Optimizing Data-Intensive Computations in Existing Libraries with Split Annotations
Over the past few years, developers have sought to improve the performance of data science and machine learning applications using JIT compilers such as Weld, TensorFlow XLA, and TorchScript. These compilers have been shown to enable major speedups (up to two orders of magnitude) in applications that use existing high level APIs such as NumPy and pandas. Unfortunately, they are also difficult to implement, debug, and integrate into existing libraries. For example, the Weld compiler requires thousands of lines of code to support an integration with a subset of pandas, and the compiler itself is a complex system with over 40,000 lines of code that implements parsing, optimization, and code generation.
In this post, we introduce a new approach called split annotations that provides similar speedups to JIT compilers without having to modify or reimplement existing library functions, and without having to implement a complex compiler. SAs only require annotating library functions and implementing a small API to obtain many of the benefits of JIT compilers. SAs can improve end-to-end performance in applications that use single-threaded libraries such as NumPy and pandas by up to 11x, can accelerate already optimized parallel libraries such as Intel MKL by up to 4x, and can sometimes match or outperform optimizing JIT compilers such as Weld by 1.5x. They also only require a fraction of the effort to integrate with libraries.
SAs are open source
and available for you to try in your Python applications, with pip install sa
(documentation and getting started guide). To get started, you can try
annotated versions of NumPy and pandas with:
import sa.annotated.numpy as numpy
import sa.annotated.pandas as pandas
Motivation: Why are existing data science applications slow?
Developers combine different libraries (e.g., NumPy, pandas, scikit-learn)
when building their applications. Unfortunately, while each library provides
optimized implementations of their own functions, the performance of an
end-to-end application can still be suboptimal when there is no optimization
between these functions. For example, a reduce in NumPy knows nothing
about a filter in pandas. While both functions may be fast on
their own, combining them requires two separate scans through the data, each
of which will be served through main memory rather than the CPU caches.
It turns out the cost of this data movement between main memory and the CPU is significant: our prior work has shown that many applications that combine functions from existing libraries can run up to 30x slower than an implementation that pipelines data through the CPU cache heirarchy. In addition, many libraries (especially in Python) do not support parallelism, further hindering their performance.
JIT Compilers: A heavyweight approach for end-to-end optimization
JIT compilers are an increasingly popular approach to improving the performance of these applications. Library developers modify their libraries to use such a compiler, e.g,. by emitting code represented in a special intermediate representation (IR) and using a lazy API to make these code fragments visible to each other at runtime. Examples of some recent JIT compilers include Weld (developed by Stanford DAWN), TensorFlow XLA, and TorchScript. In most cases, the applications themselves need not change. These compilers can produce some pretty impressive performance results: for example, Weld can accelerate Black Scholes written in Intel MKL (a highly optimized linear algebra library) by 4x on 16 threads, by performing optimizations such as loop fusion over its IR to reduce data movement (see figure below).
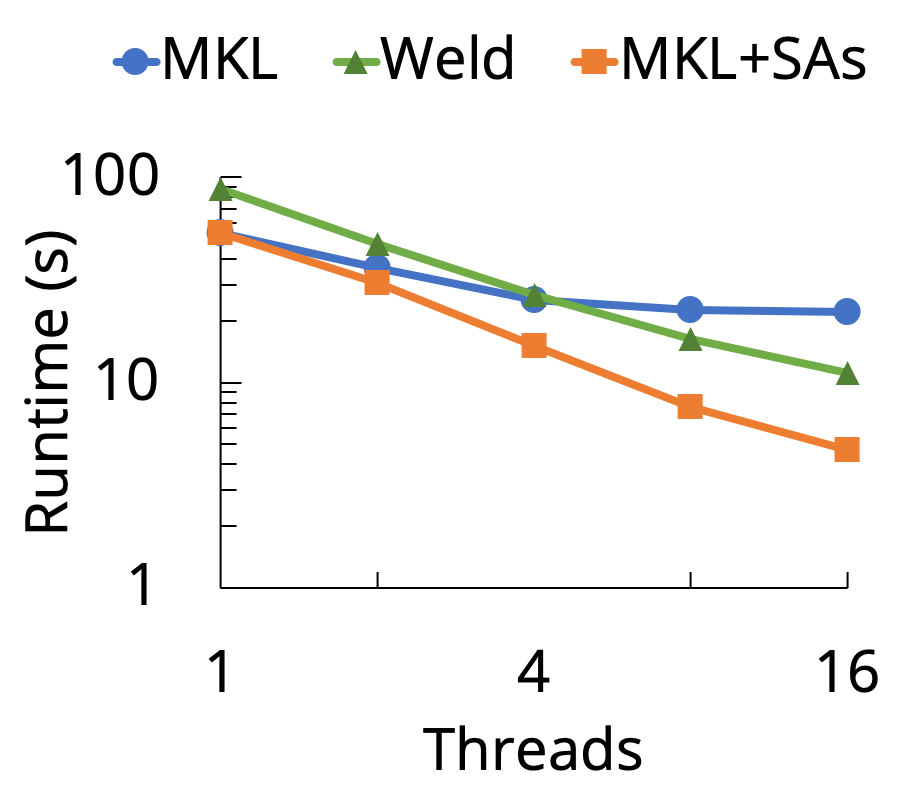
Unfortunately, the developer cost of using these compilers is often prohibitively high. Many of these libraries have large codebases and already contain meticulously optimized code. Rewriting these libraries in a custom IR for a compiler that may not even support all the existing optimizations seems like a big ask!
Split annotations (SAs) are a new way to parallelize functions and to enable data movement optimizations in existing libraries with no library code changes: they only require adding annotations to existing functions. Here is an SA for one of the C MKL functions used in the Black Scholes workload mentioned above:
@sa (n: SizeSplit(n), a: ArraySplit(n), b: ArraySplit(n), out: ArraySplit(n))
void vdAdd(MKL_INT n, double *a, double *b, double *out);
The plot above also shows the performance after annotating the MKL functions in Black Scholes with SAs. On this application, SAs improve performance over un-annotated MKL by 5x on 16 threads, and also outperform the optimizing Weld compiler by leveraging MKL’s optimized function implementations (whereas Weld tries to compile its own implementations from its IR).
Split annotations: data movement optimizations without rewriting libraries
How do SAs work? Fundmentally, an SA tells an underlying runtime how to split inputs to a function into smaller, cache-sized chunks. By splitting data, we can:
- Pipeline data by collectively passing cache-sized chunks through a series of functions in an application, thus decreasing data movement. This is because each function loads data from the CPU caches rather than from main memory.
- Parallelize existing functions by using the runtime to call the function on several splits of the data in parallel.
To understand how SAs achieve these goals, lets take a closer look at the split
annotation for the MKL vdAdd function above, which adds arrays elementwise.
The function takes four arguments:
- a size
n, - the two input arrays
aandb, - the output array
out, where the result is written
The annotation specifies how to split data using a new concept called split
types. Split types provide user-defined functions for splitting (and merging)
data in a library (e.g., “splitting” the size by computing the size of a split
element, or splitting an array by bumping a pointer). For example, the size is
split via a function defined for the split type SizeSplit(n), and each array
is split using a split type called ArraySplit(n); both take the size
n as an argument when splitting arrays.
Apart from specifying how to split data, split types provide other nice properties as well, such as ensuring we don’t end up passing “incompatible” split data into a function together (e.g., arrays split into different lengths). We won’t go into too much details on split types here, but you can read more about their properties in our research paper. You can also see all the annotations for MKL and their splitting and merging functions on GitHub.
Finally, note that we don’t actually need access to the library function code to write SAs; we just need to understand what the function does, e.g., by reading its documentation.
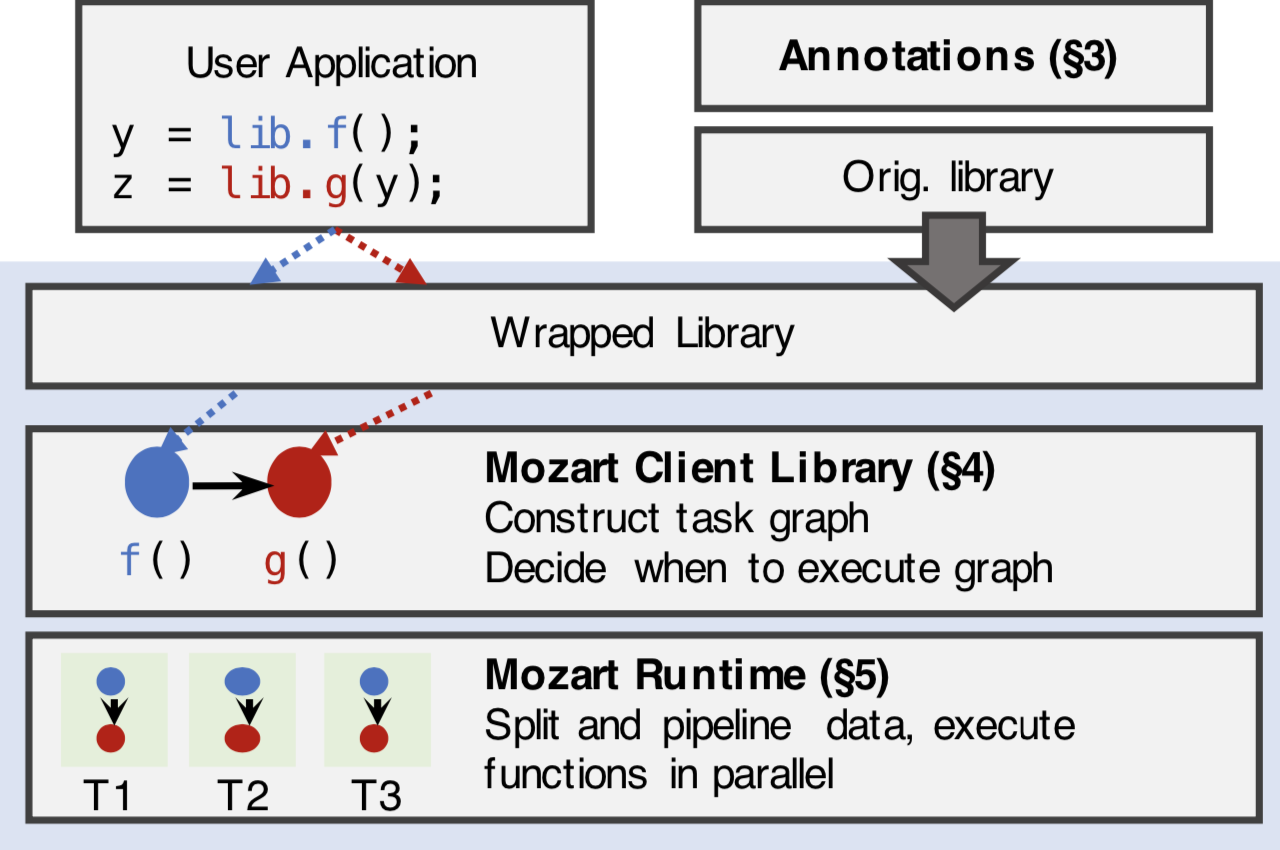
After writing SAs, when annotated functions are being called at runtime, the SA runtime (called Mozart, named after our favorite composer, since we’re composing functions…) kicks in. Mozart uses wrapper code generated when the SA is added to lazily register functions in a task graph. When lazy values to be computed by the task graph are accessed, Mozart automatically detects that it needs to compute values, and will use the split types and SAs to split data, parallelize it, and pipeline it through all the functions in the task graph. In C, Mozart uses memory protection in to detect accesses to lazy values, and in Python, we intercept Python magic methods: you can find more details on both in our paper.
To summarize, SAs work by doing the following:
- An annotator adds annotations on existing functions, and defines an API that specifies how to split and merge data passed to these functions.
- For C libraries, an annotator uses a tool that generates wrapper code that enables intercepting function calls. In Python, this happens automatically. In both cases, access to library source code is not required.
- Users run their applications as always. Under the hood, Mozart automatically builds a lazy task graph, detects access to it, and executes it with pipelining to optimize data movement and automatic parallelization. The SAs ensure that “incompatible” data is never passed between functions.
That’s it! In our experience developing compilers that provide similar optimizations, SAs require far less effort to use. As we show in the next section, they also provide nearly the same performance in many cases as well.
Results: SAs accelerate data-intensive computations
To evaluate split annotations and to show the different kinds of data structures and workloads they can e applied to, we benchmarked them with a variety of data-intensive applications using several popular libraries: NumPy, pandas, spaCy (a Python NLP library), Intel MKL, and ImageMagick (a C image processing library). We also compared against any available compilers when possible (e.g., Weld or Numba). The plots below show the performance results, with the red number in each plot showing the speedup over the baseline libraries (e.g., un-annotated, single-threaded pandas).
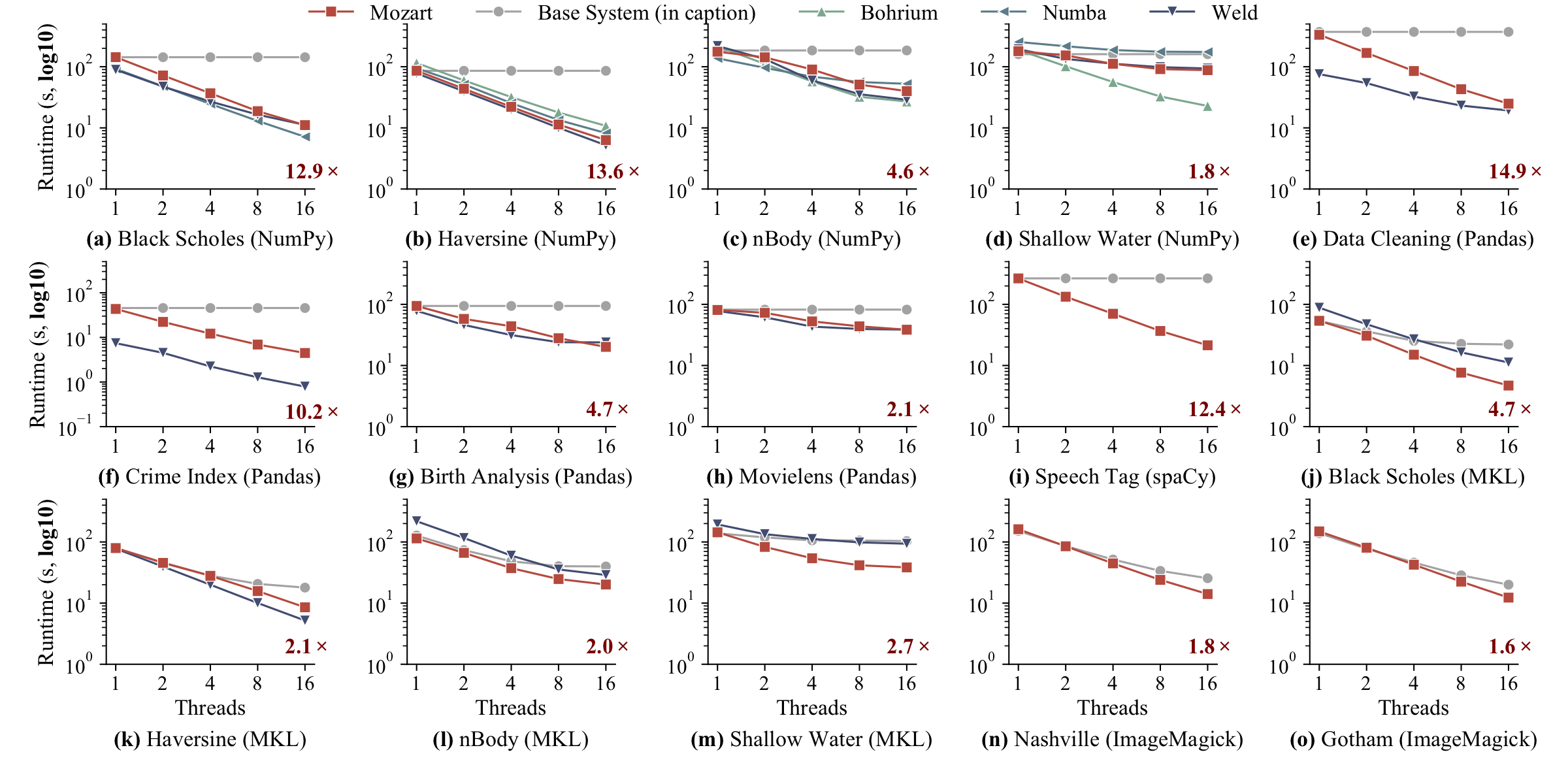
Overall, these experiments show that SAs can accelerate existing applications by up to 14.9x, and can sometimes outperform compilers by up to 1.2x. SAs don’t outperform Weld when compilation improves CPU performance (e.g., string functions in Python) or when SAs’ split-merge paradigm is inapplicable to many functions (e.g., indexed access on arrays).
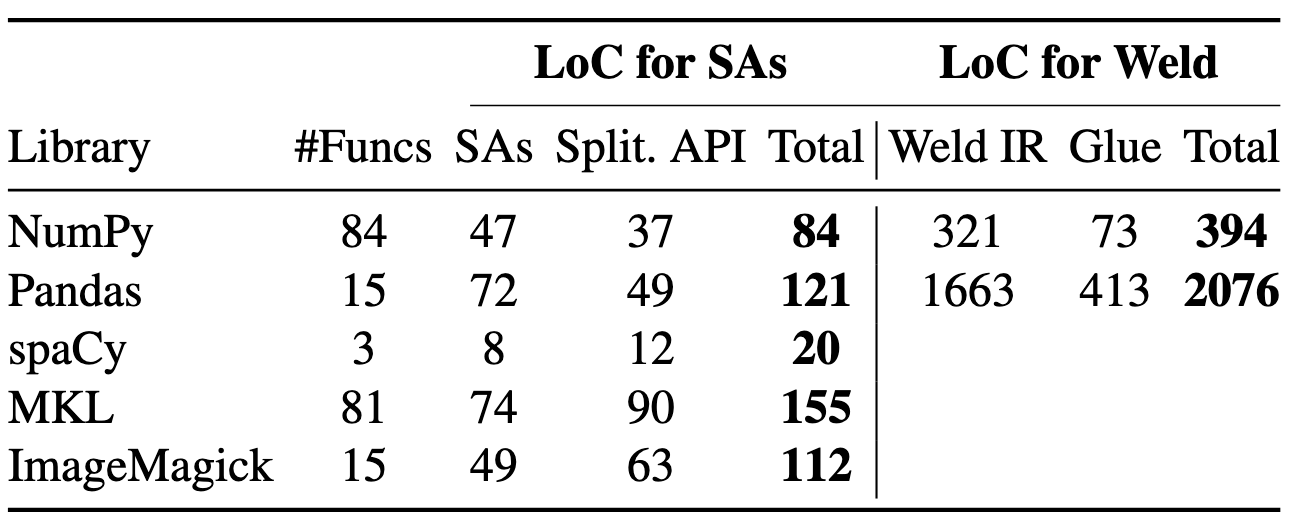
SAs are also require far less code to use in many cases, compared to other compilers. The table below shows the number of lines of code required to support each of the above workloads. In the pandas case, SAs needed 17x less code to produce the same performance in many cases!
Summary
To recap, SAs are a new way to enable parallelism and data pipelining optimizations in existing libraries. They leverage existing code, and, unlike compilers, don’t require intrusive library changes. They even work on closed source black box libraries!
SAs are open-source and under active development; you can check out an alpha
release of our code on
Github. You can also try
out split annotations via the Python package index: pip install sa. SAs
support Python >=3.6. See the documentation
for more information.