Willump: A Statistically-Aware End-to-end Optimizer for Machine Learning Inference
This blog post has been updated. See the updated post here.
In this blog post, we introduce Willump, a statistically-aware end-to-end optimizer for machine learning (ML) inference. Most existing ML inference systems, such as Clipper or AWS Sagemaker, approach ML inference as an extension of conventional data serving workloads. In contrast, Willump leverages unique properties of ML inference to improve performance of real-world workloads by up to 23x. Willump targets ML inference workloads whose computational bottleneck is the cost of computing features, especially workloads that use relatively inexpensive models such as gradient-boosted decision trees. Willump is available on GitHub and is described in detail in our arXiv paper.
Motivation
Machine learning inference is an increasingly important workload in modern data centers. ML inference typically occurs in a pipeline, which processes input data into a vector of numerical features and then executes an ML model on the feature vector. In many ML inference systems, including production systems at Microsoft and Facebook, the cost of computing features is a bottleneck, so ML inference pipelines must be optimized end-to-end.
Most existing ML inference systems, such as Clipper, Pretzel, or AWS Sagemaker, approach ML inference as an extension of conventional data serving workloads. They apply traditional serving and compiler optimizations such as loop fusion and query caching, but miss critical opportunities for improving performance. ML inference systems can leverage two key properties of ML not found in general data serving:
-
ML models can often be approximated efficiently on many inputs: For example, the computer vision community has long used “model cascades” (e.g. Noscope, Focus) where a low-cost model classifies “easy” inputs, and a higher-cost model classifies inputs where the first is uncertain, resulting in much faster inference with negligible change in accuracy. In contrast, existing ML inference systems handle all data inputs the same way.
-
ML models are often used in higher-level application queries, such as top-K queries (e.g., finding the top-scored items in a recommendation model). Existing ML inference systems are unaware of these query modalities, but, as we show, we can improve performance by tailoring inference to them.
To leverage these opportunities for optimization, we designed Willump, the first statistically-aware end-to-end optimizer for ML inference. Willump combines novel ML inference optimizations with standard compiler optimizations to automatically generate fast inference code for ML pipelines. We evaluated Willump on real-world ML inference workloads curated from high-performing solutions to major data science competitions hosted by Kaggle, CIKM, and WSDM. Willump improves their performance by up to 23x, with its novel optimizations giving up to 5.7x speedups over state-of-the-art compilation techniques.
Optimization 1: Automatic End-to-end Cascades
ML inference pipelines often compute many features for use in a model, but because ML models are amenable to approximation, they can often classify data inputs using only a subset of these features. For example, in a pipeline that detects toxic online comments, we can use the presence of curse words to quickly classify some data inputs as toxic, but we may need to compute more expensive TF-IDF and word embedding features to classify others. As a result, existing ML inference systems that simply compute all feature vectors often unnecessarily compute expensive features for “easy” data inputs.
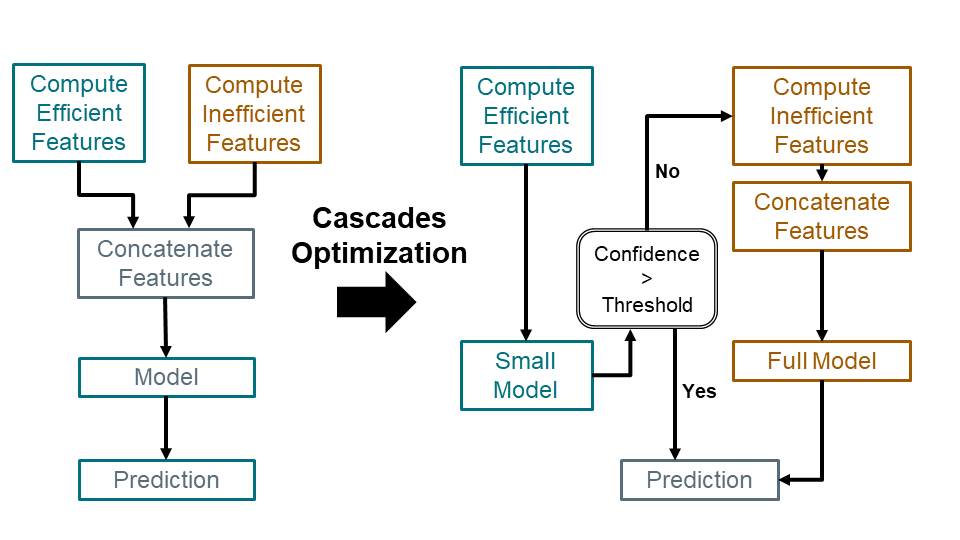
To eliminate this inefficiency, Willump automatically generates end-to-end cascades, which classify data inputs using only necessary features. Willump generates cascades offline using the model’s training data in three stages:
-
Compute Feature Statistics: Willump computes the computational cost and predictive importance of each feature.
It computes predictive importance using model-specific techniques, such as mean decrease impurity for random forests. -
Identify Efficient Features: Willump greedily selects a set of low-cost, high-importance “efficient features.”
-
Model Training: Willump computes efficient features for all training set elements and trains a “small model” from them.
After constructing end-to-end cascades, Willump deploys them for serving. When Willump receives a data input, it computes its efficient features and attempts to classify it with the small model. If the small model is confident in its prediction, Willump returns it, but otherwise Willump computes the input’s remaining features and classifies it with the original full model. We diagram this below:
Optimization 2: Query-Aware Inference
Most existing ML inference systems serve predictions by predicting all data inputs in a batch query. However, many queries are for single data inputs rather than batches, and many batch queries are for higher-level application queries such as top-K queries, which rank the top-scoring elements of a batch. Willump improves performance of these alternative query modalities through query-aware optimizations.
Because existing systems assume data inputs are batched, they maximize computational throughput by parallelizing across batch elements. However, in many ML inference applications, improving the latency of individual queries is critical. Willump improves query latency by parallelizing prediction of individual data inputs. Willump uses a data flow analysis algorithm to identify computationally independent components of ML inference pipelines and then, if possible, compiles them to a low-latency multithreading framework to run concurrently.
Because existing systems predict every element of an input batch, they serve top-K queries naively. Top-K queries are important higher-level application queries which request only the relative ranking of the K top-scoring elements of an input batch. Top-K queries are fundamentally asymmetric; predictions for high-scoring data inputs must be much more precise than predictions for low-scoring data inputs. Thus, existing systems waste time generating precise predictions for low-scoring data inputs. Willump instead leverages the asymmetry by extending its end-to-end cascades optimization, using computationally simple approximate pipelines to predict the input set and filter out low-scoring data inputs; this automated procedure is inspired by the manually constructed retrieval models sometimes used in recommender systems.
Willump Workflow
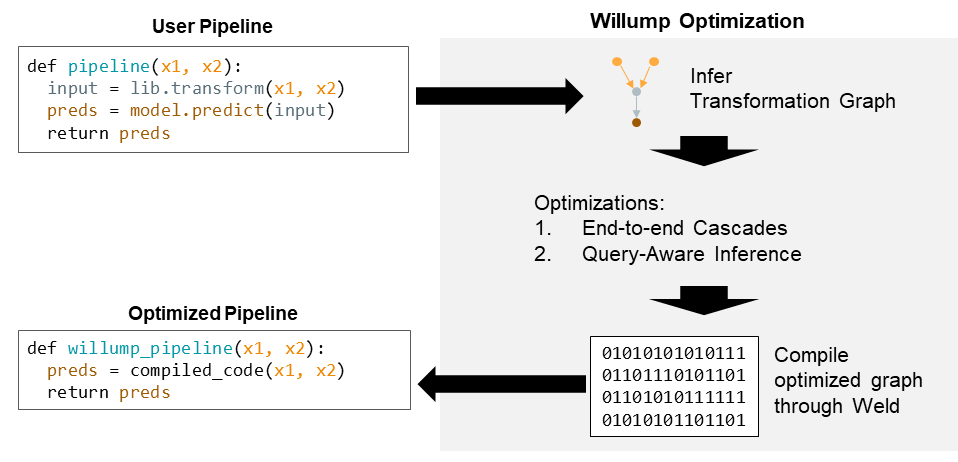
Willump optimizes ML inference pipelines written as functions from raw inputs to predictions in a high-level language (currently Python). Willump assumes ML inference functions process raw inputs into numerical features, construct a feature vector from the features, and execute an ML model on the feature vector. Willump operates in three stages: dataflow, optimization, and compilation:
-
Dataflow Stage: Willump’s dataflow stage converts a Python input function into a directed acyclic graph of transformations. A transformation graph defines the flow of data in a pipeline from raw inputs to the model.
-
Optimization Stage: Willump’s optimization stage applies Willump’s novel optimizations to the transformation graph.
-
Compilation Stage: Willump’s compilation stage transforms the optimized graph back into a function.
It also compiles some graph nodes to optimized machine code using the Weld system. It returns the optimized pipeline.
We diagram Willump’s workflow below:
Results
We evaluated Willump on six real-world benchmarks curated from entries to major data science competitions hosted by Kaggle, CIKM, and WSDM. In this blog post, we look at three of these benchmarks:
-
Product: Assesses the quality of listings in an online store. Computes string features, then applies a linear model.
-
Toxic: Evaluates whether online comments are toxic. Computes string features, then applies a linear model.
-
Music: Recommends songs to users. Looks up pre-computed features, then applies a boosted trees model.
All benchmark source code is in the Willump repository.
We first evaluate the performance of Willump’s end-to-end cascades optimization. First, we measure the batch throughput of the benchmark’s original (Python) implementation. Then, we compile the benchmark end-to-end using Weld and measure again. This compilation is a strong baseline for evaluation, as we implement similar compiler optimizations as other ML optimizers such as Pretzel. Finally, we apply Willump’s end-to-end cascades optimization, verifying that cascades do not cause a statistically significant loss in accuracy on any benchmark. We show the results below:
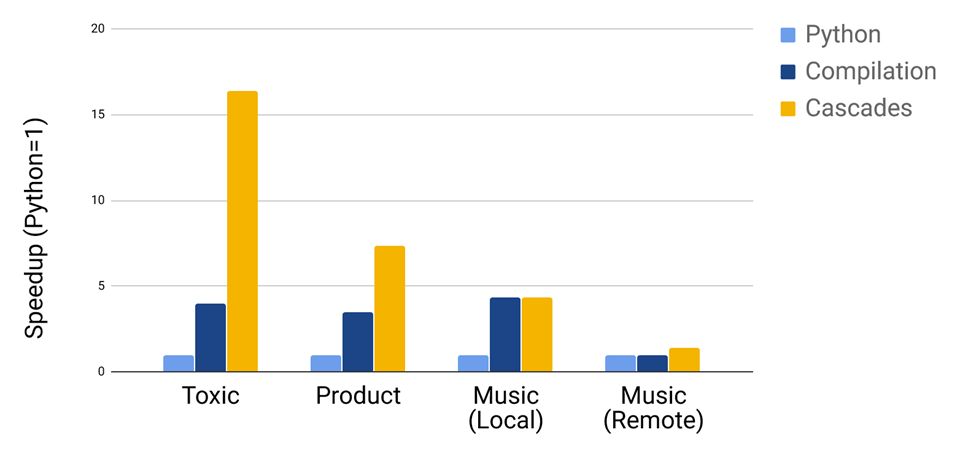
Willump’s end-to-end cascades significantly improve the performance of Product and Toxic. For Music, the story is more complicated. The serve-time feature computation in Music consists of looking up pre-computed features from a feature store. When features are stored locally in memory, feature lookup is so fast relative to model execution that end-to-end cascades cannot significantly improve end-to-end performance. However, when features are stored remotely using Redis, feature computation is more expensive and cascades do improve performance.
Next, we evaluate Willump’s automatically generated filter models for top-K queries, running top-100 queries on each benchmark:
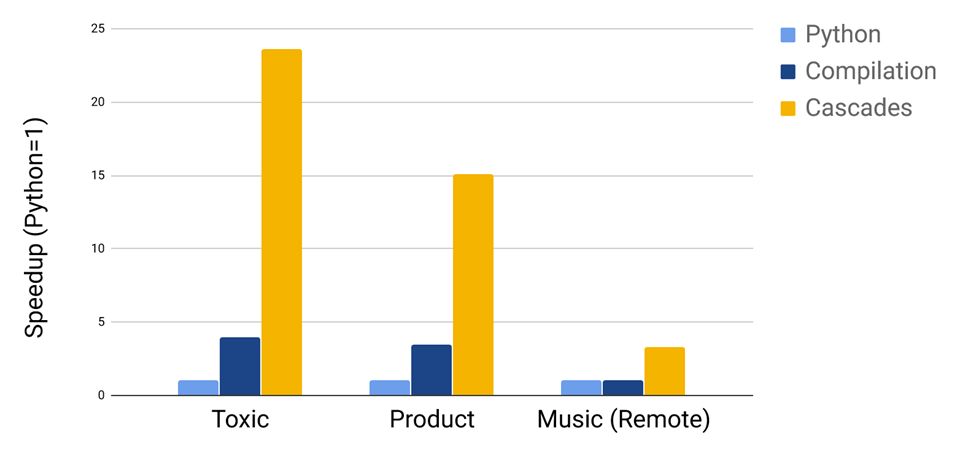
We find signficant speedups over compilation on all three benchmarks.
Finally, we evaluate Willump’s ability to integrate with existing ML inference systems. We serve a Willump-optimized pipeline using Clipper, a recent research ML inference system, and assess end-to-end query performance with different batch sizes:
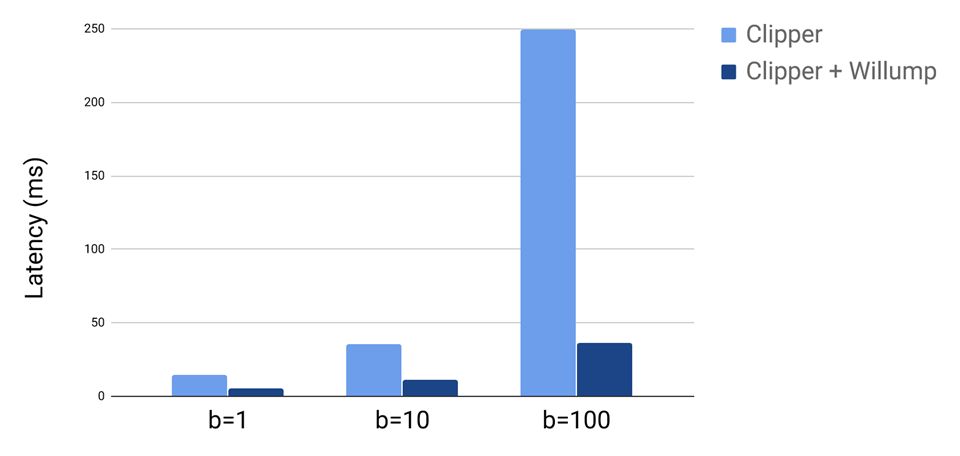
We find Willump significantly improves end-to-end Clipper query performance; this improvement increases with batch size as Clipper’s large overhead is amortized over the batch.
Conclusion
In this blog post, we introduced Willump, the first statistically-aware end-to-end optimizer for ML inference. We showed how Willump improves ML inference performance by leveraging its particular properties, such as its differing query modalities and amenability to approximation. For more information about Willump, see our paper on arXiv or look at our code on GitHub. Let us know if you are interested in trying Willump out and send us feedback or questions at willump-group@cs.stanford.edu.