An Analysis of DAWNBench v1, a Time-to-Accuracy Benchmark for Deep Learning
As the cost of training deep learning models has increased, the community has proposed a range of hardware, software, and statistical optimizations to decrease this cost. While some of these optimizations simply run the same operations faster (e.g., upgrading from a K80 to a P100), others (e.g., asynchronous SGD, reduced precision) trade off statistical performance (number of iterations needed to obtain a certain accuracy) for improved hardware performance (time needed for each iteration). To understand these trade-offs, we created DAWNBench and used “time-to-accuracy” as the main metric. In the first iteration of DAWNBench, time-to-accuracy and cost-to-accuracy fell by orders of magnitude for both ImageNet and CIFAR10.
Despite these dramatic improvements, we still had questions about the time-to-accuracy metric. Can competitors cherry-pick the best training run? Do models optimized for time-to-accuracy generalize well? How important is the accuracy threshold? Can optimizing models for time-to-accuracy teach us anything?
To answer these questions, we leveraged the code included with submissions to DAWNBench. Even though we didn’t require code with submissions, we were pleasantly surprised to see all the ImageNet and CIFAR10 entries provided open-source code. This was invaluable in running the experiments presented in this blogpost and the accompanying preprint. These experiments provide evidence that time-to-accuracy is stable, models optimized for time-to-accuracy generalize well, the accuracy threshold is critical, and that there’s still much room for improvement. We’ll cover some of these results in this blog post.
Is time-to-accuracy a good metric?
Time-to-accuracy is stable
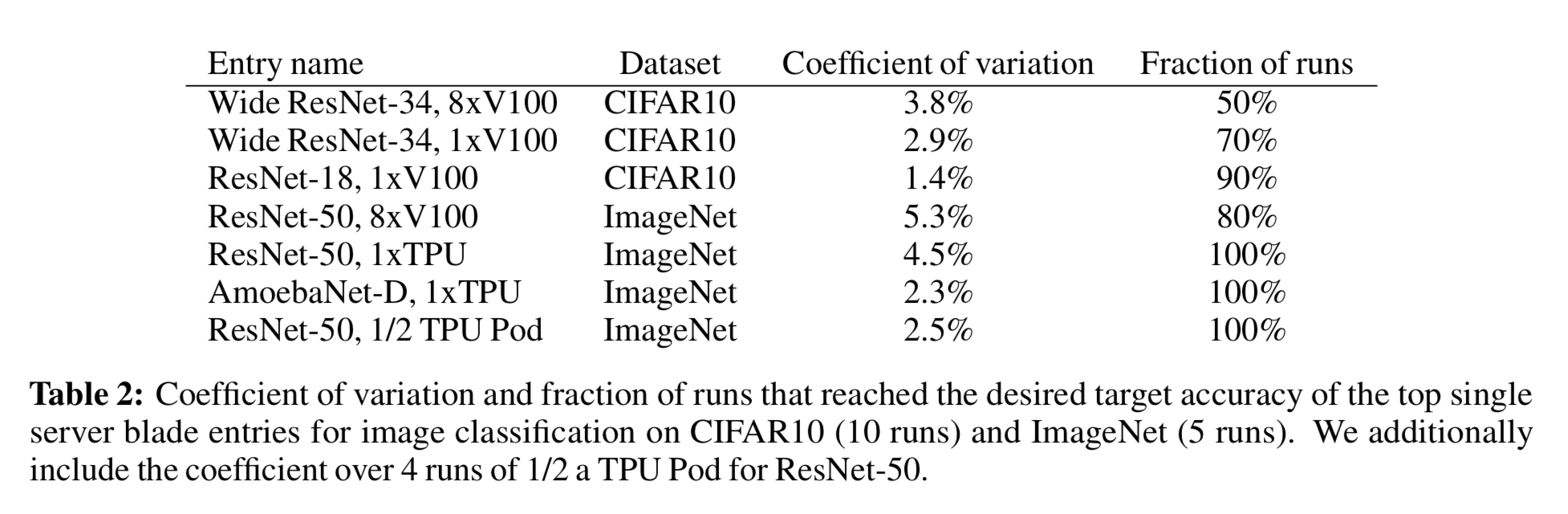
To test the stability of time-to-accuracy, we ran multiple runs for the top single server blade DAWNBench entries for both the CIFAR10 and ImageNet tasks, and computed the coefficient of variation across the runs. We also computed the fraction of runs that satisfy the accuracy threshold (94% top-1 accuracy for CIFAR10 and 93% top-5 accuracy for ImageNet). The entries almost always reach the provided accuracy threshold; the CIFAR10 Wide ResNet-34 entries use cyclic learning rates, which seems to hurt stability. In addition, the coefficient of variation is fairly low across the different entries.
Models optimized for time-to-accuracy generalize well
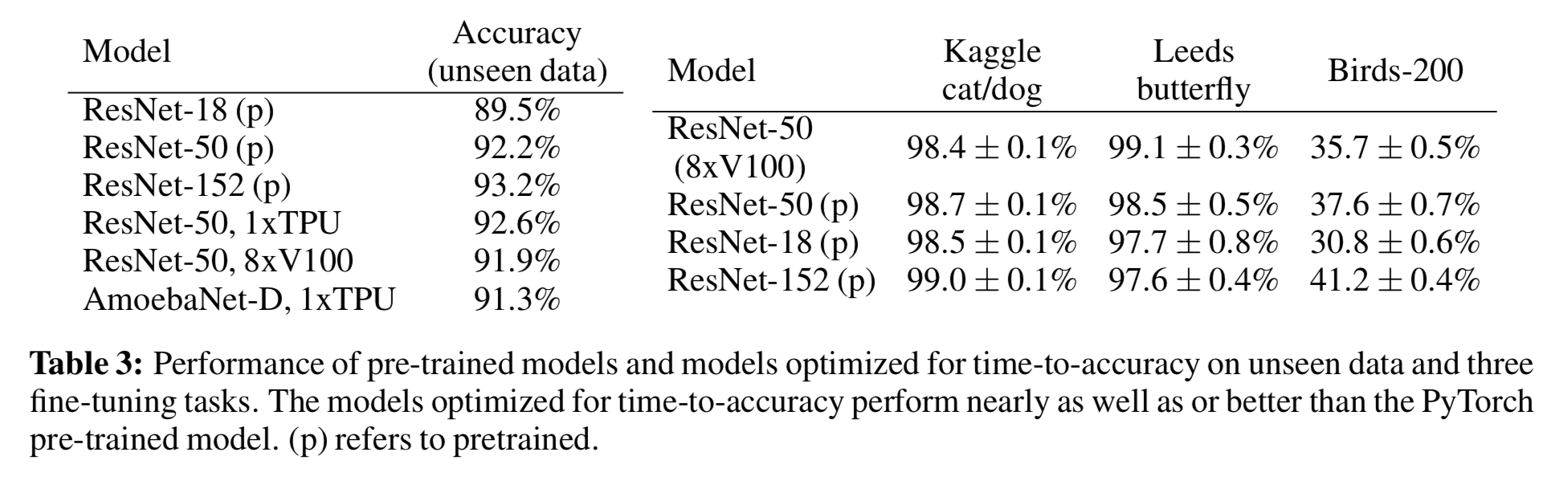
We evaluated the generalization ability of models optimized for time-to-accuracy on a set of ~2800 images we crowdsourced ourselves from Flickr. We observed that the models optimized for time-to-accuracy achieve about the same top-5 accuracy as the pre-trained ResNet-50 model provided by PyTorch. In addition, these models all achieve a higher top-5 accuracy than the pre-trained ResNet18 model and a lower top-5 accuracy than the pre-trained ResNet-152 model.
We also evaluated one of the ImageNet entries optimized for time-to-accuracy on three fine-tuning tasks, where the weights of the convolutional layers are kept fixed and not modified, and the only weights modified are those belonging to the final fully connected layer. The optimized model performs 1.87% worse on Birds-200, which is the hardest task, but nearly the same on Kaggle cat/dog and Leeds butterfly, indicating that models optimized for time-to-accuracy generalize as well as models that are not.
The accuracy threshold is critical
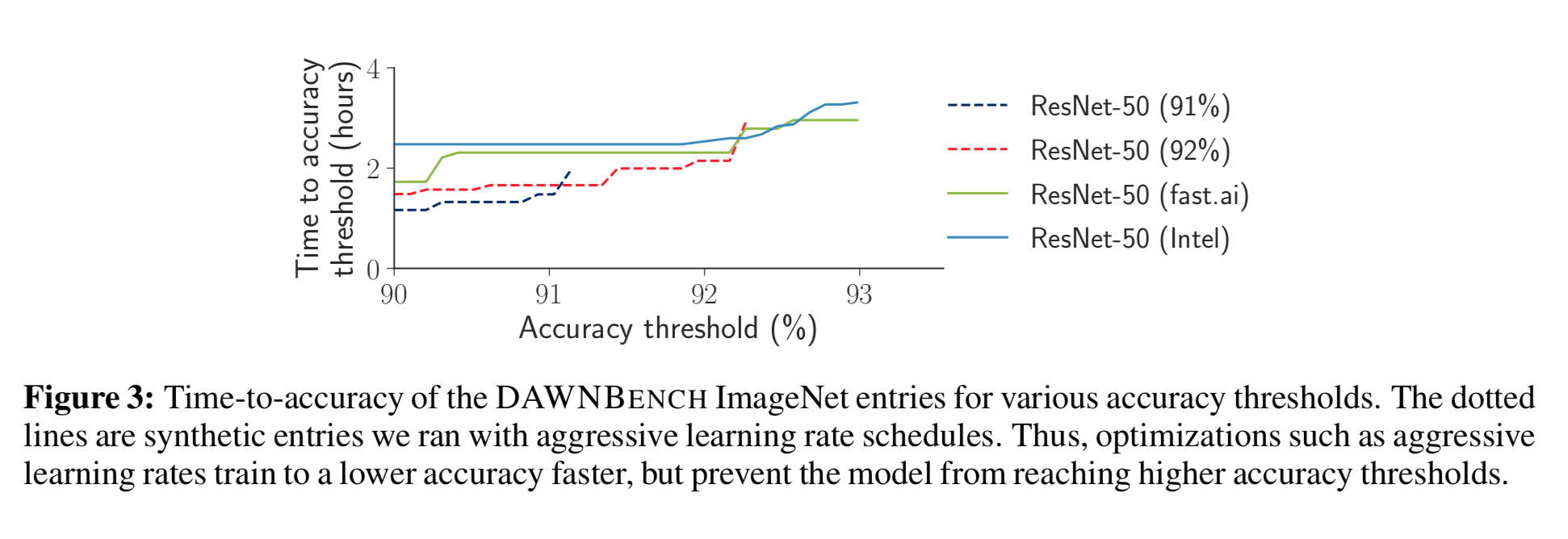
To study the effect of threshold on time-to-accuracy, we plot time-to-accuracy for different top-5 accuracy thresholds ranging from 90% to 93% for ImageNet image classification. We pick two submitted DAWNBench entries, one from fast.ai and another from Intel. In addition, we also show results for ResNet models that use accelerated learning rate schedules to reach 91% and 92% top-5 accuracies as fast as possible. We note that it is possible to optimize for lower accuracy thresholds, but doing this can prevent the models from reaching higher accuracy thresholds. Thus, if the goal is to produce a high-quality model as fast as possible, it’s important to set the accuracy threshold high, because otherwise, we can open ourselves up to a number of optimizations that tradeoff a fair bit of accuracy for improved throughput.
What can we learn from the DAWNBench v1 results?
Software, hardware, and statistical optimizations are all necessary for good performance
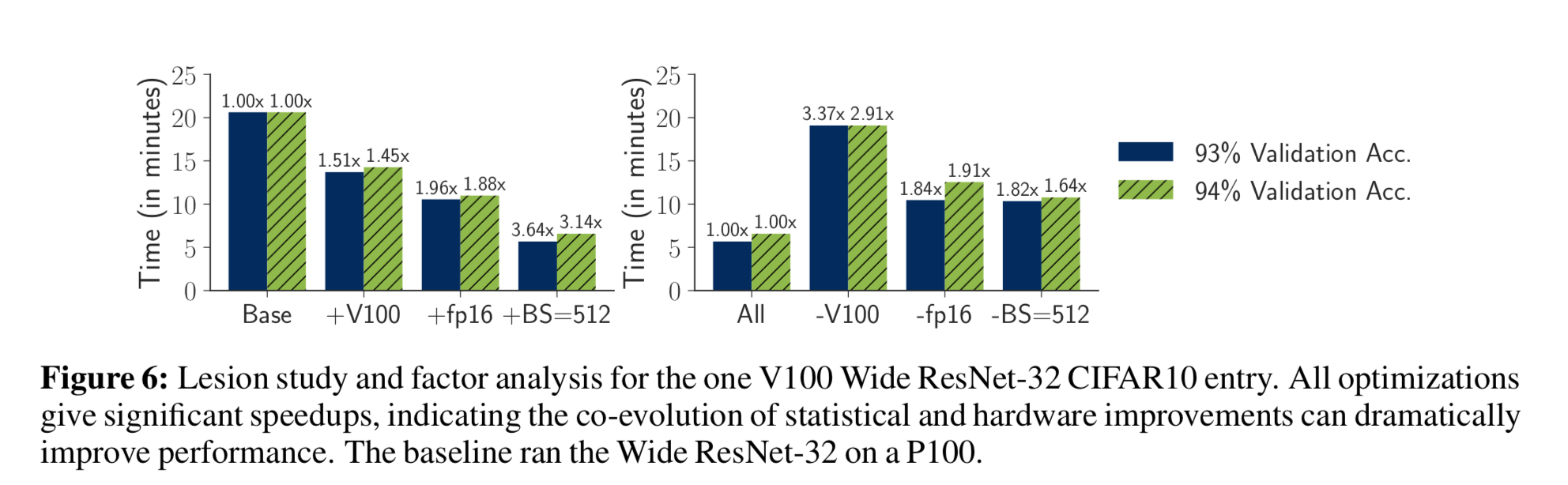
To study the different optimizations used in the DAWNBench entries, we performed a lesion study and factor analysis on the top CIFAR10 entry. We observed that achieving high performance requires a range of software (support for low precision arithmetic and cyclical learning rates), hardware (fp16 processing units), and statistical optimizations (large minibatch training with learning rate warmup).
Deep Learning training often scales poorly
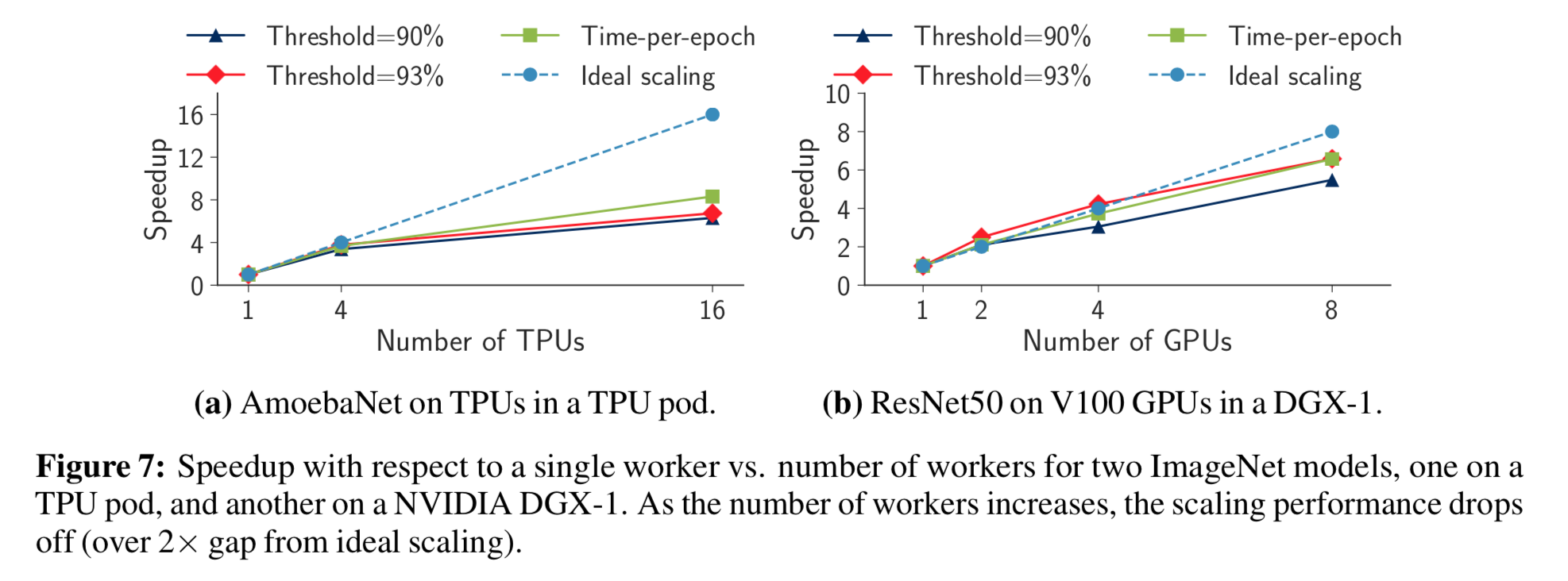
A number of the ImageNet entries achieved speedups by scaling to larger numbers of machines. To study this further, we plot speedup in time-to-accuracy and time-per-epoch on an AmoebaNet model that uses a TPU Pod and a ResNet-50 model on V100 GPUs in a Nvidia DGX-1. The AmoebaNet model scales poorly, as can been seen in the figure below. The ResNet-50 model, on the other hand, scales much better. We also observed ResNet-50 was able to use a maximum minibatch size twice as large as AmoebaNet and consequently more TPUs while still converging to the target accuracy threshold, indicating that learned architectures could be more sensitive to hyperparameters like minibatch size.
Current Deep Learning frameworks underutilize modern hardware
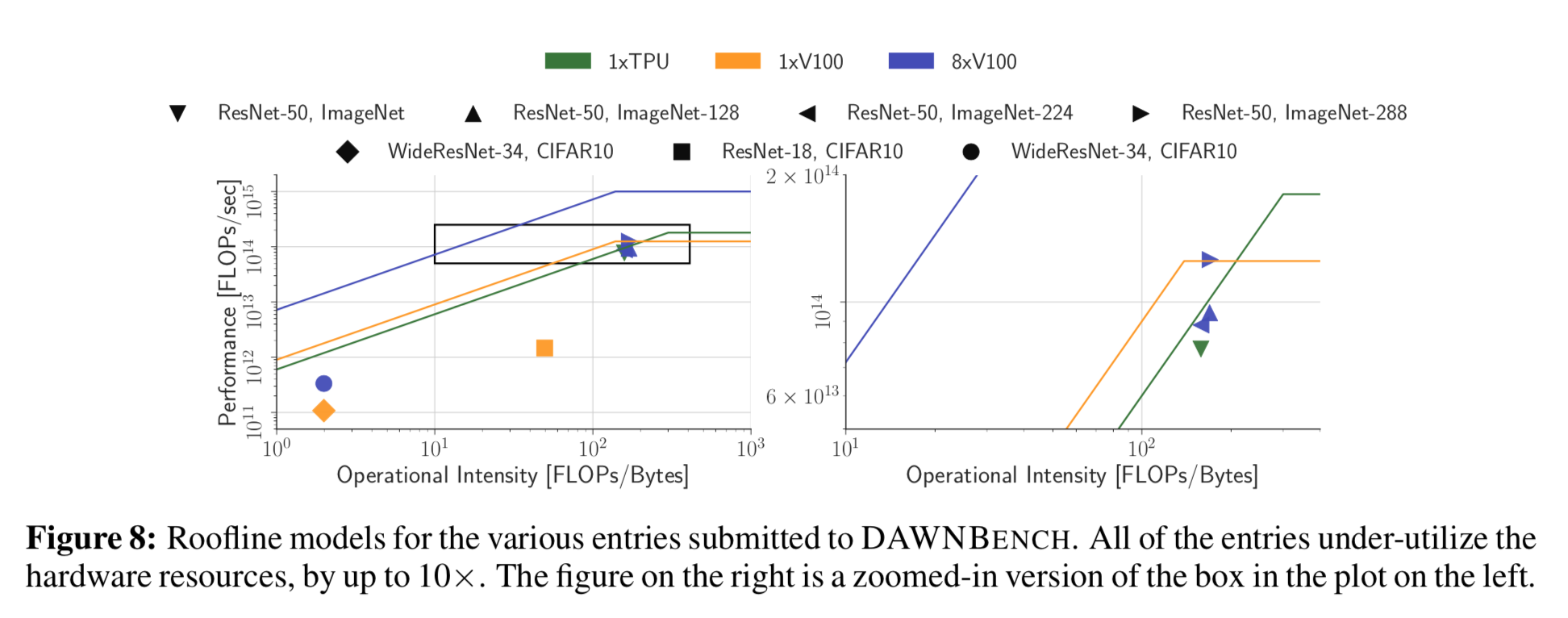
To further study the hardware performance of various entries, we use the roofline model and plot computational throughput (in floating point operations per second) against the operational intensity of the application (number of floating-point operations performed per DRAM byte accessed). Applications with high operational intensity are “compute-bound”, while applications with low operational intensity are “memory-bound”.
All analyzed entries severely underutilize the available compute resources – each point achieves a throughput significantly lower than the peak device throughput. All analyzed CIFAR10 models operate in low operational intensity regimes, partially because of the small input size (32x32). The ImageNet entries do a better job of utilizing hardware, but still are as much as a factor of 10x away from peak device throughput for the GPUs. We suspect that the entries that use the V100s do not fully use the Tensor Cores, which are advertised to deliver 125 Teraflops of half-precision arithmetic. The TPUs are better utilized, with a utilization of 45% for the ResNet-50 model, and 31% for the AmoebaNet model (not pictured in Figure 8).
What’s next?
Building on our success and experience with DAWNBench, we have joined forces with several academic and industry organizations to form MLPerf in an effort to evaluate an extended set of tasks using the time-to-accuracy metric. Based on the results above, focusing on the trade-offs between hardware and statistical performance will set valuable future directions for systems and research in this space. For more details and results, see our preprint.