Accelerating Queries over Unstructured Data with ML, Part 2 (Approximate Selection Queries with Statistical Guarantees)
In this blog post, we’ll describe our recent work on approximate selection queries with statistical guarantees. While this blog post will be self-contained, please see our other blog posts for other exciting developments and more context (part 1)!
As we described in part 1, unstructured data records (e.g., videos, text) are becoming increasingly possible to automatically query with the proliferation of powerful deep neural networks (DNNs) and human-powered labeling services (which we collectively refer to as “oracle methods”). As a running example, we are collaborating with researchers in the Stanford biology department. They have collected hundreds of days of field video and are interested in finding hummingbird visits to match with field microbe recordings.


Unfortunately, exhaustively annotating all of this data is too expensive: human annotation would cost hundreds of thousands of dollars. Since exhaustive annotation is too expensive, our collaborators are willing to trade off approximate selection, in the form of finding 80% of the frames with hummingbirds (i.e., 80% recall). In executing such queries, a critical requirement for scientific analysis is achieving a statistical guarantee on the recall. These guarantees are of the form “the resulting set of records will have 80% recall 95 out of 100 times when executing the query.” These statistical guarantees are required for scientific analysis and are similar to guarantees used in related work.
Prior work (including ours, see our blog post on NoScope) aims to accelerate these queries by using proxy models, which are cheap approximations to oracle methods, but fails to achieve statistical guarantees, which we illustrate below. To see that naive methods fail to achieve statistical guarantees on query accuracy, we show the precision of 100 runs of finding hummingbirds in the ImageNet dataset below, with a target precision of 90%. As we can see in the box-and-whiskers plot, naive algorithms of using proxy scores fail to achieve the target accuracy over half the time and can in fact return precisions as low as 20%, far below the target.
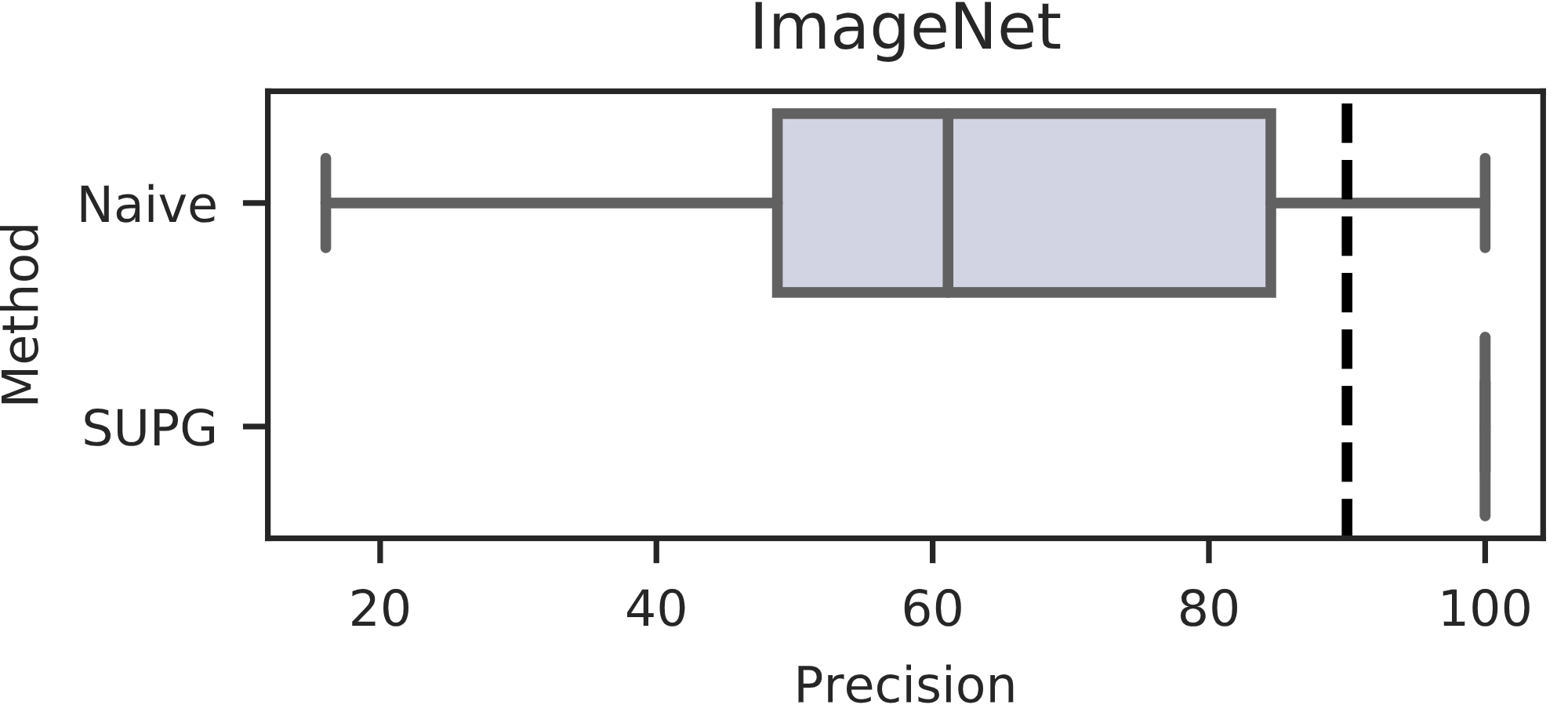
This prior work uses proxy models to generate proxy scores, which represents some uncalibrated likelihood that a given data record satisfies the oracle predicate. While naive algorithms fail to achieve statistical guarantees, we’ll show that they can be corrected to achieve guarantees.
In the remainder of this post, we’ll describe query semantics of approximate selection queries with guarantees, how to achieve these guarantees, and how to improve query results.
Query Syntax and Semantics
To allow users to specify approximate selection with guarantees (SUPG queries), we provide syntax that inherits from SQL. We show an example below of the hummingbird query.
SELECT frame FROM bush_video
WHERE HUMMINGBIRD_PRESET(frame)
ORACLE LIMIT 10,000
USING MASK_RCNN(frame)
RECALL TARGET 90%
WITH PROBABILITY 95%
The critical way that our work differs from prior work is we enforce a probability of success. Intuitively speaking, for a 95% probability of success, if the query is executed 100 times, we want the recall/precision target to be achieved at least 95 times. These guarantees are similar to ones provided by other systems for approximate aggregation queries, but are new to approximate selection queries.
Finally, in order to avoid trivial solutions (e.g., returning the entire dataset, which would achieve 100% recall), we specify that queries should return as high of a precision as possible.
Achieving Statistical Guarantees
As we showed above, naive methods of using proxy scores fail to achieve statistical guarantees on query accuracy. To understand why, we’ll give an overview of the algorithmic procedure behind these algorithms and describe where issues arise.
All algorithms (including prior work and ours) follows the same basic procedure:
- Exhaustively generate proxy scores on all data records.
- Sample the oracle predicate on a subset of the records.
- Use these samples to select a threshold proxy score.
- Return all records with proxy score above the selected threshold.
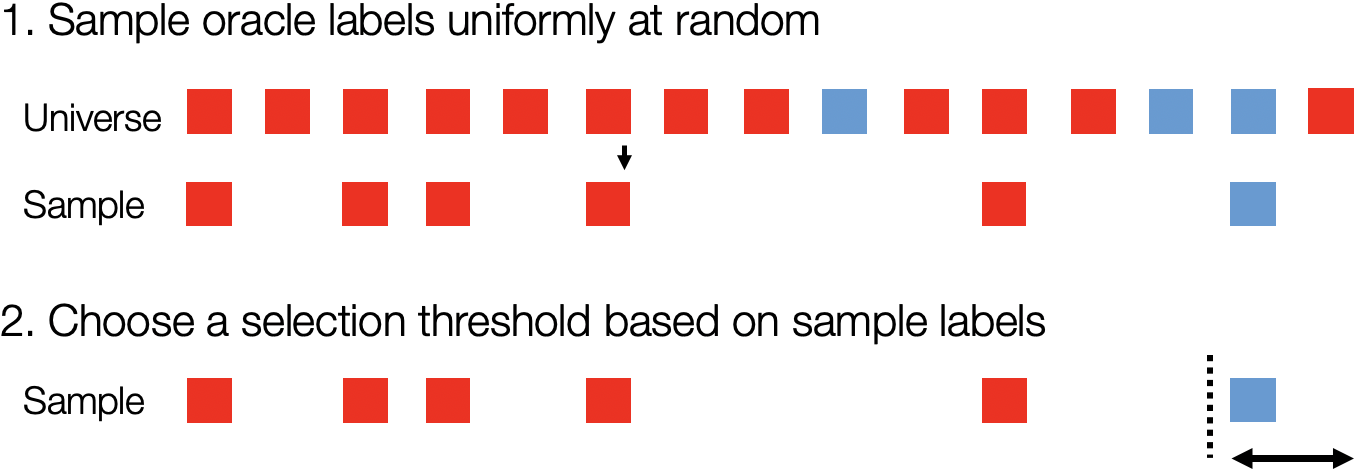
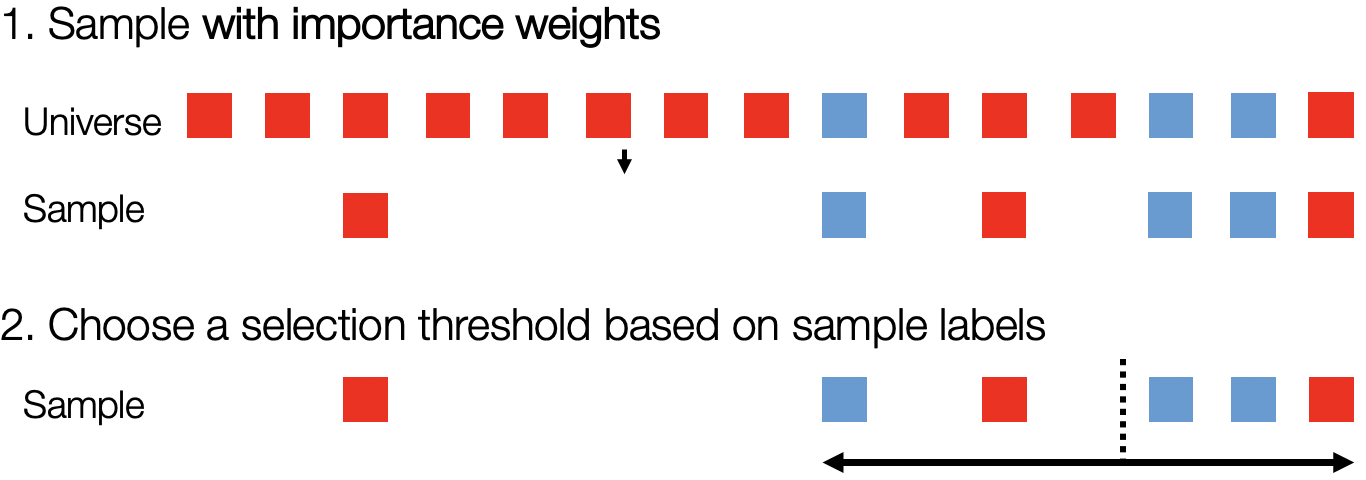
To understand why the naive method fails, let’s consider a stylized example for a 60% recall target. In the diagram below, blue records match the oracle predicate, red records do not match the oracle predicate, and the records are ordered by score. In this stylized example, we show a set of records sampled uniformly at random and the empirical 60% cutoff in the sample. As we can see, 60% in the sample does not reflect 60% in the entire dataset! This example holds in further generality: the naive algorithm does not account for randomness in sampling and will fail with high probability.
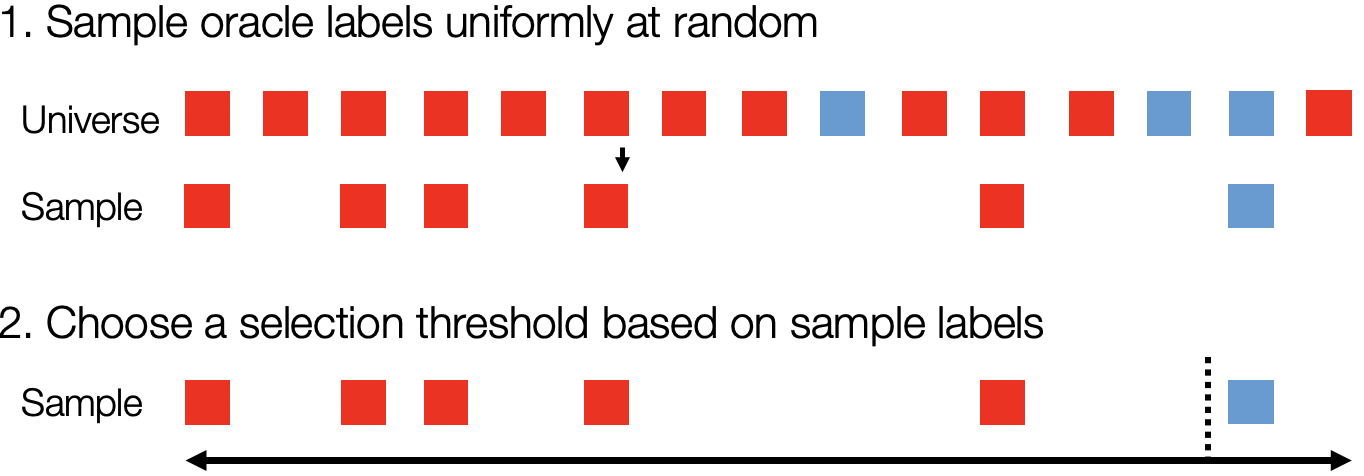
To correct for the randomness in sampling, we use confidence intervals to bound the probability of failure. Returning to the same example from before, we would draw the empirical threshold in the sample as below. However, instead of simply returning records above this empirical threshold, we form a confidence interval over 60% recall in the entire dataset.
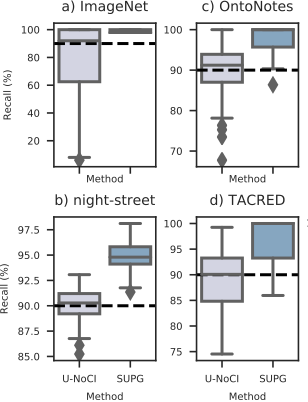
To see how our algorithms compare to naive algorithms, we show the recall over 100 runs when attempting to achieve 90% recall on four real world datasets. As we can see, the naive method consistently fails, while our algorithms succeed with high probability.
Achieving High-quality Query Results
As we’ve seen, using uniform sampling with confidence intervals results in valid, but poor quality query results. To improve query quality, we use the key property that the proxy gives us information about the oracle: higher proxy scores ideally indicate a higher likelihood of a record matching the oracle predicate.
To take advantage of this property, we use a importance sampling, which samples more where proxy scores are higher. However, our setting differs from the standard importance sampling scheme in that the true quantity (the oracle predicate result) is binary. To account for the different assumptions, we propose a new importance weighting scheme, where we sample proportional to the square root of the proxy scores. We won’t have time to discuss why this is optimal for our setting, but please see our full paper for details!
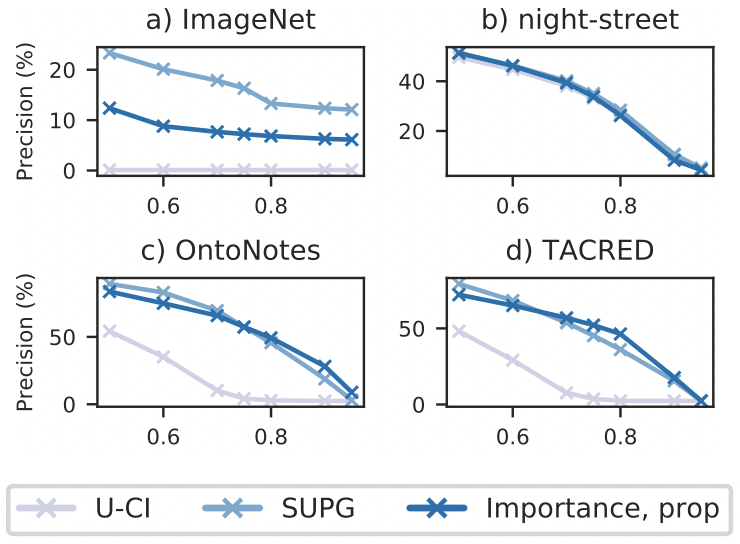
To show the utility of our importance sampling algorithms, we show the query precision for recall target queries on four real world datasets. We vary the recall target and show the resulting precision, with high precision being better. As we can see, importance sampling outperforms uniform sampling in the datasets we considered.
Conclusion
In this blog post, we’ve described our query semantics for approximate selection queries with guarantees and algorithms for efficiently executing these queries. We’ll also be presenting our work at VLDB 2020 this week - please drop by our presentation! Finally, our code is open-sourced and we’re interested in hearing about new applications and use cases; contact us at supg@cs.stanford.edu if you’d like to talk about our work.