Get LIT: A New Approach to Compress DNNs by up to 5.5x with no Loss in Accuracy
Check out our paper and our code on GitHub!
Modern DNNs are becoming deeper, requiring large amounts of compute resources to deploy. In this blog post, we describe LIT, a compression method better suited to modern DNN architectures than prior work. LIT can provide compression up to 5.5x with no loss in accuracy.
LIT improves model compression for modern DNN architectures by taking advantage of multiple intermediate representations of a teacher model to train a shallower, faster student model. LIT can compress a wide range of models, including ResNets, ResNeXts, VDCNNs, and even StarGAN on a variety of tasks without loss in accuracy.
Prior Work
Researchers have proposed two broad categories of model reduction techniques:
- In model compression, individual weights or filters within a DNN are pruned [1] [2] [3] [4] . Since individual weights or filters are removed, many model compression techniques yield lighter models with sparse weight matrices, requiring specialized hardware with support for sparse multiplies to realize performance benefits. Additionally, some model compression techniques have been shown to be best suited for fully connected layers, as opposed to convolutional layers.
- In Knowledge Distillation (KD), a typically deeper, trained teacher model guides a typically shallower student model [1] [2] [3] . KD uses the “knowledge” from the teacher in the form of its logits to “guide” the training of the student model, delivering higher accuracy than standard training. However, we show that we can incorporate the structure of modern deep networks to improve training.
🔥 LIT 🔥
LIT matches multiple intermediate representations in addition to the final output logits, like in KD, between teacher and student to guide the training of the student model. We show a schematic below.
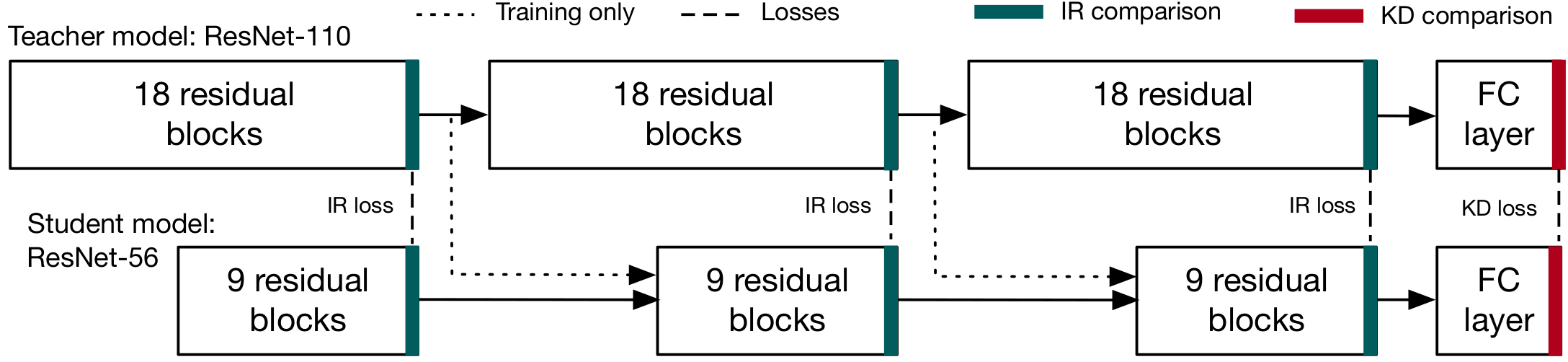
LIT takes advantage of two key properties:
- With LIT, we consider teachers and students of the same architecture type. For example, we may have a trained ResNet-110 and want to compress that model to deploy a ResNet-20.
- Many modern DNN architectures have highly repetitive structures. For example, all ResNets trained on CIFAR 10 are built with 3 residual sections, where the output shape of each of these sections is the same regardless of size.
By comparing multiple intermediate representations between the teacher and the student, LIT stabilizes training and students can converge to a higher accuracy than compared to training with just the output logits, as in KD. We can choose these comparison points where we compare teacher and student representations using the natural split points of the modern network architecture.
Results
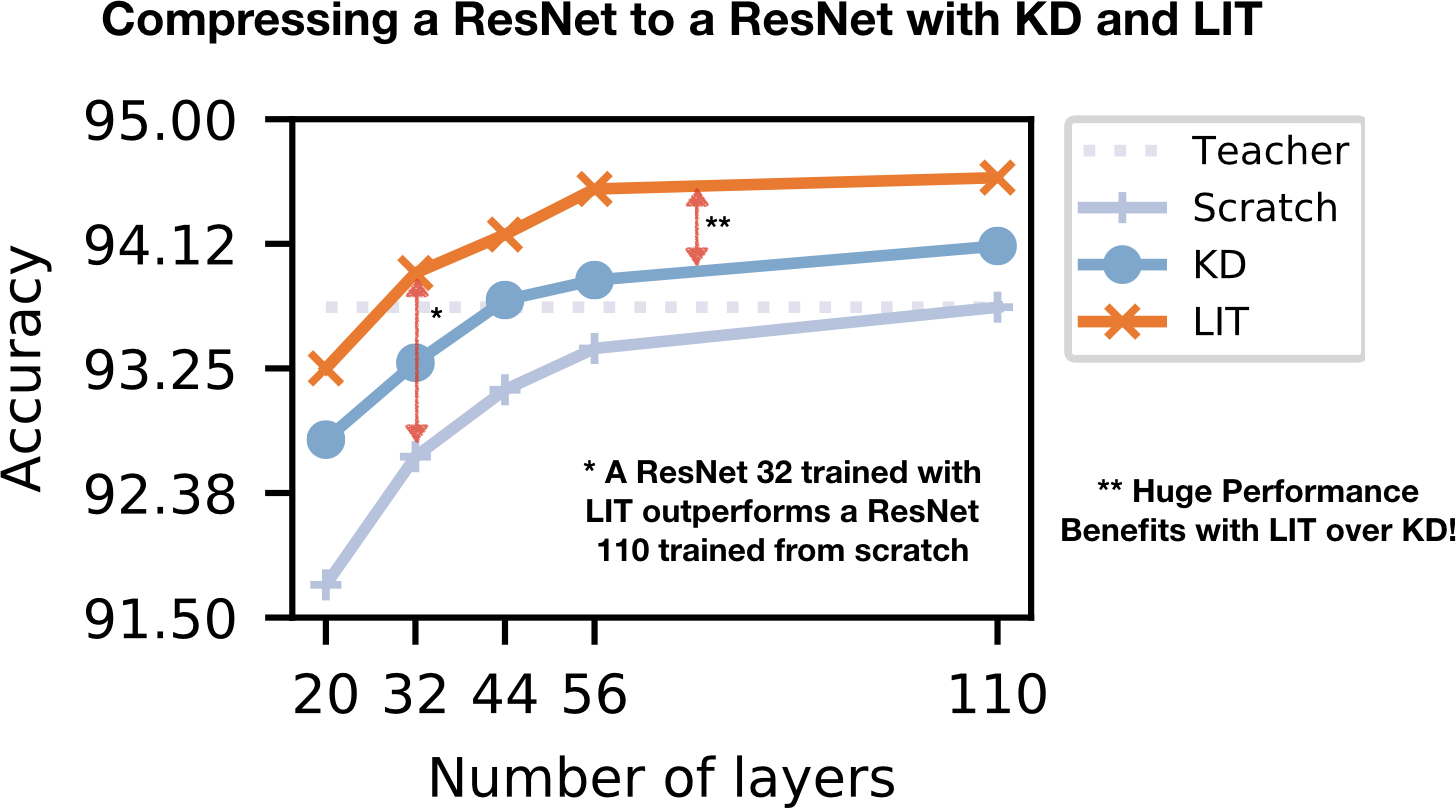
LIT can compress ResNeXts trained on CIFAR10 by up to 5.5x, ResNets trained on CIFAR 10 by 3.4x, and VDCNNs trained on the Amazon Reviews Dataset (sentiment classification) by up to 1.7x by depth.
LIT can be easily extended to compress GANs as well. LIT is able to compress a StarGAN by over 1.8x on the Celeb A dataset, with no visual performance regression. In fact, the compressed student model produces cleaner images in many cases: the student model has a FID score of 5.84 compared to the teacher with a FID score of 6.43 (where a lower FID score is better).

Conclusions
LIT is being presented at ICML 2019 in Long Beach, CA. Our talk will be on Thursday June 13 12:00-12:05 PM in hall A. We will also be presenting our poster on Thursday, June 13th 6:30 - 9:00 PM in Pacific Ballroom at poster #17.
Come by if you want to chat, have any questions, or want to get LIT!
Try LIT
To try LIT take a look at our GitHub! Our compressed models are available in the GitHub.
Takeaways
- LIT produces fast and hardware realizable speedups to many modern neural network architectures.
- LIT matches multiple intermediate representations to guide a smaller student model to converge.