Earthquake Hunting with Efficient Time Series Similarity Search
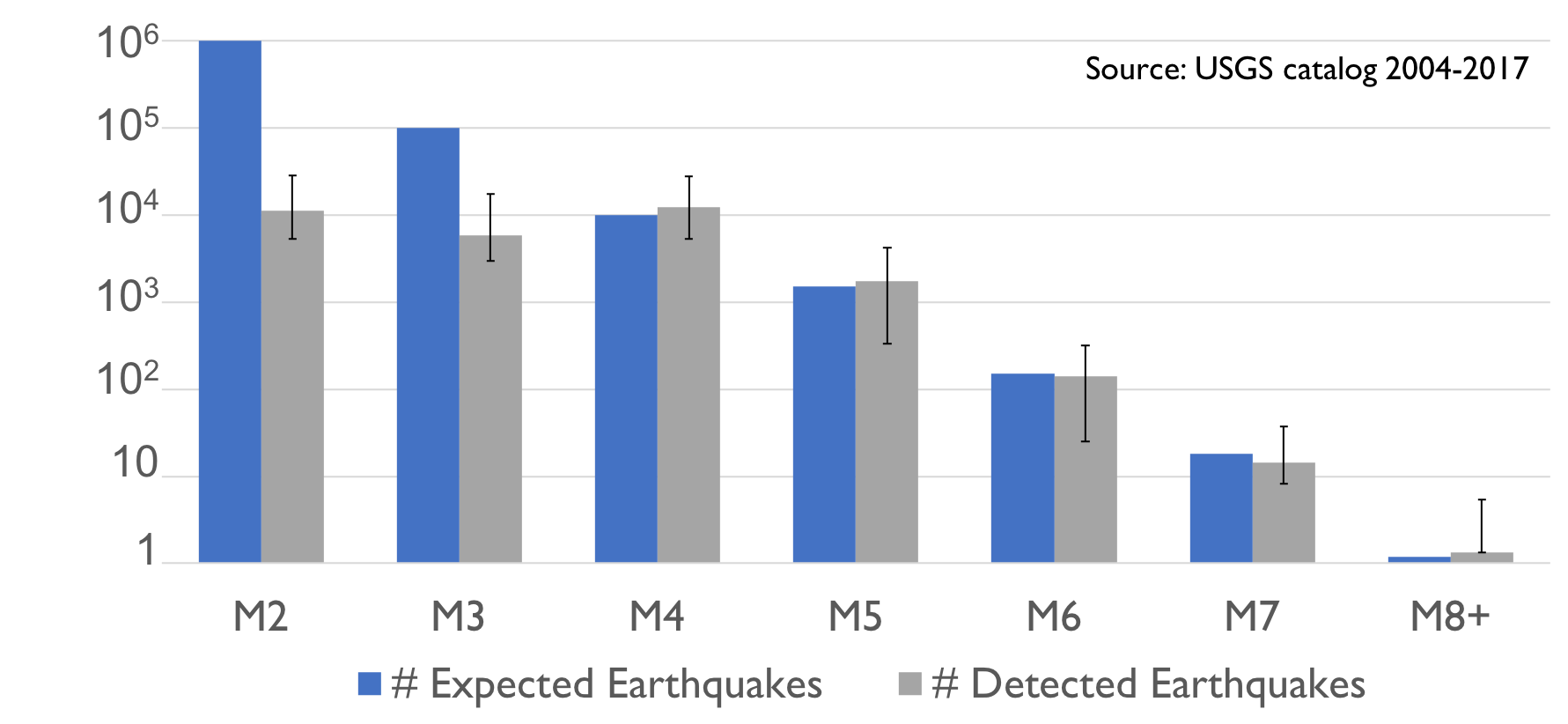
Worldwide, major earthquakes (magnitude 7+) occur approximately once a month, while magnitude 2 and smaller earthquakes can happen up to several thousand times a day. In fact, earthquake frequency is inversely proportional to magnitude, meaning most earthquakes are very small. An estimated 1% of these small-magnitude events are detected and recorded in public catalogs (Figure 1), yet these low magnitude earthquakes are used by scientists to uncover unknown seismic sources, understand earthquake mechanics and predict major seismic events.
In this blog post, we describe our collaboration with seismologists at Stanford on detecting these “missing” earthquake events with time series similarity search via Locality Sensitive Hashing. We build and optimize an end-to-end detection pipeline that leverages the key property that reoccurring earthquakes have similar waveforms. By scaling the pipeline to over ten years of continuous time series data (over 30 billion data points) with both domain-specific and systems optimizations, we discovered 597 new earthquakes near the Diablo Canyon nuclear power plant in California and 6123 new earthquakes in New Zealand.
Background
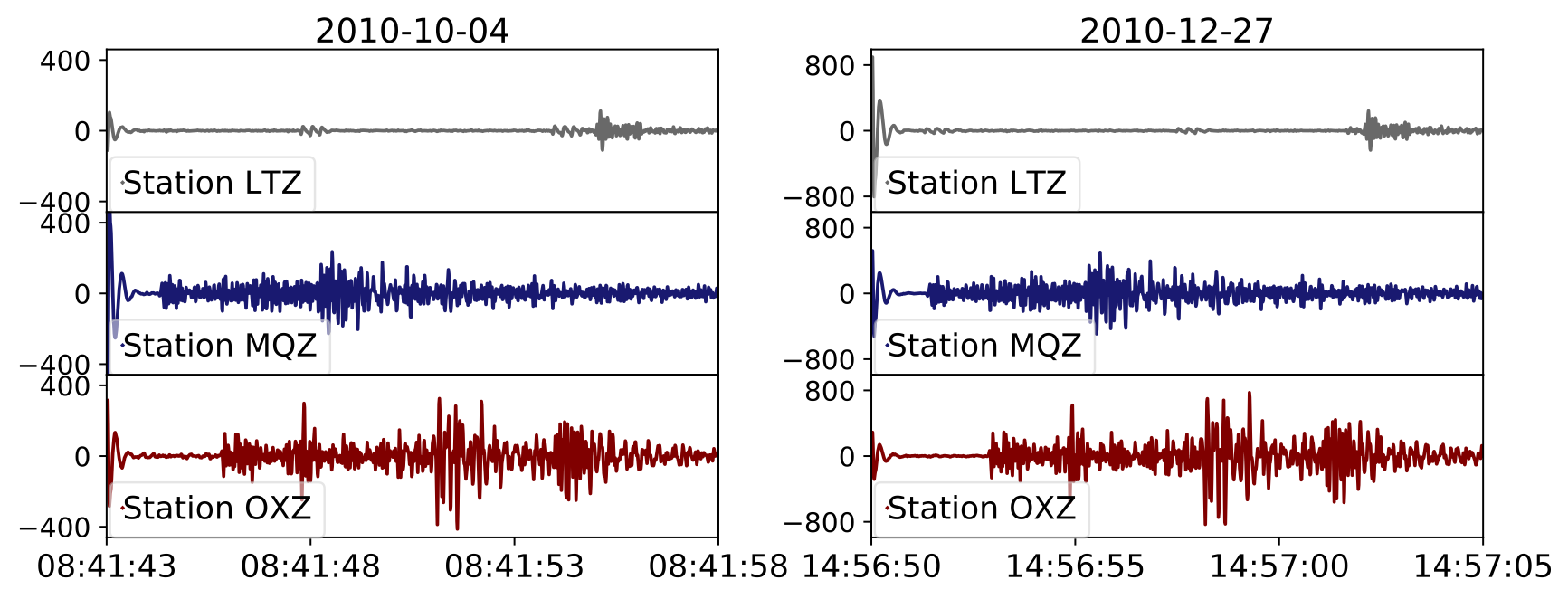
Earthquakes are monitored by seismic networks, which contain up to thousands of stations that continuously measure ground motion via seismometers. Seismic sources repeatedly generate earthquakes over the course of days, months or even years, and reoccurring earthquakes from the same source show near identical waveforms when recorded at the same seismic station, regardless of the earthquake’s magnitude (Figure 2).
Therefore, to identify small earthquakes, we can look for similar seismic activities over time. We divide continuous ground motion measurements into short time series segments and identify pairs of similar segments as candidate earthquakes. In other words, segments with similar waveforms can be two earthquakes, measured at the same location but at different times.
However, at scale, computing all-pairs similarity is incredibly expensive. Naively computing the all-pairs similarity search on a month of data could take over a year on a modern server.
To avoid the expensive pairwise comparison, we perform an approximate similarity search via Locality Sensitive Hashing (LSH). LSH hashes time series segments into buckets, such that similar segments have a high probability of sharing a hash bucket. Therefore, during similarity search, we only compare each segment to other segments in the same hash bucket, which account for a small fraction of the total data. On seismic datasets, compared to exact similarity search methods such as set similarity join, LSH incurred a 6% false negative rate on an example dataset while enabling up to 197x speedup.
Going Faster with Domain Priors
By applying LSH to identify similar waveforms from seismic data, our collaborators in seismology were able to discover new, low-magnitude earthquakes without knowledge of prior earthquake events. However, a naive implementation of the pipeline has difficulty scaling beyond 3 months of continuous time series data measured at a single seismic station.
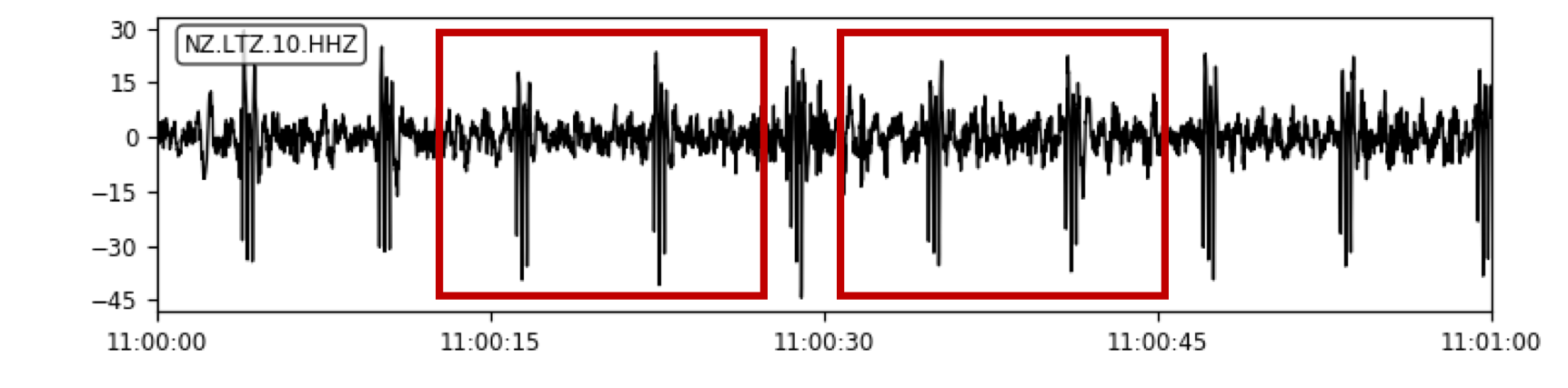
As a result, we spent a year working closely with our collaborators to improve the pipeline, which we detail in our recent VLDB paper. To give a sense of the types of challenges we encountered in applying LSH in practice, consider the presence of repeating background signals (Figure 3), which arise from periodic activity including sprinklers, road motion, and sensor noise. Since these waveforms repeat, they’ll be flagged as candidate earthquakes by LSH. Moreover, in real datasets, we found these “noise waveforms” far outnumbered earthquake waveforms, leading to a more than 10x increase in runtime and 100x increase in output size compared to stations that were unaffected by repeating noise.
To suppress matches generated by noise instead of earthquakes, we developed two domain-informed filters:
Bandpass filter
We use a bandpass filter to exclude frequency bands that show high average amplitudes and repeating patterns while containing low seismic activities. Empirically, a narrow, domain-informed bandpass filter focuses the comparison of similarity only on frequencies that are characteristics of seismic events, increasing the similarity between earthquake events. On a public dataset of four seismic stations in New Zealand, applying a proper bandpass filter results in a 24.9% increase in the earthquake detection recall, as well as an up to 16x decrease in runtime and 209x decrease in output size.
Occurrence filter
Similarly, we leverage the rarity of earthquake events. Namely, time series segments that repeat too frequently are likely not real earthquake events. This observation holds in general except for special scenarios such as volcanic earthquakes. During similarity search, if a time series segment has more near neighbors than a predefined percentage of total segments, we exclude this segment as well as its neighbors from future similarity search (Figure 4).

We evaluated the occurrence filter on two nearby seismic stations in the New Zealand dataset described above. For the station suffering from correlated noise, the occurrence filter effectively eliminates over 32% of total fingerprints from the similarity search without any false positives, which results in a 5.2x improvement in runtime and over 50x reduction of output size. For the station unaffected by the repeating noise, as expected, the filter has little influence on the results.
Results
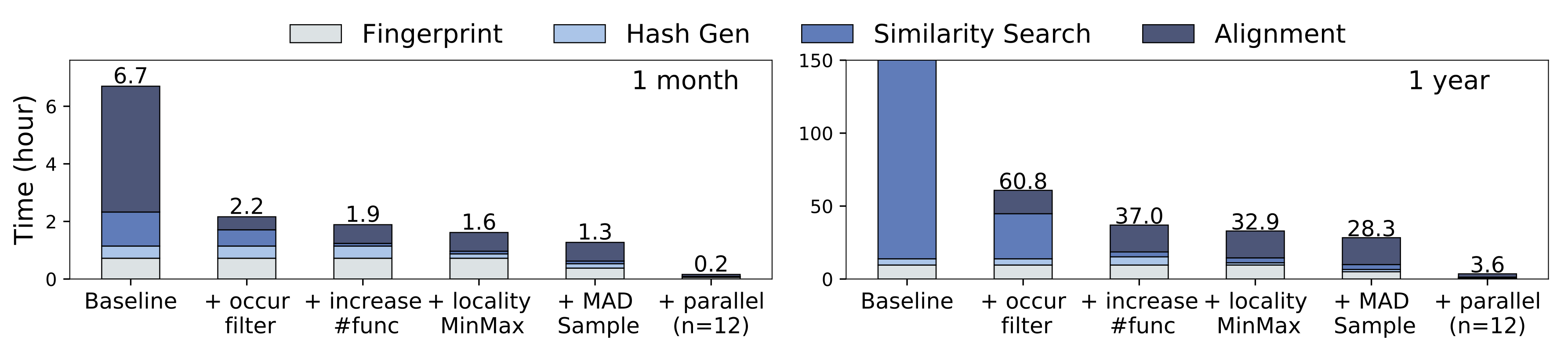
We applied several optimizations such as the above across the pipeline, including speeding up the hash signature generation with cache locality, tuning LSH parameters for better performance, proper partitioning and parallelization of all components of the pipeline etc. Our optimizations scale well with data size and lead to an over 100x speedup on the end-to-end pipeline (Figure 5).
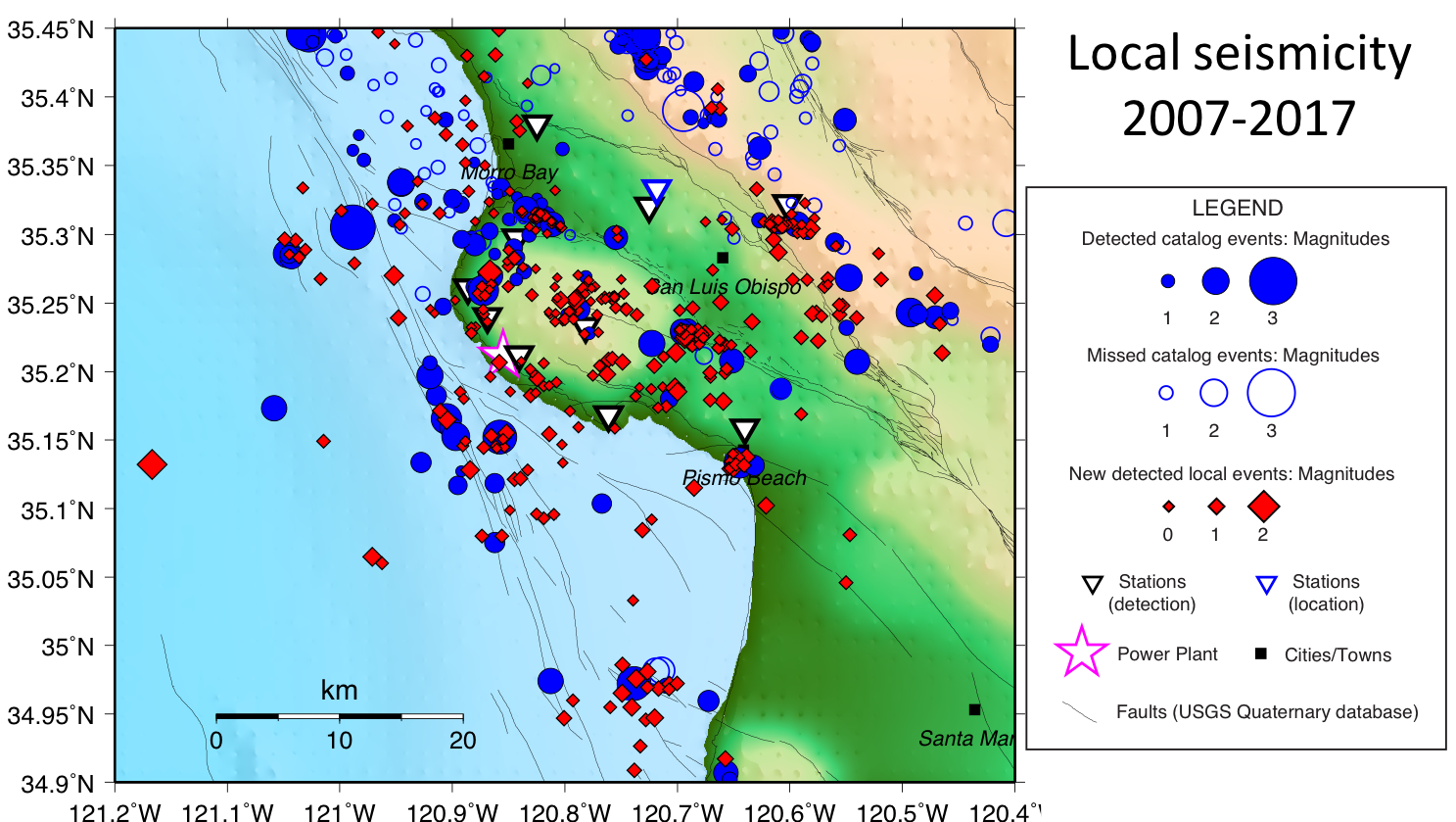
The scaled pipeline enabled a new seismic analysis over a decade (06/2007 to 10/2017) of continuous seismic data from 11 seismic stations (27 total channels) near the Diablo Canyon nuclear power plant in central California. The chosen area is of particular interest as there are many active faults near the power plant. Detecting additional small earthquakes in this region will allow seismologists to determine the size and shape of nearby fault structures, which can inform seismic hazard estimates.
Our pipeline detected and located 3957 catalog earthquakes, as well as 597 new local earthquakes, spread over the entire ten-year span. Despite the low rate of local earthquake activity (249 total catalog events from 2007 to 2017 within the area shown in Figure 6), we were able to detect 355 new events that are between -0.2 and 2.4 in magnitude and located within the seismic network, where many active faults exist. We missed 101 catalog events, almost all of which originated from outside the network of our interest. We are preparing these results for publication in seismological venues.
In addition, we compared our unsupervised pipeline to two supervised models for time series/earthquake classification trained on catalog events from the Diablo Canyon dataset. Figure 7 reports the test accuracy of the two models on a sample of 306 unseen catalog events, 85,060 windows of noise and 449 new events detected by our pipeline. While supervised methods achieve high accuracy in classifying unseen catalog and noise events, they exhibit a high false positive rate (90\(\pm\)5.88%, details in the paper) and miss 30-32% of new earthquake events detected by our pipeline. The experiment suggests that unsupervised methods like ours can detect qualitatively different events from the existing catalog, and that supervised methods are complementary to unsupervised methods for earthquake detection.
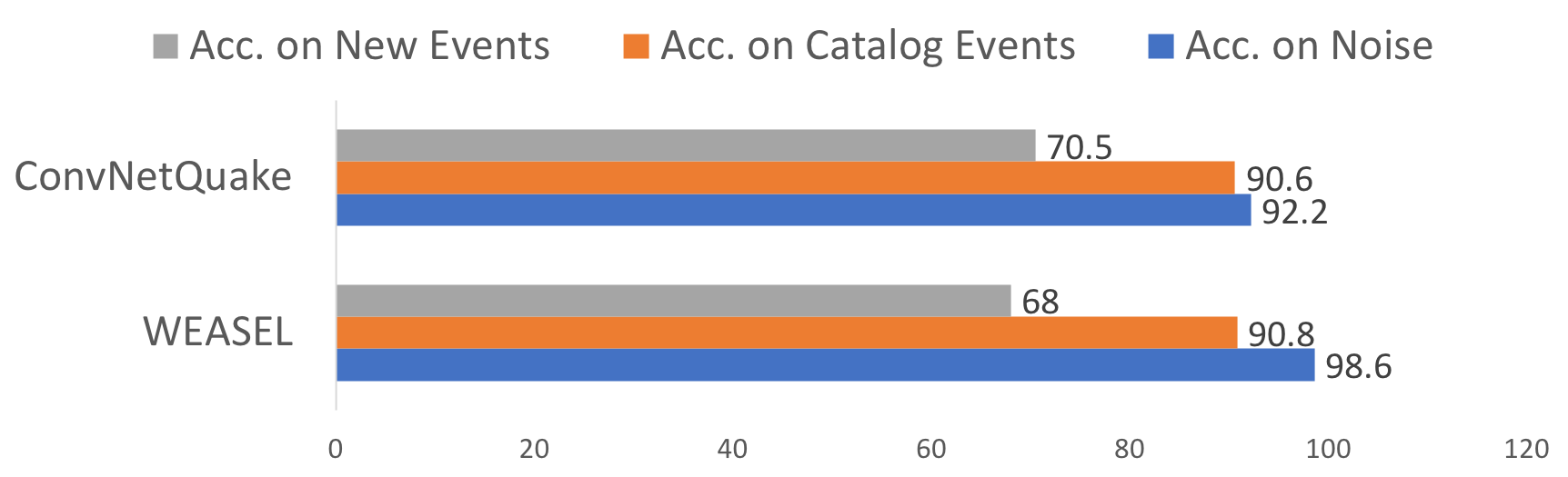
Summary
In this blog post, we introduced an unsupervised method to extract earthquake events from continuous ground motion data. We show that by scaling the analysis to over ten years of data, we are able to make new scientific discoveries. Our code is available as open source on Github, along with a user guide. For more information, please check out our VLDB 2018 paper.