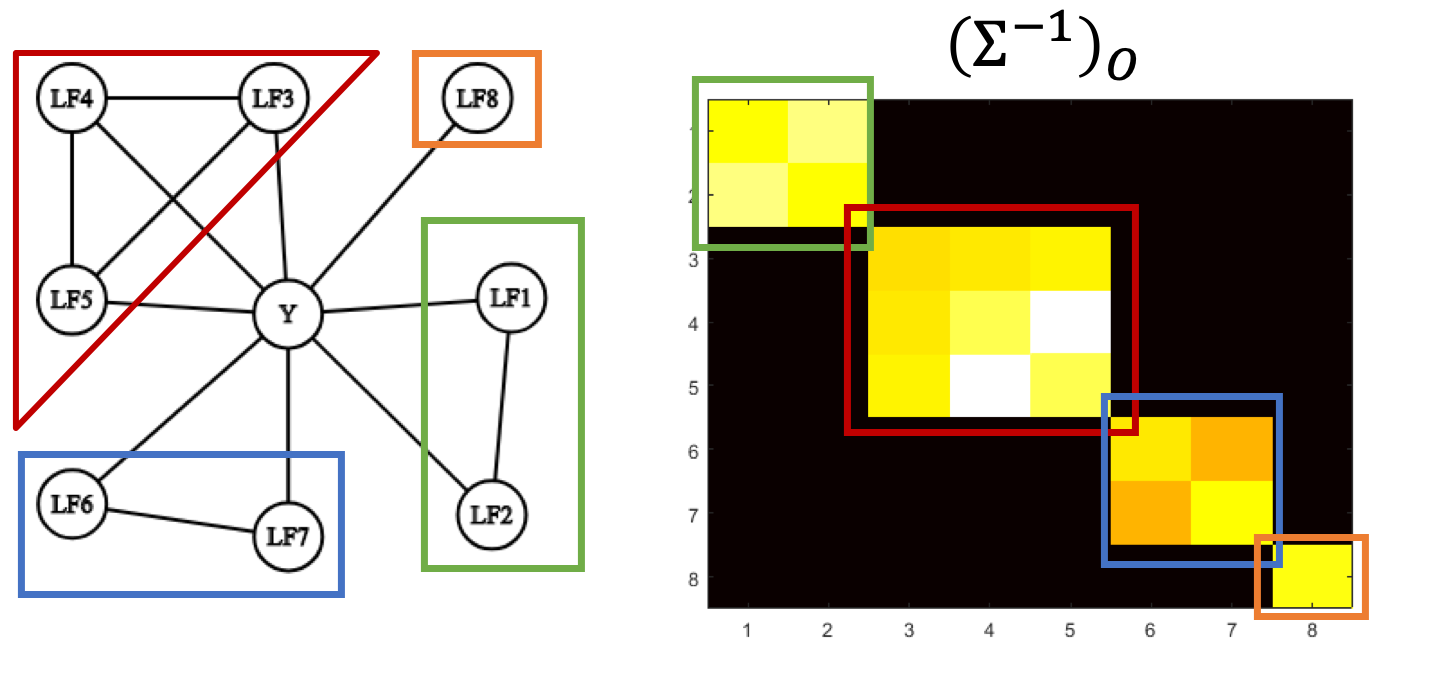
However, unfortunately, we only partially observe this matrix, and inverting the observed submatrix does not yield graph-structured behavior.
We begin with the observable covariance matrix of the sources, where n is the number of unlabeled datapoints, \(\Lambda\) is is the matrix of observed labels from the supervision sources and \(v\) is the mean label assigned by the sources.
\[\Sigma_O^{(n)} = \frac{1}{n}\Lambda \Lambda^T - vv^T\]Then, we use the fact that the inverse covariance matrix for our model is graph-structured. However, note that we cannot observe the true label Y, and therefore cannot observe the full inverse covariance matrix K. Instead, we only have access to an estimate of \(\Sigma_O\).
\[\textbf{Cov}[O \cup \mathcal{S} ] = \Sigma = \begin{bmatrix} \Sigma_O & \Sigma_{O\mathcal{S}} \\\Sigma_{O\mathcal{S}}^T & \Sigma_\mathcal{S} \end{bmatrix}, \Sigma^{-1} = K = \begin{bmatrix} K_O & K_{O\mathcal{S}} \\ K_{O\mathcal{S}}^T & K_\mathcal{S} \end{bmatrix}\]We take advantage of the fact that the inverse covariance matrix K has a graph-structured component \(K_O\), which encodes the structure of the supervision sources, in terms of the observable covariance matrices.
\[K_O = \Sigma_O^{-1} + c\Sigma_O^{-1}\Sigma_{O\mathcal{S}} \Sigma_{O\mathcal{S}}^T\Sigma_O^{-1}\]We can now decompose the observable inverse covariance matrix in terms of the structured matrix we want to recover:
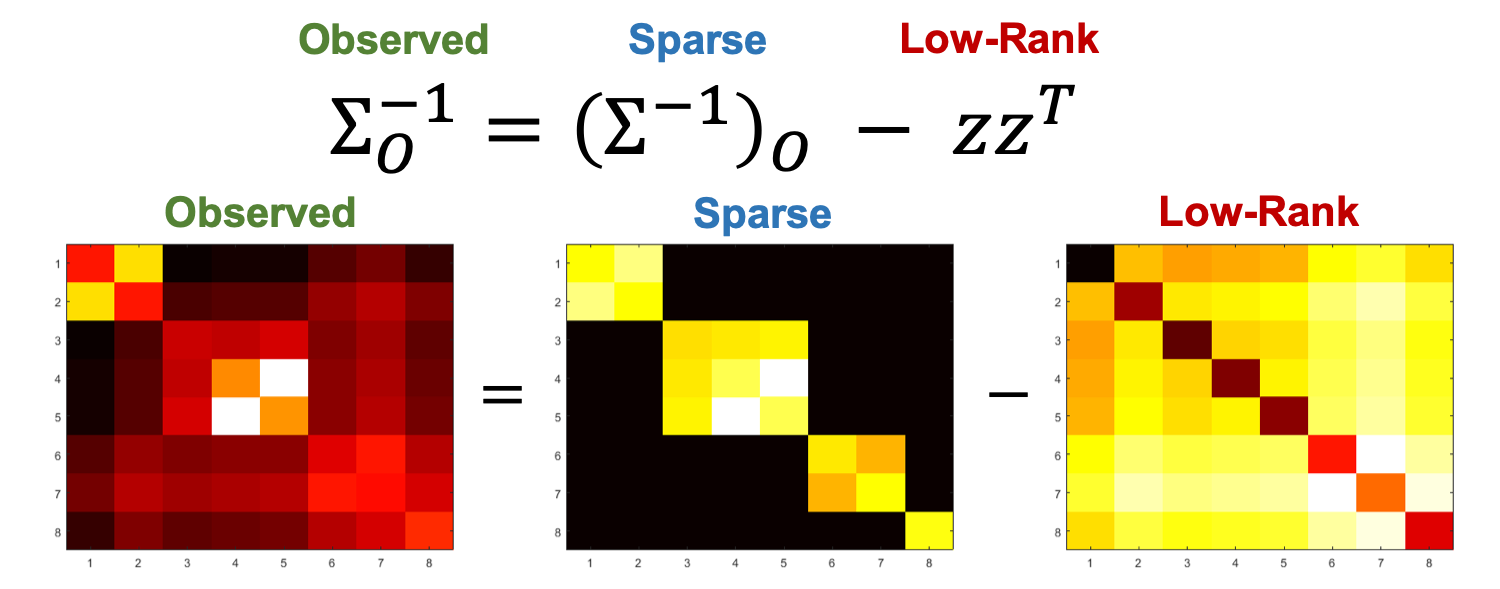
Note that if we could access \(K_O = (\Sigma^{-1})_O\), we could read off the graph, but instead we only see \(\Sigma_O^{-1}\), where the structure has been distorted by the low-rank term \(zz^T\).
We now have a problem that decomposes an observable matrix into a sparse and a low rank matrix, both of which are unknown. We can then use robust PCA (introduced by Candes et al and Chandrasekaran et al) to estimate these matrices; for the sparse matrix, we use the indices of the non-zero entries as edges that exist among the supervision sources.
Theoretical Guarantees:
We’d like to study how many samples of unlabeled data points we need to recover the graph with high-probability. We exploit the notion of the effective rank of the covariance matrix, to obtain sample complexity rates that are sublinear in $m$, and in some cases, logarithmic in $m$, matching the supervised optimal rate.

We study our algorithm under two conditions on the effective rank of the covariance matrix, defined as:
\[r_e(\Sigma_O) = \textbf{tr}(\Sigma_O) / \|\Sigma_O\|.\]First, we look at a condition we call the Source Block Decay (SBD) condition. This limits the total number of clusters (\(s\)) and translates to the strength of the correlations in a clustering differing. This condition results in a sample complexity of \(\Omega(d^2m^\tau)\) for our robust PCA based method (\(0 < \tau < 1\)).
\[r_e(\Sigma_O) \leq \frac{m^{\tau}}{(1+\tau) \log m}, s \leq \frac{m^{\frac{\tau}{2-\tau}}}{((1+\tau)\log m)^{2/(2-\tau)}}.\]Second, we look at the Strong Source Block (SSB) condition, which is equivalent to the presence of a cluster of sources that forms a strong voting block dominating the other sources. With this condition, the sample complexity is \(\Omega(d^2 (1 + \tau) \log m))\), the optimal rate from the supervised case.
\[r_{e}(\Sigma_O) \leq c d, \text{ where } c \text{ is a constant.}\]In our paper, we also derive an information-theoretic lower bound to explore the fundamental limits of learning structure in the presence of latent variables.
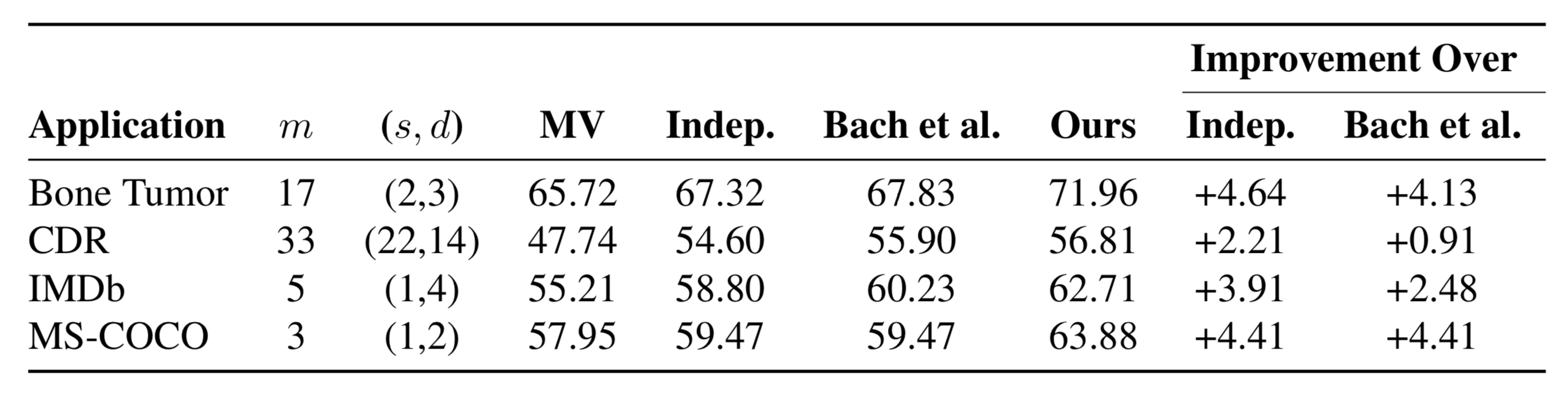
Experimental Results
Incorporating the structure of sources in the model improves end model performance by up to 4.64 F1 points over a model without any dependencies and by 4.41 F1 points over a previous structure learning method.
Across applications in relation extraction and image classification, we find that the training labels generated by a model that incorporates the dependencies our method learns generates more accurate training labels than baselines. We compare the performance of end models trained using labels from models form our method, a previous structure learning approach (Bach), and a model that does not account for source correlations (Indep.)