Introducing DAWNBench: An End-to-end Deep Learning Benchmark and Competition
Deep learning has shown amazing results in tasks ranging from image classification to question answering to machine translation, but these models are extremely costly to train. To optimize performance, the deep learning community has developed new software systems, training algorithms, and hardware to optimize deep learning performance.
Unfortunately, it’s hard to compare these different optimizations due to a lack of a standard criterion for end-to-end deep learning performance. While there are several existing benchmarks, these benchmarks measure only proxy metrics, such as the time to process one minibatch of data, that don’t always map to faster time to convergence to a high-quality result. This lack of standard evaluation criteria make it hard to understand the tradeoffs between techniques. For example, meProp can speed up training by 3.1x and 8-bit precision can speed up training by 3x, on MNIST. Will combining these techniques give a 9.3x speed increase? Can these techniques combine with large mini-batch SGD and train an ImageNet model in 7 minutes? If so, how will this affect the final accuracy? Many existing benchmarks measure only throughput, and do not even report the final accuracy.
To fill this gap, we are excited to introduce DAWNBench, the first deep learning benchmark that measures end-to-end performance: time/cost required to achieve a state-of-the-art accuracy level for common deep learning tasks, as well as inference latency/cost at this state-of-the-art accuracy level. Additionally, we will run DAWNBench as a competition, with the first deadline on April 20, 2018, 11:59 PST. As deep learning research and practice evolves, we will update and regularly run the competition, similar to ImageNet.
To submit, see our website for more details!
Why End-to-End Performance?
DAWNBench measures end-to-end performance to achieve a state-of-the-art accuracy for a problem. Why this metric? Let’s consider a simple hyperparameter: the minibatch size. Increasing minibatch size improves hardware throughput, but prior work has also shown that too too large of a minibatch size can lead to poor final validation accuracy (i.e. poor convergence). We ran an experiment where were varied the minibatch size, while scaling the learning rate according to best practices, and found the results below:
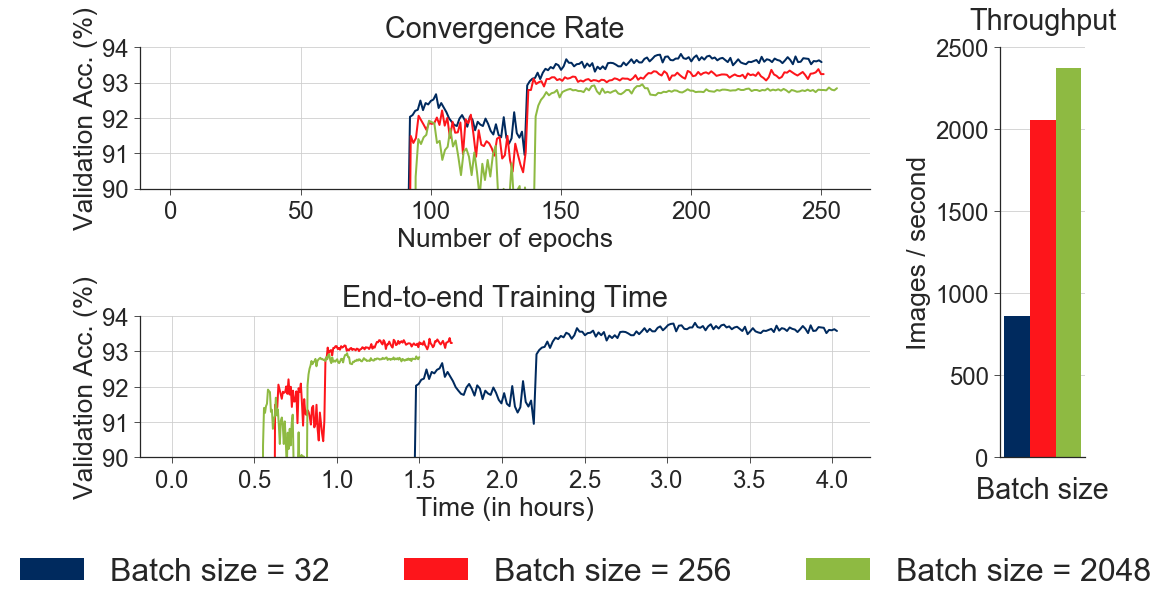
As we can see, a larger minibatch size gives better throughput in terms of images processing per unit time, but lower final validation accuracy! Thus, even a simple hyperparameter can dramatically affect both the convergence rate and hardware performance.
A Tour of DAWNBench
In the first iteration of DAWNBench, we focus on two tasks: image classification and question answering. For each task, we benchmark both the performance of training (e.g. time or cost) and the performance of inference (e.g. latency or cost), at a specified (high) accuracy level. By measuring the end-to-end performance to achieve a specific state-of-the-art validation accuracy, DAWNBench provides an objective way to normalize across frameworks, hardware, models, optimization algorithms, and a variety of other factors.
For image classification, our initial release measures training and inference on CIFAR10 and ImageNet. For question answering, we use the SQuAD competition. For each task and metric, we have seeded the benchmark with reference implementations of different models.
Over time, as we receive community input, we plan to expand the scope of DAWNBench with additional tasks (e.g. image segmentation and detection, machine translation) and additional metrics (e.g. power, sample complexity).
Conclusion
We hope that DAWNBench will spur a dialogue between three communities: deep learning researchers, practitioners, and systems architects. Through community submissions and discussions, we hope DAWNBench will be a guide for practitioners and researchers to decide what hardware to use, and hardware architects to decide which model architectures to test their hardware on. Please submit and join the Google group!