Weld v0.2.0 Released with New Features and Improved Performance
The Weld developers are happy to announce a new version of Weld, v0.2.0. Weld is a language and runtime for fast in-memory data analytics. It enables optimizations across operators within existing libraries as well as operators across Weld-enabled libraries.
We have also released new versions of two Weld-enabled Python libraries: Grizzly v0.0.5 and weldnumpy v0.0.1. Grizzly is an accelerated subset of the Pandas data frame library, and weldnumpy accelerates the NumPy numerical computing library.
What’s New in Weld v0.2.0
The core Weld package includes a number of new features and usability
improvements. Developers can use Weld by linking it as a standard dynamically
linked C library. The library can be compiled and installed using the directions
here. Weld is also available as a Rust
package on crates.io – just add it to your
Cargo.toml to use it!
Weld’s API can also be accessed using the Python package pyweld. Users can
install pyweld using PyPi:
$ pip install pyweld
New Core Features
Weld v0.2.0 contains a number of new features in its runtime and IR, described below:
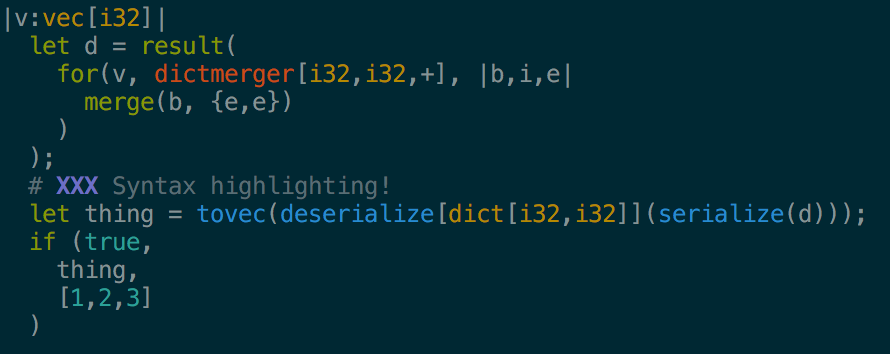
- Serialization and deserialization of data types, allowing data from the Weld runtime to be written to disk or shuffled across the network.
- Comments in the Weld IR.
- ASCII string literals in the Weld IR.
- Various new mathematical operators, including
maxandmin, trigonometric functions, and hyperbolic functions. - Ability to dump optimized Weld, LLVM, and assembly code to file upon
compilation for debugging (see the
weld.compile.dumpCodeoption). - Ability to trace execution at runtime for debugging (see the
weld.compile.traceExecutionoption). - Improvements to the REPL, such as the ability to set logging levels, set compilation options, and read files as input.
- A new
hdrgenutility that generates a C++ template file given a Weld IR file. The template file contains definitions for the argument and return types of the input IR program. vimsyntax highlighting. Check out the weld.vim repository.
Improvements
In addition, Weld v0.2.0 also brings a number of improvements to performance and stability:
- Compilation times have been reduced substantially: larger programs now compile up to 10 times faster than before!
- Workloads that use dictionaries exhibit improved performance thanks to a new hybrid thread-local/global dictionary design.
- Workloads using strings with dictionaries exhibit better performance due to an optimized, specialized string hash function.
- Performance on small nested loops has improved by decreasing runtime overheads.
- The performance of the
mergerbuilder type has been improved in the multi-threaded setting, making workloads that perform aggregations more efficient.
weldnumpy v0.0.1: A Weld Wrapper for NumPy
weldnumpy is a Weld-enabled wrapper for NumPy, a popular numerical computing library for Python. Unlike the standard NumPy package, weldnumpy is lazily evaluated and thus supports Weld optimizations such as loop fusion and vectorization.
weldnumpy can be used as a
drop-in
replacement for NumPy, because it
automatically defers to native NumPy when a user calls an unsupported function.
The weldnumpy package natively supports most NumPy math operators (e.g., log,
exp, and trigonometric functions).
You can install weldnumpy using PyPi:
$ pip install weldnumpy
This link has detailed instructions on setting up and using weldnumpy.
Grizzly v0.0.5: Accelerating Pandas
We also recently released a new version of Grizzly, an accelerated subset of the Pandas data science library that is easy to integrate in existing Pandas applications. Like weldnumpy, Grizzly can be installed via PyPi:
$ pip install pygrizzly
This link has detailed instructions on setting up and using Grizzly.
New Grizzly Features
This version of Grizzly adds native support for a number of popular Pandas features:
- Support for Pivot Tables.
- Richer grouping support, such as groupBy on vectors instead of just scalars and the ability to compute standard deviations.
- Sort functionality on DataFrames and Series.
- Group evaluation – this is an optimization that allows computing multiple results that the user wants evaluated at once, which can often lead to improved performance.
We’d love your feedback and comments on these new features! For support, subscribe to the Google Group. You can contact the developers at weld-group@lists.stanford.edu. We also love contributions from people trying out Weld, so leave us an issue or pull request on Github!