Filter Before You Parse: Faster Analytics on Raw Data with Sparser
Many big data applications often run on raw, unstructured or semi-structured data formats, such as JSON. Querying these files is often very time-consuming, especially for exploratory applications, where data scientists run queries to explore and better understand their data. Surprisingly, 80-90% of the execution time in these applications is actually spent on parsing the data, not on evaluating the actual query itself. Parsing is, in fact, the bottleneck.
In this post, we introduce Sparser (code here), a recent research project from the Stanford DAWN group that addresses this performance gap. Sparser’s key insight is to filter data before it’s parsed using SIMD-accelerated filtering functions. On JSON, Avro, and Parquet data, Sparser is up to 22x faster than state-of-the-art parsers, and improves end-to-end query runtimes in Apache Spark by up to 9x.
Why is Parsing Slow?
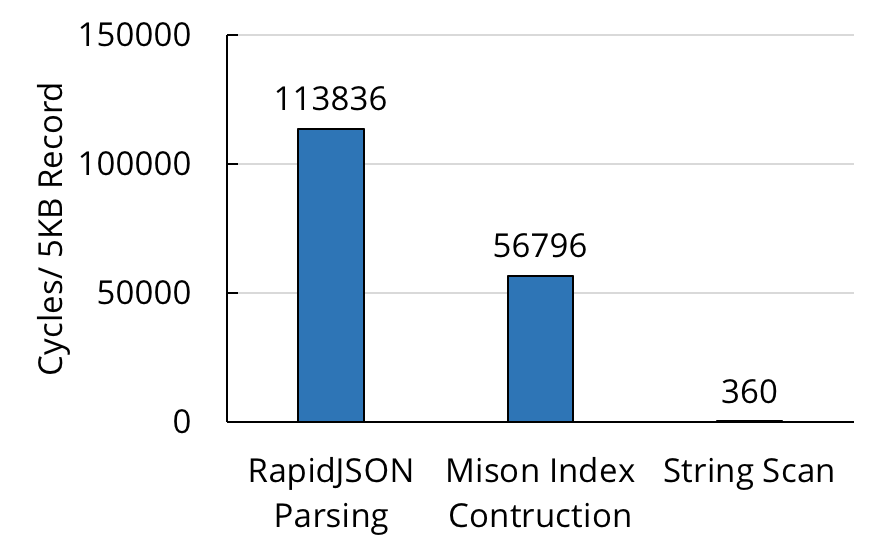
Slow parsing of raw data streams is not a new problem in the database community; at VLDB 2017, researchers at Microsoft presented Mison, a new JSON parser that uses SIMD instructions to build a structural index over each JSON record, which enables efficient field projection without deserializing the record completely. While Mison is significantly faster than previous state-of-the-art parsers, such as RapidJSON, it can still leave a lot of performance on the table. When we measured Mison’s parsing throughput on sample JSON data, we found that it still executed multiple CPU cycles per byte on average. Compared to a simple byte-by-byte SIMD scan of the data (the theoretical upper bound for parsing), Mison was multiple orders of magnitude slower.
Pushing Filters Down to the Parser
Mison’s improvement on previous parsers comes from a simple idea: apply projections before parsing. That is, take the projections found in most user-specified queries over the JSON data, and apply the projections before the parsing stage, so that only the necessary fields that users want are parsed.
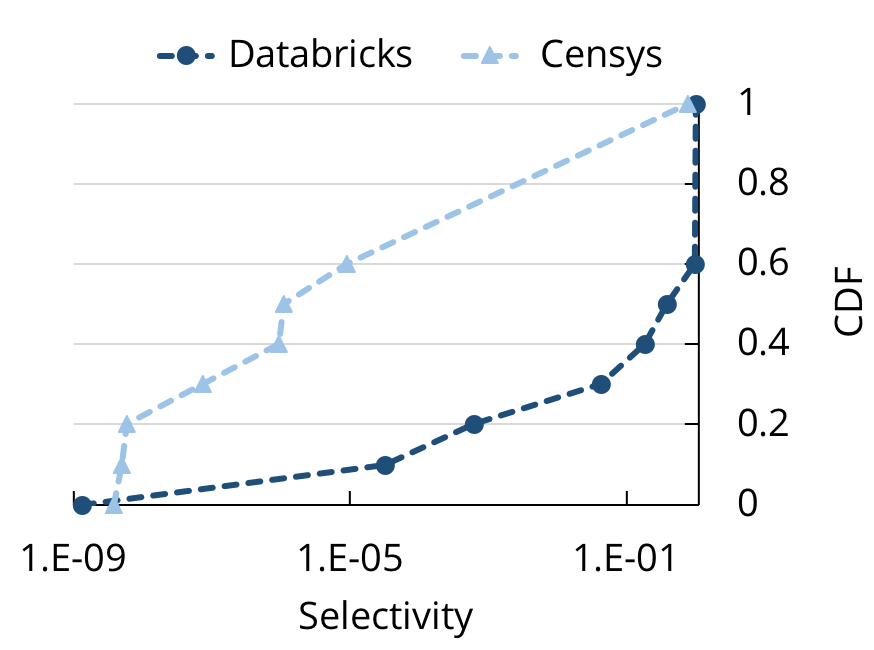
Inspired by Mison, Sparser uses an analogous idea: what if we push filters down to the parser as well? This is especially helpful for exploratory queries in data analytics, because these queries are often highly selective. For example, when we looked at profiling metadata about Spark SQL queries on Databricks’ cloud service that read JSON or CSV data, we found that 40% of the queries selected less than 20% of the records. We ran a similar analysis on researchers’ queries on JSON data from Censys, a search engine for Internet port scans, and found even higher selectivity for those queries. This observation leads to an intuitive idea to optimize parsing: if the JSON record is not going to appear in the end result presented to the user, then we shouldn’t parse it at all!
Sparser: Filter Before You Parse
Based on this insight, Sparser takes as input a JSON file and a user-specified SQL query, and evaluates the query on the parsed JSON file through the following steps:
- Sparser extracts predicates from the query and compiles each predicate into one or more Raw Filters (RFs). RFs are SIMD-efficient filter functions that run over the raw data and discard records; an RF can allow false positives, but no false negatives.
- Sparser runs a cost-based optimizer over all the candidate RFs and generates an RF cascade—a series of RFs that maximizes the parsing throughput for the given query and raw data.
- Sparser applies the chosen RF cascade over the raw data and discards the records that don’t pass the cascade. Finally, the remaining rows are then passed to a downstream parser, such as RapidJSON or Mison.

Because Sparser’s optimizations are orthogonal to prior work on parsing, Sparser is actually complementary to other parsers, including the state of the art, such as Mison. Furthermore, Sparser also generalizes to other, more structured data formats, such as Avro and Parquet. These formats do not rely on explicit characters (e.g., ‘{‘ and ‘}’ in JSON) to delimit records; thus, Mison’s structural index technique, which scans for such characters, cannot be applied. Sparser’s Raw Filter approach, however, can be applied to any data format with delimited records, either implicitly or explicitly.
Sparser vs. the State of the Art
To measure Sparser’s effectiveness, we first benchmarked it against RapidJSON and Mison on a single machine. We downloaded a 16 GB corpus of JSON records from Censys, evaluated nine queries of varying selectivity, and measured their runtime with each parser, both with and without Sparser:
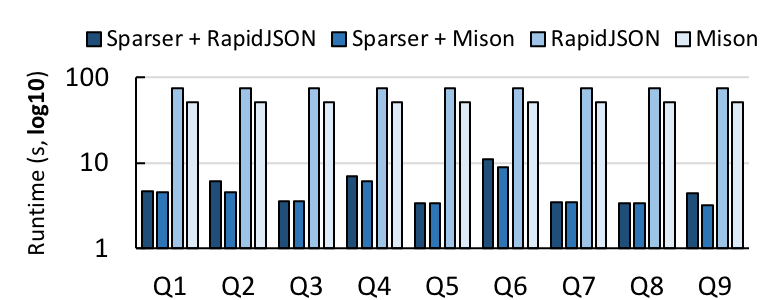
When combined with either RapidJSON or Mison, Sparser reduces the parsing time by roughly an order of magnitude on average, and as much as 22x. Because these queries have low selectivity, Sparser’s Raw Filters can efficiently filter records that do not need to be parsed, even when combined with Mison. Thus, raw filtering is complementary to Mison’s projection optimizations.
Next, we integrated Sparser with Apache Spark, combining it with the Jackson JSON parsing library that Spark normally uses. We collected a much larger, 652 GB corpus of JSON records from Censys, as well as 68 GB corpus of Tweets from Twitter. Then, for each dataset, we benchmarked 1) the time to load the data from disk, 2) the end-to-end query runtime in Spark SQL, including time to load from disk, parse the data, and evaluate the query, and 3) the query evaluation runtime by itself.
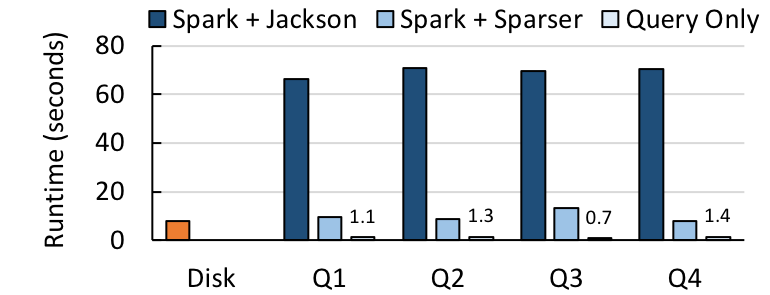
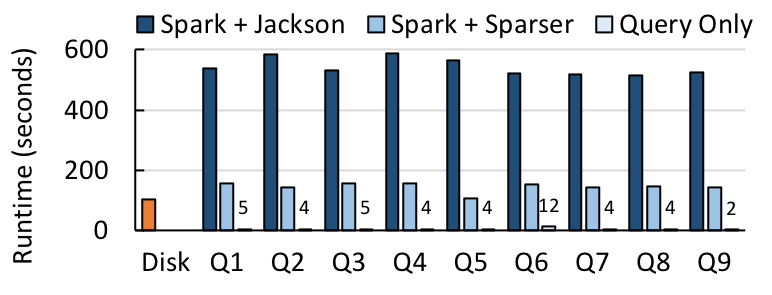
Sparser improves the end-to-end runtime by up to 9x for the four Twitter queries, and up to 4x for the nine Censys queries. For both, the time to answer a query is only a fraction more than the time it takes to load the file from disk.
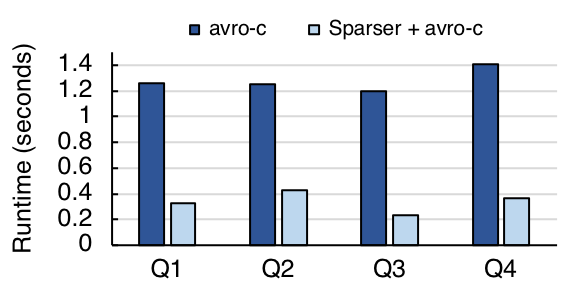
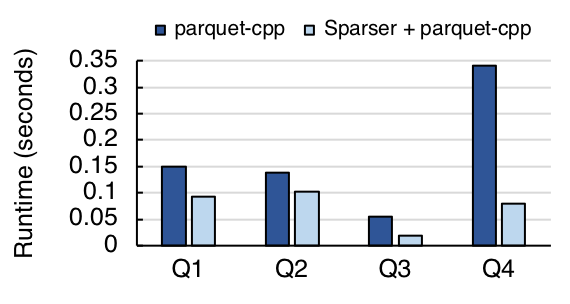
Finally, to benchmark Sparser on Avro and Parquet, we converted a smaller, 23 GB version of the Tweets dataset into both formats, and benchmarked the same four Twitter queries. We found that, even for these optimized data formats, Sparser can still accelerate queries by up to 5x:
Summary
To recap, Sparser is a new parsing engine for unstructured and semi-structured data formats, such as JSON, Avro, and Parquet. Sparser:
- uses Raw Filters to filter before parsing, discarding records that don’t need to be parsed with some false positive rate
- selects a cascade of Raw Filters using an efficient optimizer
- delivers up to 22x speedups over existing parsers
Sparser is open-source and still under development; you can check out an alpha release of our code on Github. We recently presented Sparser at the Spark+AI Summit in San Francisco (video here), and we’ll also be presenting it on Thursday, August 30th at VLDB 2018 in Rio de Janeiro. For more information, check out our camera-ready paper, and feel free to contact us at shoumik@cs.stanford.edu and fabuzaid@cs.stanford.edu for any additional questions.