End-to-End Optimization for Data Analytics with Weld
Weld is an open source project, with an initial prototype described in a CIDR 2017 paper. This blog describes the adaptive optimizer in Weld, which we present in our VLDB 2018 paper.
Analytics applications compose a diverse mix of software libraries and functions, such as Pandas to manipulate tables, NumPy for numerical processing, and TensorFlow for machine learning. These libraries allow developers to combine fast, state-of-the art algorithms from a variety of domains into powerful processing pipelines.
Unfortunately, even if individual functions in each library are meticulously optimized, we have found that a lack of end-to-end optimization can seriously hinder performance when composing library functions. As one example, workloads that combine multiple calls to optimized BLAS functions using NumPy can be up to 23× slower compared a hand-tuned C implementation that performs simple cross-function optimizations such as pipelining.
In recognition of this performance gap, we recently proposed Weld, a common parallel runtime for analytics workloads. Weld is built to enable end-to-end optimization across disjoint libraries and functions without changing the libraries’ user-facing APIs. For library developers, Weld enables both automatic parallelization of library functions as well as powerful cross-function optimizations such as loop fusion. For users, Weld provides transparent order-of-magnitude speedups without requiring code changes to existing pipelines: data analysts can continue to use the APIs of popular libraries such as Pandas and NumPy without modification.
Weld consists of three main components that developers use when integrating with their libraries:
-
Library developers express the data-parallel structure of the computations in their function (e.g., a map operation or an aggregation) using Weld’s functional intermediate representation, or IR.
-
Libraries using Weld then use a lazily evaluated runtime API to submit fragments of the Weld IR to the system. Using the IR fragments, Weld automatically tracks and composes calls made to other functions, perhaps from other libraries.
-
When a user wants to evaluate a result (e.g., to write it to disk or display it), Weld uses an optimizing compiler to optimize and JIT-compile the IR for the combined program to fast parallel machine code, which executes against the application’s in-memory data.
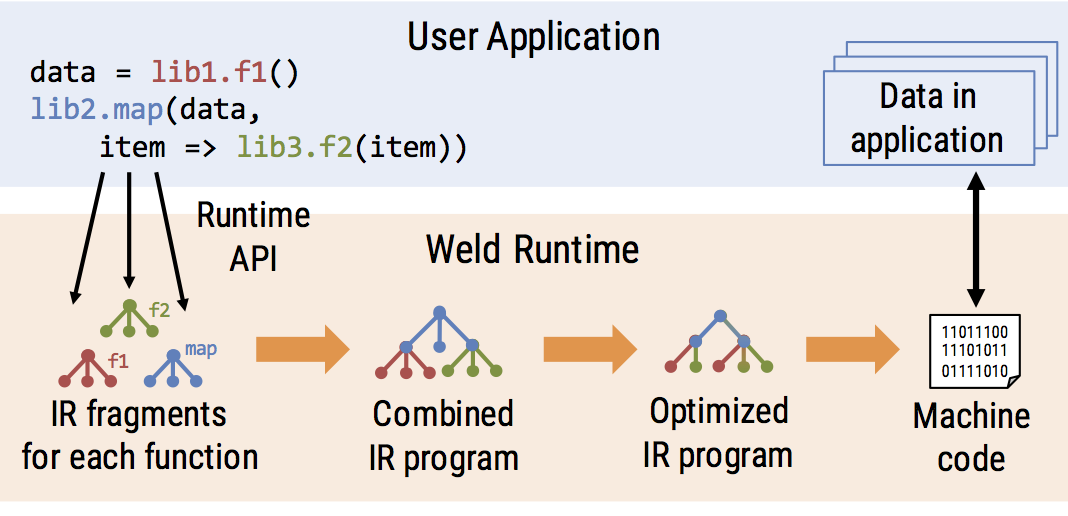
In many cases, users can switch to the Weld-enabled version of a library by swapping out an import statement.
Our initial prototype of Weld, described in our CIDR 2017 paper, showed promising results. With manually applied optimizations on the IR, Weld exhibits order of magnitude speedups on synthetic workloads that combine functions both from a single library and from multiple libraries.
VLDB 2018: Automatic Optimization in Weld
A notable limitation of our prototype was that the optimizations over the IR were applied manually with a priori knowledge of data-dependent properties such as the cardinality of an aggergation. In short, the system lacked an automatic optimizer. To this end, our latest paper at VLDB 2018 presents the design and implementation of an optimizer that automatically optimizes Weld programs.
Because Weld seeks to optimize functions that come from different, independently written libraries in an ad-hoc environment, we found that designing an optimizer raised a few unique challenges in comparison with a traditional database optimizer:
- Computations are highly redundant. Unlike human-authored SQL queries or programs, Weld programs will be machine generated, often by libraries and functions that have no knowledge of each other. It is thus crucial to eliminate redundancies that arise from library composition, e.g., intermediate results that can be pipelined or expensive common subexpressions that can be computed once and saved.
- Weld cannot rely on pre-computed statistics for data-dependent decisions. Weld thus needs to optimize ad-hoc analytics without relying on catalogs or other auxiliary information that a traditional database may have access to. Furthermore, we found that enabling some optimizations naively without any statistics could lead to a 3× slowdown in execution time, meaning that some decisions are important to make adaptively.
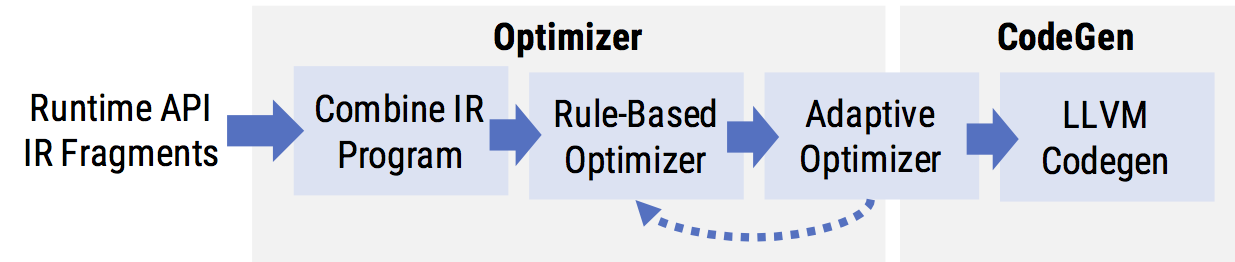
To address these challenges, our optimizer uses a two-pronged design that combines static rule-based optimizations—designed to eliminate redundancy in order to generate efficient Weld IR—and adaptive optimizations that determine at runtime whether to enable or disable certain optimizations.
Our evaluation of Weld with its new optimizer shows some promising results: on a set of 10 real data science workloads using commonly used libraries such as NumPy and Pandas, Weld enables speedups of up to 20× on a single thread, and further speedups with automatic parallelization. In evaluating Weld, we also break down which optimizations have the greatest impact on our sample of data science workloads, which we hope will guide further research in this area.
Rule-based Optimizations: From Loop Fusion to Vectorization
Weld’s automatic optimizer starts by applying a static set of rule-based optimizations that are always beneficial to apply. Rule-based optimizations look for specific patterns in the input Weld IR, and replace those patterns with more efficient ones. Weld’s rule-based optimizer runs over its closed IR, meaning both the input and output of each optimization is the same IR. This design is modeled after the optimization passes in the LLVM compiler infrastructure and allows different rules to be composed and rerun in different ways.
The optimizer contains a number of rules for generating efficient code, ranging from folding constants to merging parallel loops together. A few of the most impactful rule-based optimizations are:
- Loop Fusion, which enables pipelining values by merging two loops where the second loop directly consumes the input of the first. Pipelining improves data locality in the CPU cache, since the merged loop only loads an element from the input once.
- Vectorization, which modifies the IR to produce explicitly SIMD-vectorized code. SIMD instructions in a CPU allow the CPU to do more work in a single cycle, improving throughput.
- Size Inference, which analyzes the IR to pre-allocate memory instead of dynamically growing buffers. This optimization prevents expensive library calls such as
malloc.
Weld applies a number of additional optimizations, described in the paper.
Adaptive Optimizations: From Predication to Adaptive Hash Tables
After transforming the IR with its rule-based optimizer, Weld applies a number of adaptive optimizations. Rather than directly replacing the patterns in the input IR, the adaptive optimizer transforms the Weld program to dynamically choose, at runtime, whether an optimization should be applied.
One example of an adaptive optimization in Weld is determining whether to predicate a branch. Predication converts a branched expression (i.e., an if statement) into code that unconditionally evaluates both the true and false expression, and then selects the correct option based on the condition. Although the predicated code performs more work by always evaluating both expressions, it can also be vectorized with SIMD operators, unlike the branched code. The code snippet below shows an example:
// Branched Code: Always runs with scalar instructions
let result: i32 = 0;
if (x) {
result += foo();
}
// Predicated Code: Runs with vector instructions (~8 scalar scalar ops in parallel)
let result: simd[i32] = <0, 0, 0, 0, 0, 0, 0, 0>;
let tmp0 = foo();
// Vectorized "select" operator
result += x ? tmp0 : 0;
The choice of whether the predication optimization is worth applying depends on two factors: the performance cost (e.g., in CPU cycles) of running foo and the selectivity of the condition x. If foo is expensive to compute and x is rarely true, then unconditionally evaluating foo, even with vector instructions, may lead to worse performance than using the default branched code. In other cases, we may see a large speedup from SIMD parallelism. The data-dependent factor here is the selectivity of x: this parameter is unknown at compile time.
For predication, Weld’s adaptive optimizer thus generates code to sample x to approximate the selectivity at runtime. Then, depending on the measured value, the choice to predicate will be made at runtime using a cost model that sets a THRESHOLD for the selectivity. The snippet below summarizes the adaptive predication transformation:
// Input code with a branch in a loop
let result: i32 = 0;
for e in vector {
if (x) {
result += foo();
}
}
// Adaptive code
let result: i32 = 0;
let selectivity = sample(x);
// Threshold based on cost model
if selectivity > THRESHOLD {
for e in vector {
// run original branched loop
if (x) {
result += foo();
}
}
} else {
for e in vector {
// run vectorized, predicated loop
result += x ? foo() : 0;
}
}
Weld’s adaptive optimizer has a few other other transformations as well: for example, when building hash tables, it can choose whether to use thread-local vs. atomic global data structures depending on the distribution of keys and the corresponding expected memory footprint. Read more about it in our paper.
Weld’s Performance on Data Science Workloads
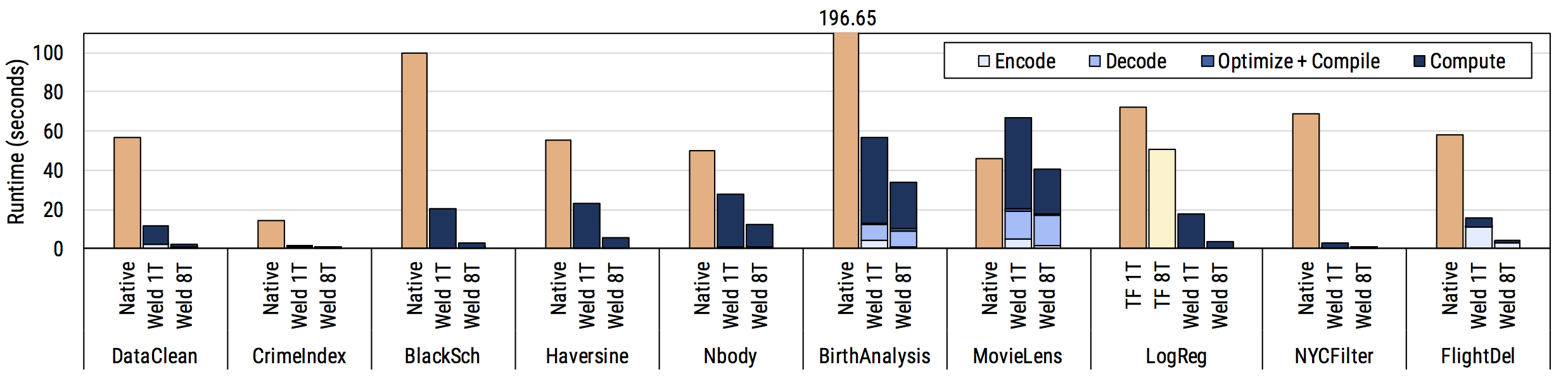
Our paper evaluates Weld’s optimizer on a set of 10 real data science workloads, ranging from using NumPy to compute the Black Scholes equation for share pricing, analyzing baby names using Pandas, using NumPy and TensorFlow to whiten images and train a model over them, using Pandas and NumPy to score cities based on crime, and so forth. The results are below: Weld consistently improves performance on a single thread, and also automatically parallelizes natively single-threaded libraries automatically. The plot shows that Weld’s automatic optimizer is effective in minimizing inefficincies caused by composing individual function calls and producing fast machine code.
How Much Does Each Optimization Matter?
To study how much of an impact each optimization has in our workloads, we also performed an ablation study in which we turned off each optimization one-by-one and measured the performance impact. The chart below summarizes what we found, on one and eight threads. The number in each box shows the slowdown after disabling the optimization, so a higher number means the optimization has higher impact. The numbers below the solid line show workloads with synthetic parameters (e.g., high vs. low selectivity) to show the impact of adaptive optimization. Finally, the “CLO” column shows the impact of cross-library optimization, or optimization of functions across library boundaries.
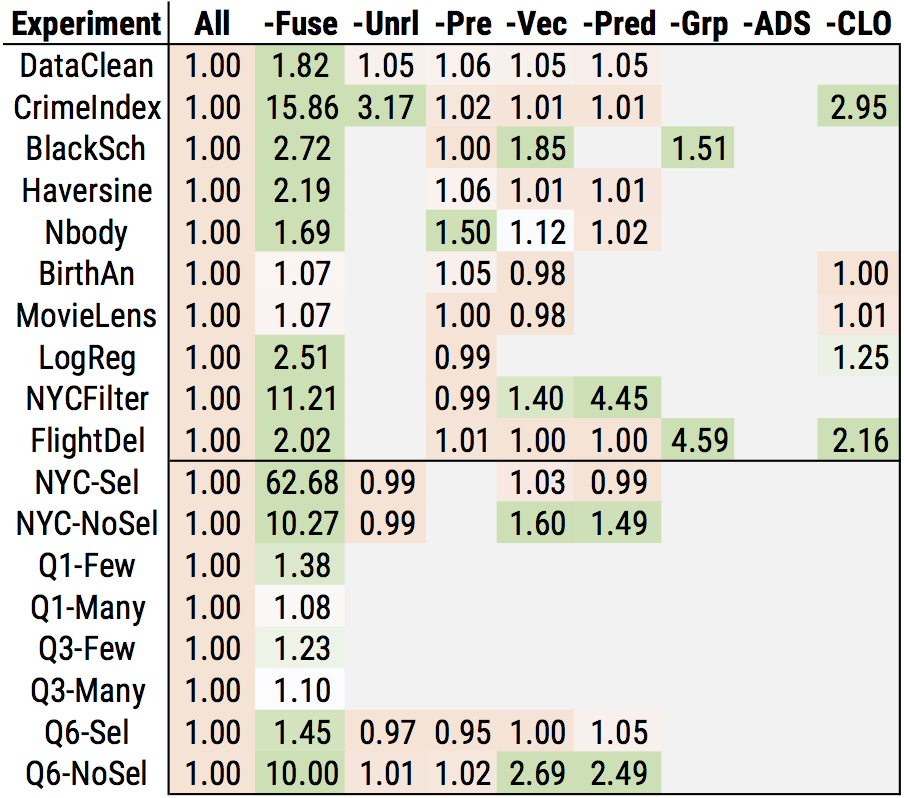
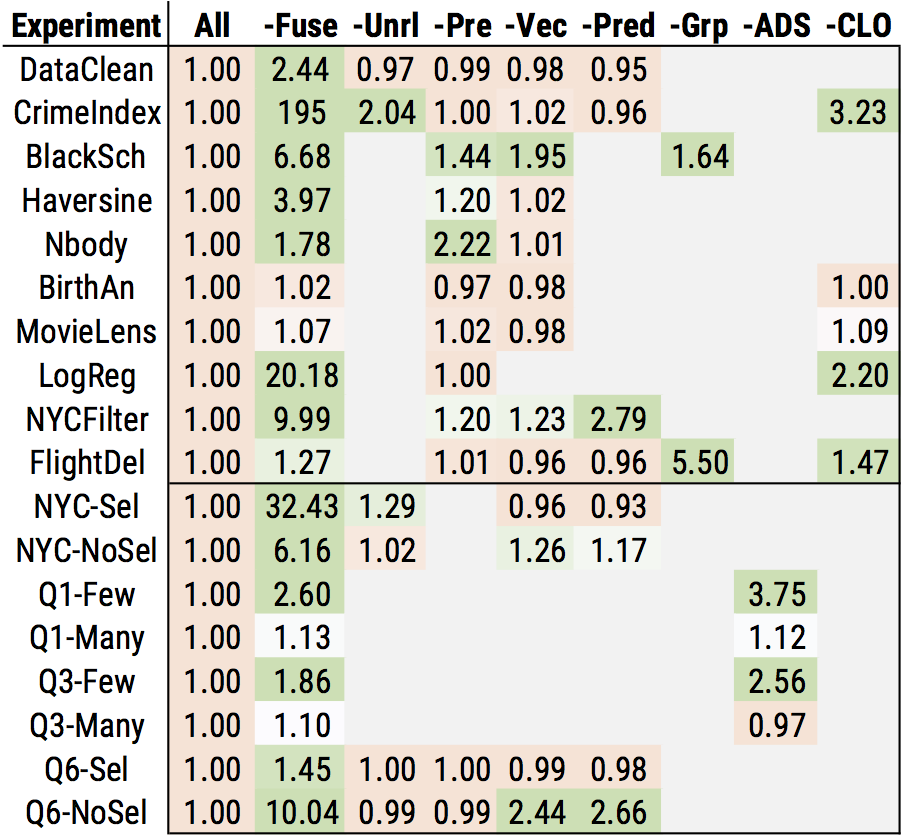
Overall, we see that many of the optimizations have a moderate to significant impact in at least one workload. In addition, cross library optimization has a fairly substantial impact, and can improve performance by up to 3× even after Weld applies optimizations within libraries. Our study also shows that a few optimizations are particularly important: namely, loop fusion and vectorization have a large impact in many of the workloads.
Summary
Weld is a new approach for enabling optimizations in existing workloads that combine data science libraries and functions, without requiring users of popular libraries to rewrite their code. Our automatic optimizer showed some promising results: we can speed up some workloads by orders of magnitude by automatically applying transformations over the Weld IR. Our ablation study shows that data movement optimizations such as loop fusion have a particularly high impact.
Weld is open source and developed actively by Stanford DAWN, and the code we use in our evaluation (weld-numpy and Grizzly, a partial implementation of Pandas-on-Weld) are also open source and available on PyPi. These packages can be installed using pip:
$ pip install weldnumpy
$ pip install grizzly
We hope to see you at our talk in Rio about our VLDB paper in August!