Using Provenance to Debug Training Data for Software 2.0
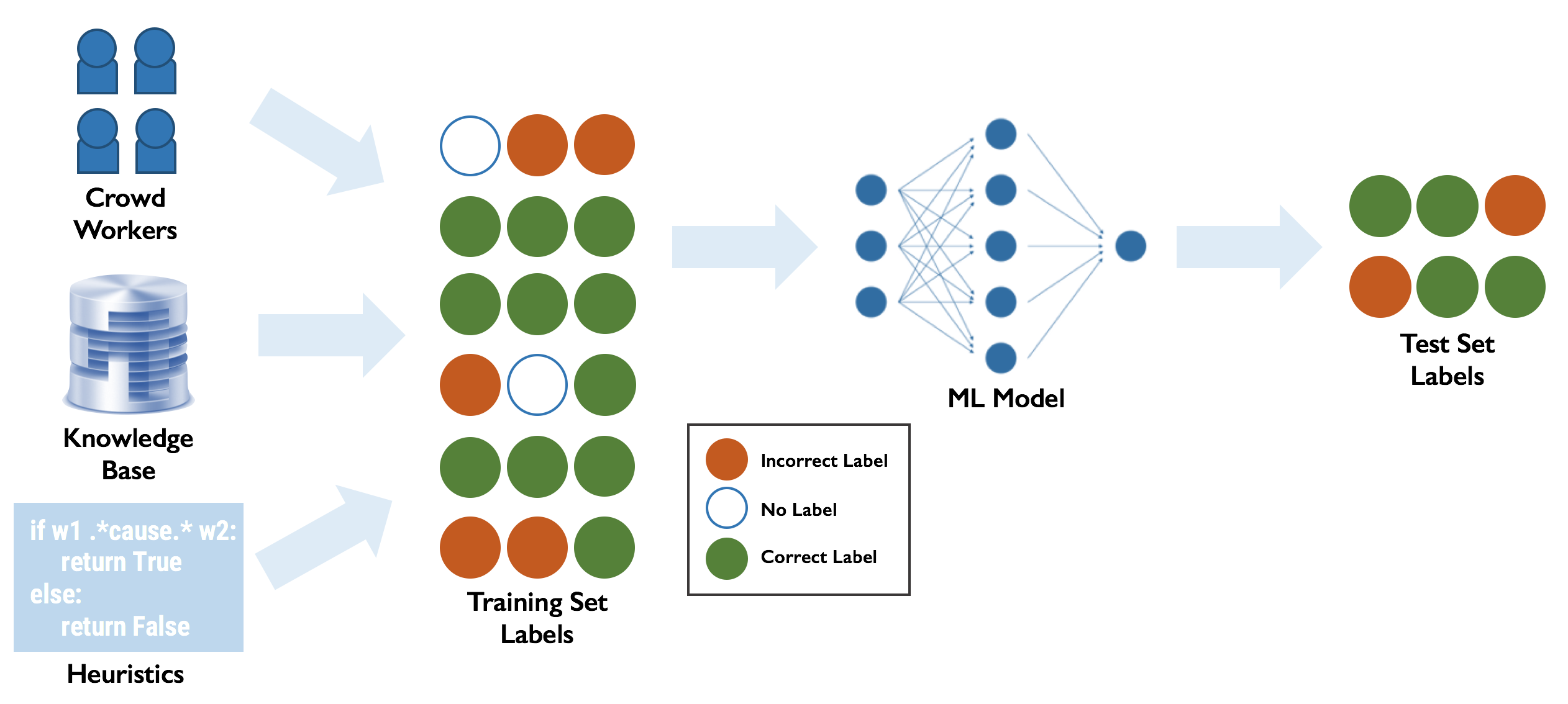
Training sets are often aggregated from multiple imperfect sources, which can lead to systematic errors in the training set. Opening the black-box of how training labels are generated can help debug training sets and improve end model predictions. We look at how our work on weak supervision can provide perspective for debugging training sets systematically and explore an interesting trade-off between domain expert and data scientist effort. Also check out our post on debugging machine learning pipelines and feedback about debugging machine learning from industry affiliates of DAWN!
As deep learning has matured, it has become increasingly common for neural networks to be used not just as another tool in a software stack, but as the entire stack! That is, Software 1.0 code with explicit instructions written by programmers is being replaced by Software 2.0 code that is written in the weights of neural networks [1], [2], [3]. This paradigm comes with many benefits: portability, agility, modularity, etc. But there’s no free lunch; along with these benefits comes an increased dependence on training data—lots and lots of training data. While standard benchmark datasets like ImageNet exist for tasks like object detection, most real world applications require creating new, task-specific training sets. Since hand-labeling such a large amount of data is tedious and time-consuming, people often rely on noisy sources of supervision like crowdsourcing, user-defined heuristic rules, and knowledge bases.
Unfortunately, training sets created from these techniques nearly always contain errors. In many cases, these errors are systematic and affect the performance of the machine learning model trained on this data significantly. Recent approaches have looked at using the behavior and predictions of the trained ML model to identify and correct errors in the training set while other approaches[1], [2] have looked at fixing errors in the underlying data or debugging model performance in general [1].
In this blog, we reflect on our experiences in the past two years working with Snorkel and other weak supervision systems using user-defined heuristics, natural language explanations, and automatically generated heuristics to label training data efficiently. These methods provide users with information about of how training labels are generated, which we can use to debug training sets systematically. We share some initial work on how information about training label generation affects debugging techniques and discuss some of the implications of these methods and the general debugging paradigm for those who label data and those who build models to learn from it.
Errors in Training Data Labels
Systematic label errors in the training set can occur due to a flawed label aggregation mechanism.
Consider two tasks: (A) music genre classification where crowd workers are asked to label what genre each music clip belongs to, and (B) determining whether a set of words and numbers represents a street address using a set of user-defined heuristics. We explore some scenarios that could lead to errors in the final training labels:
Varying Source Accuracies
- Instead of accounting for the fact that some workers might be musicians and therefore more skilled at labeling, the labels are assigned by taking a majority vote across all workers.
- Heuristics relying on general formatting rules work bette ron average than ones looking at specific road names etc.
We can correct this by accounting for groups of crowdworkers who are better at the task or heuristics that are more accurate on average than others.
Varying Data Difficulty or Latent Subsets
- Certain music clips are easier to categorize automatically via frequency analysis than for humans to label manually.
- Heuristics meant for address formats for a specific country perform very poorly on addresses from different countries.
We can correct this by accounting for latent subclasses in the data that are poorly accounted for by the crowdworkers or heuristics.
Hidden Source Correlations
- People from a certain geographic region are likely to have a similar sense of music genres. If we view these workers as being independent, we essentially “double count” their geographic biases.
- The heuristics we use rely on some existing knowledge base of addresses in order to label if an address is correct or not. However, all the heuristics rely on independent subsets of the same knowledge base and are therefore prone to making the same mistakes, which we can end up “double counting”.
We can correct this by accounting for underlying dependencies among the different crowdworkers, such as shared geography or shared supervision sources (e.g., a knowledge base).
Opening the Training Set Generation Box
To automatically correct these errors in the label generation/aggregation process, we need to stop viewing the training set creation process as being black-box.
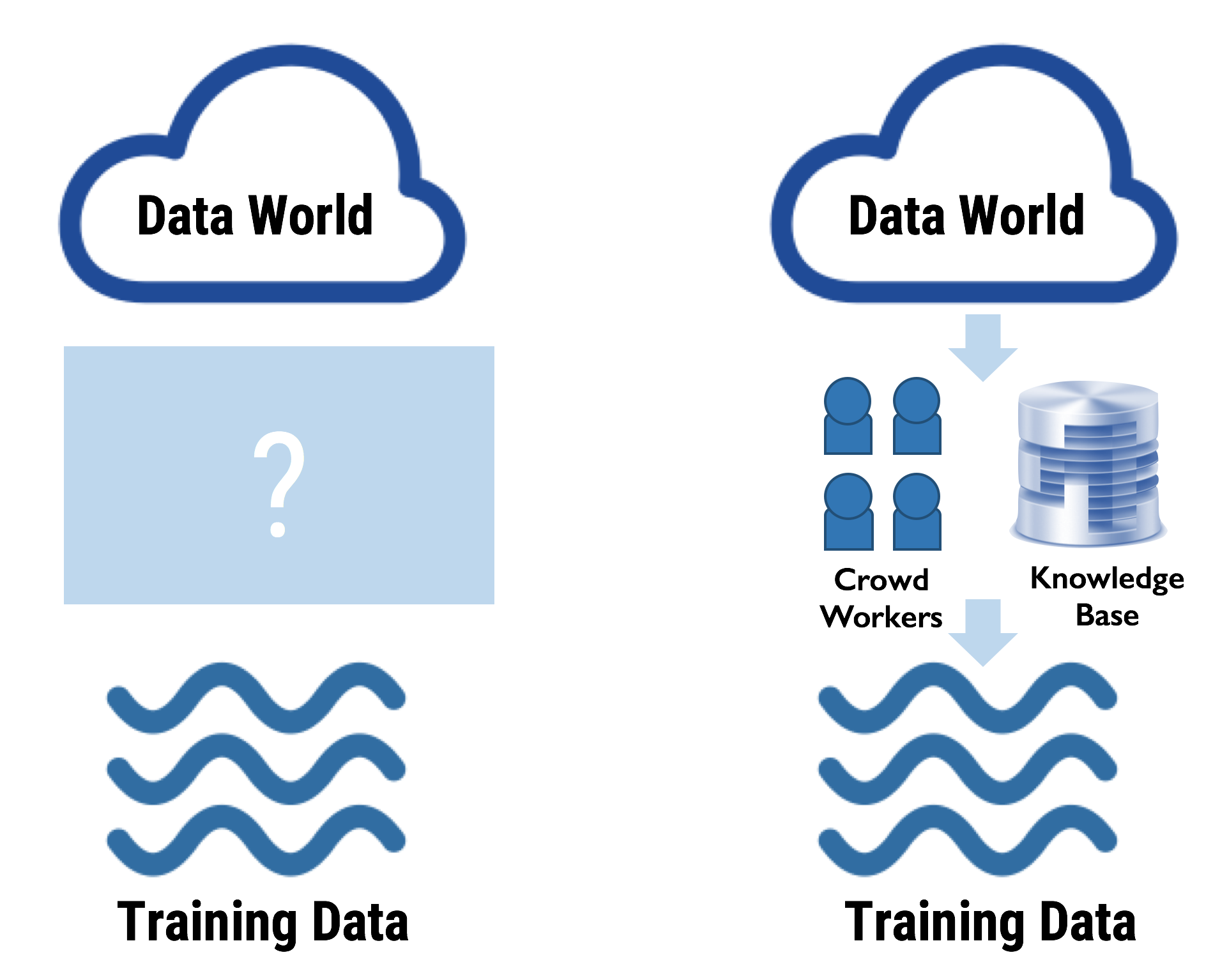
A common theme in the correction strategies proposed above is looking at where the training data is coming from. Increasing transparency of the generation process for final training labels gives us the power to automatically debug various stages of the label generation pipeline.
Increased Transparency = Increased Debugging Ability
How can we use these different levels of information about the training set to debug them? We use some of our work in the weak supervision space to explore our first attempt at separating how much provenance we have about the training set into four categories and mapping it to some debugging techniques it gives us access to.
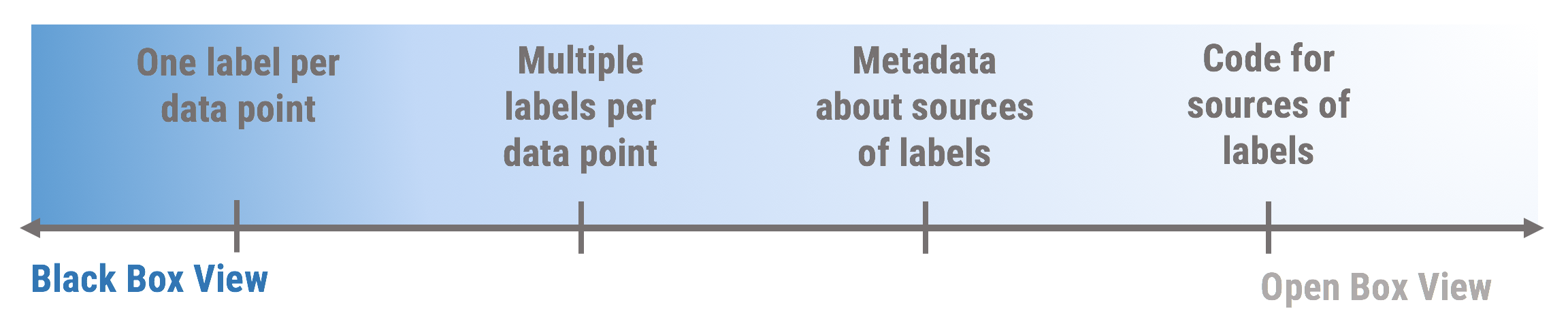
Stage 2: Multiple Labels per Data Point.
Given multiple labels per data point (e.g., from multiple crowdworkers or heuristics), data programming describes a method to learn the accuracies of the different sources of labels using the disagreements among them. Socratic learning builds on this concept to look for latent classes in the training set by using feedback from the end machine learning model being trained. Structure learning also learns dependencies among the sources by relying only on the labels provided by the sources.
Stage 3: Metadata about Labeling Sources
Learning dependencies from multiple data points is practical when there is enough data to learn from and the dependencies are pair-wise. For higher degree dependencies and in cases with a smaller training set, relying on metadata about the sources is more reliable for inferring latent dependencies among sources. Coral utilizes information about which knowledge bases or heuristic primitives labeling sources rely on to find similarities among the sources. This method of finding dependencies among sources of labels without data can also be extended to the crowdsourcing setting, relying on metadata like geographic location, time of labeling etc. to infer dependencies.
Stage 4: Code for Sources of Labels
In the final stage, we have access to the underlying mechanism that generates the labels for training data. For heuristic-based labeling, this consists of the code for the heuristic functions. For crowdsourced labels, this may be explanations of why the crowd worker assigned a particular label to a data point. Coral does the former with static analysis of the code for heuristic functions, and Babble Labble has shown exciting results for the latter case. Another project goes a level beyond simple debugging and generates new heuristics based on a small, labeled dataset. Given source code of the heuristics, this can be extended to correcting the heuristics directly.
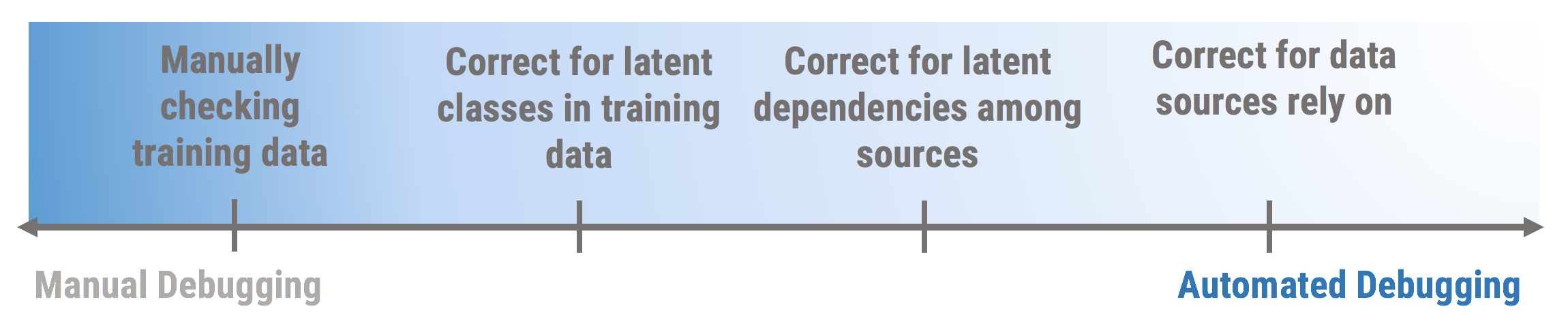
Increased Debugging Ability = Increased Performance?
We only want to debug the training set if it leads to improved end model performance. We show some preliminary results comparing the different stages of debugging to the fully supervised model (i.e., where the training set is 100% correct). While we see that increased automated debugging almost always leads to an increase, there are cases where we can stop at an earlier debugging stage and match performance of a later stage (like the Mammogram dataset below).
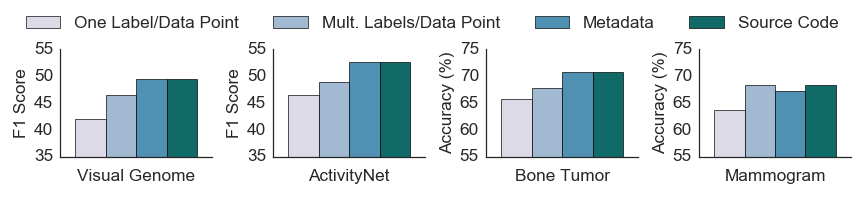
Data Scientist vs. Domain Expert
As we move towards the open box view of the training set generation process to make it easier to debug training sets for domain experts, we require domain experts to spend more time documenting the labeling process.
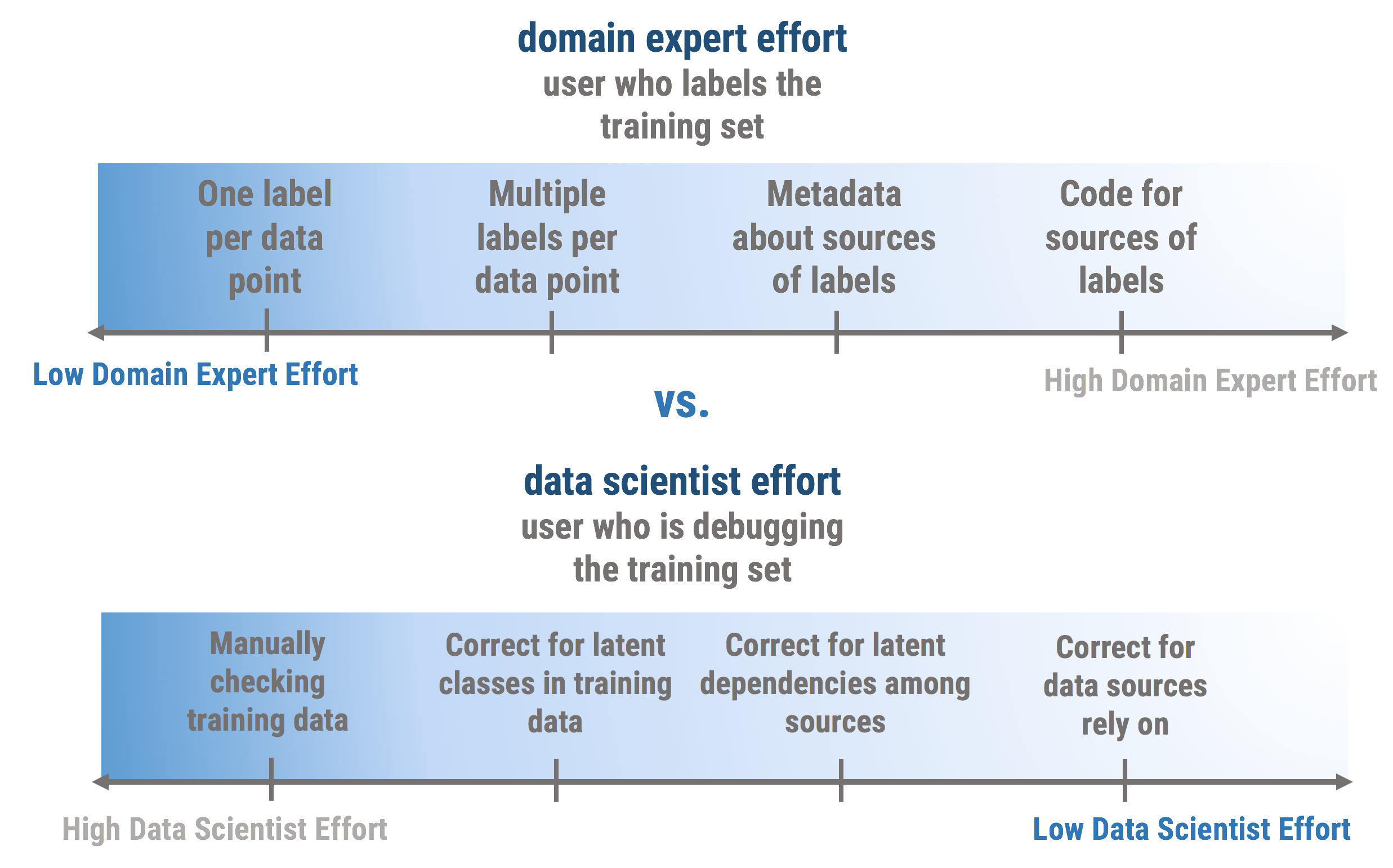
To gain maximum transparency about the training label generation process, domain experts may be asked to record how they label their data using something like a global schema, with a consistent format for heuristics or reasoning for assigning labels that allows data scientists to access information up to Stage 4 for the complete “lineage” of the generated labels. The user effort would shift from the data scientist, who looks at the final training set labels, to the domain expert, who has the knowledge necessary to label the data. However, along the spectrum, there are reasonable trade-offs between the data scientist and domain user; for example, crowdworkers usually label multiple data points, moving their supervision to Stage 2 of the pipeline.
This leads us to the last part of this debugging paradigm - how do we decide the level of abstraction to study when debugging a particular training set? In some cases, correcting for the latent classes in the training set might be enough to account for all distribution errors; in other cases, we need the complete ”lineage” of the training data to properly debug it. This choice can be affected by the kind of training data being used, the label aggregation and generation process, and various other factors. Our exploration in this blog is a first step in our effort to better understand the space of techniques to systematically debug training data and the research questions associated with it!