There and Back Again: A General Approach to Learning Sparse Models
Sparse models – models where only a small fraction of parameters are non-zero – arise frequently in machine learning. Sparsity is beneficial in several ways: sparse models are more easily interpretable by humans, and sparsity can yield statistical benefits – such as reducing the number of examples that have to be observed to learn the model. In a sense, we can think of sparsity as an antidote to the oft-maligned curse of dimensionality.
In a recent paper, we ask: can we use the sparsity of a model to improve computational efficiency during training? For example, if we wish to train a sparse, high-dimensional logistic regressor, or compute a non-negative factorization of a matrix or tensor, can we exploit a priori knowledge of the target sparsity to train our high-dimensional model more quickly? Perhaps surprisingly, we can do so by performing a simple procedure: compress the original data to a lower-dimensional space, learn a dense model in the low-dimensional space, then apply a sparse recovery method to obtain an approximate solution to the problem in the original, high-dimensional space. This approach — which we call “There And Back Again” — is not only conceptually simple but also yields substantial speedups in training time, as it requires solving a lower dimensional problem.
There and Back Again
More formally, suppose we’re given data X on which we want to run an optimization algorithm F to obtain a model W = F(X). We might think of F as stochastic gradient descent for learning a logistic regressor, or alternating least-squares for non-negative matrix factorization (NMF). If X is high-dimensional, this procedure can be expensive both in time and memory. But if our target model W is sparse, we can instead run our optimization routine F on a compressed, lower-dimensional version of the data X’ = PX, where P is a random projection matrix. This yields a compressed solution W’ = F(X’). We can then leverage classic methods from compressive sensing to recover an approximate solution Wapprox in the original, high-dimensional space such that Wapprox ≈ W. This procedure is summarized in Figure 1. In short, instead of solving the original high-dimensional problem, we solve a low-dimensional surrogate problem and use the result to recover an approximate sparse solution in the original space.
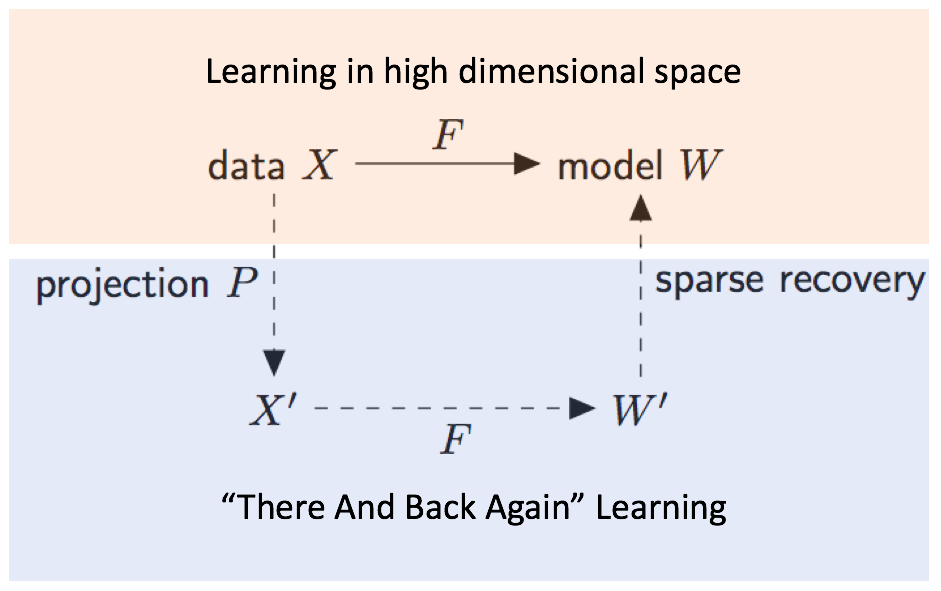
It’s not immediately clear that this “There and Back Again” scheme should work at all. It is well-known that appropriately-generated random projections (for example, random Gaussian matrices) can preserve geometric properties like pairwise Euclidean distances and inner products. But it’s not obvious that these projections should preserve the solutions to non-convex optimization problems such as NMF. In other words, we need to show that the solution to the low-dimensional compressed problem is a compressed version of the solution to the original, high-dimensional problem. In the paper, we prove that for appropriately-chosen random projections, this property holds for NMF under mild sparsity assumptions. This result brings together two areas of research that have seen significant progress over the last two decades – random projections and compressive sensing.
Experiments
How effective is this method in practice? Using the Enron email corpus, we can form a word-document matrix where each row consists of word counts in a particular email. This results in a matrix of size 39,861×28,102 (# documents × vocabulary size). Computing an NMF of this matrix corresponds to finding a clustering of this data, where emails that use similar words are grouped into common “topics”. We perform “There And Back Again” learning on this matrix and calculate the correlation between the factors recovered using our procedure and the factors from the original matrix.
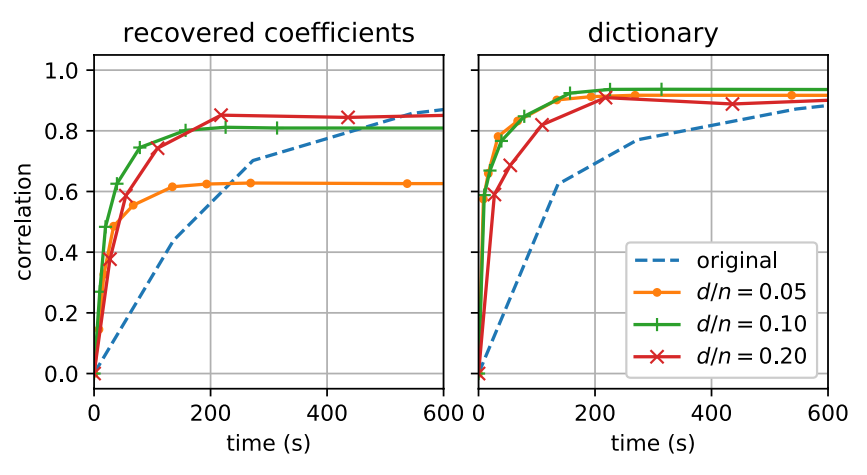
Figure 2 illustrates the results, and provides an example of the benefits of our procedure. Here n is the original dimension and d is the projected dimension, hence setting d/n = 0.1 corresponds to using “There And Back Again” with a random projection onto a 0.1n dimensional space. Figure 2 (right) shows that our approach recovers the words corresponding to each topic (i.e., the “dictionary” factor, as it is commonly referred to in the matrix factorization literature) much faster than factoring the original matrix — for a given correlation we require a much smaller compute time. Additionally, Figure 2 (left) demonstrates that we are also able to recover an approximation to the coefficient factor (which is the assignment of the individual documents to topics) with computational savings. In Figure 2 (left), we can also see that there’s a trade-off between the degree of compression (e.g., d/n = 0.1 corresponds to 10x compression), and the quality of the recovered approximation.
As the above experiments show, running the optimization algorithm in the compressed, lower dimensional space yields significant computational savings. However, this procedure comes at the cost of computing the random projection X’ = PX, and performing sparse recovery for the compressed parameters of interest. For the random projections, we show both theoretically and empirically that sparse random projections, which can be efficiently applied to data, are sufficient. For sparse recovery, we find that fast reconstruction techniques like sequential sparse matching pursuit can achieve good results. In general, these methods are much faster than those based on solving optimization problems (e.g., lasso or linear program formulations), albeit at the cost of reduced reconstruction accuracy.
Our arXiv paper has more details on our results, including proofs of our theoretical guarantees and several additional experiments. In summary, we think that this work provides a useful conceptual and computational framework for learning sparse models, and is a promising example of the interplay between random projections and sparse recovery.