Don't Throw Out Your Algorithms Book Just Yet: Classical Data Structures That Can Outperform Learned Indexes
There’s recently been a lot of excitement about a new proposal from authors at Google: to replace conventional indexing data structures like B-trees and hash maps by instead fitting a neural network to the dataset. The paper compares such learned indexes against several standard data structures and reports promising results. For range searches, the authors report up 3.2x speedups over B-trees while using 9x less memory, and for point lookups, the authors report up to 80% reduction of hash table memory overhead while maintaining a similar query time.
While learned indexes are an exciting idea for many reasons (e.g., they could enable self-tuning databases), there is a long literature of other optimized data structures to consider, so naturally researchers have been trying to see whether these can do better. For example, Thomas Neumann posted about using spline interpolation in a B-tree for range search and showed that this easy-to-implement strategy can be competitive with learned indexes. In this post, we examine a second use case in the paper: memory-efficient hash tables. We show that for this problem, a simple and beautiful data structure, the cuckoo hash, can achieve 5-20x less space overhead than learned indexes, and that it can be surprisingly fast on modern hardware, running nearly 2x faster. These results are interesting because the cuckoo hash is asymptotically better than simpler hash tables at load balancing, and thus makes optimizing the hash function using machine learning less important: it’s always great to see cases where beautiful theory produces great results in practice.
Going Cuckoo for Fast Hash Tables
Let’s start by understanding the hashing use case in the learned indexes paper. A typical hash function distributes keys randomly across the slots in a hash table, causing some slots to be empty, while others have collisions, which require some form of chaining of items. If lots of memory is available, this is not a problem: simply create many more slots than there are keys in the table (say, 2x) and collisions will be rare. However, if memory is scarce, heavily loaded tables will result in slower lookups due to more chaining. The authors show that, by learning a hash function that spreads the input keys more evenly throughout the table, they can produce more space-efficient tables (with a high percent of slots loaded) that are still fast to access.
In more detail, the authors implemented hash tables using separate chaining for collisions, and compared a standard (random) hash function with a learned one. They report the access time, memory occupied by empty slots, and percent of slots empty for tables with different numbers of slots (from 0.75x to 1.25x the number of keys):
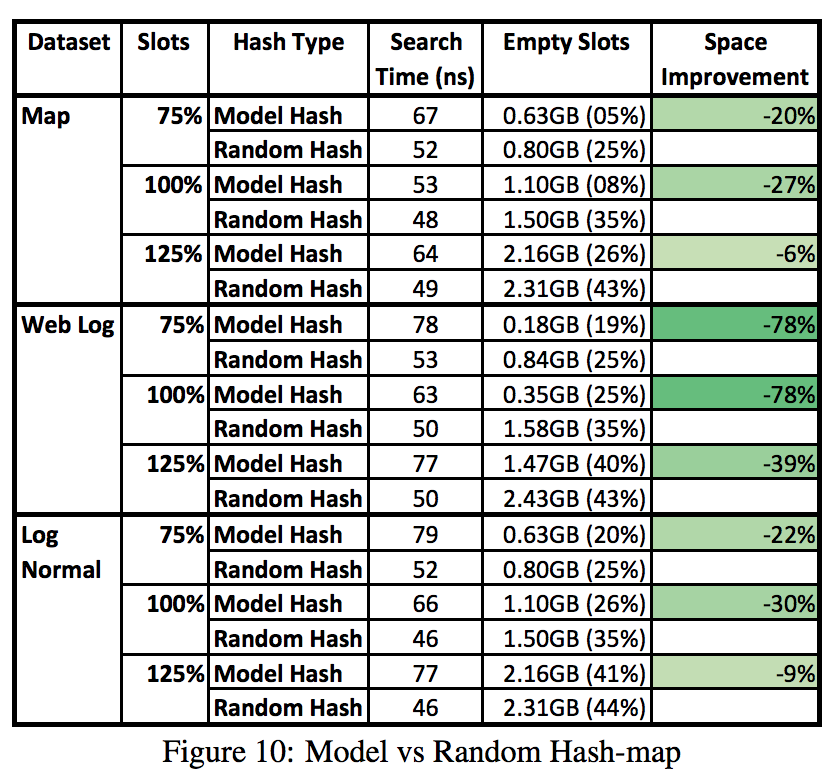
Spreading the input keys definitely helps the simple separate chaining hash table use less space, but can we do better? In fact, other data structures can be asymptotically better at high load. As an example, we implemented bucketized cuckoo hashing, a simple and beautiful technique that can achieve 99% occupancy and serve all lookups with just two memory accesses thanks to the power of two choices. Unlike the learned indexes in the paper, cuckoo hashing doesn’t require a training step, and it supports arbitrary changes to the key distribution at runtime, making it easy to apply in many systems. The key idea is just to map each key to two possible buckets and place it in the least loaded one, which, it turns out, can achieve very high loads while retaining amortized O(1) inserts and worst-case O(1) lookups. On modern hardware, we found that cuckoo hashing can also be extremely fast—perhaps surprisingly, even outperforming separate chaining in some cases.
We implemented a SIMD-friendly bucketized cuckoo hash table with 32-bit integer keys and values (which we confirmed were used in the learned indexes paper) that we’ve posted on GitHub. We stored eight keys per bucket that we search using AVX2, and used the finalization step of Murmur3 as our hash function, which costs the same as the random hash function in the paper (2 multiplications, 3 shifts and 3 XORs). We ran experiments on the two datasets from the paper that are publicly available: OpenStreetMap and log-normal data. We used an Intel Xeon E5-2690v4 CPU @ 2.6GHz for our experiments, but found nearly identical numbers on other CPUs on AWS (c4.8xlarge, Xeon E5-2666v3 @ 2.9GHz and m4.16xlarge, Xeon E5-2686v4 @ 2.3GHz). Overall, we obtained the following results:
- Map data: our table took 36ns per access while wasting just 0.015GB of space (1% of slots).
- Log-normal data: our table took 36ns per access while wasting 0.015GB of space (1% of slots).
As we can see, both the access time and memory overhead are significantly improved. In particular, even for separate chaining tables with only 0.75 slots per key, the learned hash functions still leave between 5% and 20% of slots empty. Instead, our table only leaves 1% of slots empty while cutting the access time nearly in half. The high level takeaway is that cuckoo hashing is asymptotically better than separate chaining for load balancing. With chaining, collisions can result in arbitrarily long chains, the longest of which is O(log n / log log n) on average for n keys. Even the learned hash functions do not seem to spread data around evenly enough to mitigate this. With cuckoo hashing, there are always at most 2 memory lookups per key, even with random hash functions.
Finally, to make sure that our hardware is not dramatically different, we also implemented a separate chaining hash table as described in the paper. This table took 48ns per lookup when configured with number of slots equal to the number of keys, which is close to the random hash performance in the paper. We were able to optimize it to 42ns per lookup using the fast alternative to modulo trick from Daniel Lemire that we used in our own table, but even then, it was slower than our 99%-occupied cuckoo table. This difference surprised us, because the separate chaining table should be making fewer memory acceses per key than the cuckoo table on average, but one reason it can happen on modern hardware is indirect accesses: in separate chaining, following the linked list of items in each slot requires the CPU to wait to read each node in order to discover the next pointer, whereas in cuckoo hashing, the addresses of both cells that a key maps to are computable before doing any memory accesses, so the CPU may speculatively fetch both addresses. We definitely hope processor vendors don’t take away our speculative execution!
Closing Thoughts
Does all this mean that learned indexes are a bad idea? Not at all: the paper makes a great observation that, when cycles are cheap relative to memory accesses, compute-intensive function approximations can be beneficial for lookups, and ML models may be better at approximating some functions than existing data structures. The idea of self-tuning data structures is also exciting. Our main message, though, is that there are many other ideas that tackle the indexing problem in creative ways, and we should make sure to take advantage of these insights, too. In the case of hashing, cuckoo hash tables are asymptotically better due to a deep algorithmic insight, the power of two choices, that greatly improves load balance. In other domains, ideas such as adaptive indexing, database cracking, perfect hashing, data-dependent hashing, function approximation and sketches also provide powerful tools to system designers, e.g., by adapting to the query distribution in addition to the data distribution. It will be exciting to compare and combine these ideas with tools from machine learning and the latest hardware.
We thank the authors of the learned indexes paper for their feedback on a draft of this post.