Deep Learning Pitfalls Encountered while Developing DAWNBench
In December, we introduced DAWNBench, the first deep learning benchmark focused on end-to-end training and inference time at a state-of-the-art accuracy. Despite the successes of deep learning, achieving state-of-the-art accuracy remains surprisingly difficult with pitfalls hidden behind inconsistent evaluation, underspecified metrics, complex tuning, and conflicting implementations. This blog outlines several of the lessons we learned while building DAWNBench, which we hope will save researchers and practitioners time, and illustrate the various issues associated with using deep learning in practice.
Lesson 1: The Importance of Quality Metrics
Most previous deep learning benchmarks measure only speed or accuracy, but not both. Throughput, e.g., examples per second, only provides a proxy for end-to-end training time. Techniques such as using larger batch sizes, reduced precision, and asynchronous updates can stop an algorithm from converging to a good result, or increase the time to do so. When used in combination, these techniques can interact in non-trivial ways, making end-to-end performance harder to reason about. Additionally, while accuracy is necessary for any deep learning system, it is not sufficient. Instead, in DAWNBench, we measure both using an objective metric: time to train to a target validation accuracy near the state-of-the-art, and time to perform inference at that accuracy.
A critical decision we needed to make was choosing a clearly defined metric for statistical performance. Some machine learning research evaluates statistical performance in terms of training loss or similar metrics that serve as proxies for learning and generalization. For example, recent results have shown a bug in the proof of Adam and suggest SGD is competitive with adaptive methods. The original Adam paper contained no results with validation accuracy (only with training loss), which could have led to this oversight. In our work on DAWNBench, we discovered first-hand that Adam was unable to come close to the maximum validation accuracy we were able to achieve with our SGD with momentum baseline. Despite the marginal value of adaptive gradient methods in machine learning, Adam is widely used in practice and is a default for many people new to deep learning. Using the right evaluation method for statistical performance could help avoid many false conclusions and lead to better systems.
Even with the right evaluation criterion that seems universally agreed upon, we were surprised to find that certain tasks lacked a common ground truth for accuracy. We planned to include WMT English-German Machine Translation in the initial release of DAWNBench, but calculating the BLEU score was inaccurate and inconsistent across the frameworks and code we considered, because the way the reference text was tokenized dramatically affected the BLEU score. To prevent this, the WMT organizers have done tremendous work in creating sacrebleu as a standard BLEU implementation that manages WMT datasets, produces scores on detokenized outputs, and reports a string encapsulating BLEU parameters, facilitating the production of shareable, comparable BLEU scores. Without standardized definitions, evaluating deep learning systems can be incredibly difficult and inconsistent.
Lesson 2: Lack of Verified Implementations
In addition to defining a set of objective metrics for end-to-end performance, DAWNBench included a number of seed entries for each of the categories using existing implementations of standard models in popular deep learning frameworks. In generating the seed entries, we tried to reuse as much existing reference code as possible.
However, we found that the reference implementations were often incomplete or buggy! In the case of image classification, the pace of deep learning research led to numerous variations of architectures such as residual networks (ResNet). Unfortunately, implementations of these variations were not distinguished; we found ResNet implementations in popular deep learning frameworks having some subtle differences: one implementation used a basic block with pre-activation (described in Identity Mapping in Deep Residual Networks), and another used a leaky ReLU activation instead of regular ReLU. These small changes can lead to substantial differences in accuracy or time to a target validation accuracy.
Even after verifying the model architecture in open-source implementations, there were still many issues reproducing reported results. For example, one popular deep learning framework offered two examples of ResNet: a quickstart example that does not follow the recommended practices for optimal hardware performance, and a high-performance implementation. While faster, the high-performance implementation had a bug that prevented it from training to a high accuracy: the final model’s accuracy was 5% below what the original ResNet model achieved. Another popular deep learning framework offered a sample ResNet implementation, but no end-to-end code to run training on ImageNet. Despite considerable effort and communication with the developers, we were unable to achieve the published validation accuracy for any task with this implementation.
To circumvent these problems, we provide the working implementations we used to generate seed entries for DAWNBench as references.
Lesson 3: Non-trivial Interactions Between Optimizations
Finally, one of our primary motivations for developing DAWNBench was to understand the state of the field. New optimizations for training these computationally expensive models are proposed every week, but how do they interact? For example, minimal-effort back propagation and 8-bit precision give a 3.1x and 3x speedup on MNIST, respectively. Could we combine these with large minibatch training to reduce the time to train an ImageNet model from 60 minutes to 7 minutes? Currently, only tedious and time-consuming experimentation can answer these questions. Moreover, which previous techniques should one build on when evaluating the efficiency of a new optimization?
As a preliminary study, we combined the following optimizations for ResNets: stochastic depth, multi-GPU training, and large minibatch training. We found that these optimizations do not compose in terms of performance, as shown in the graphs below taken from our NIPS ML Systems workshop paper.
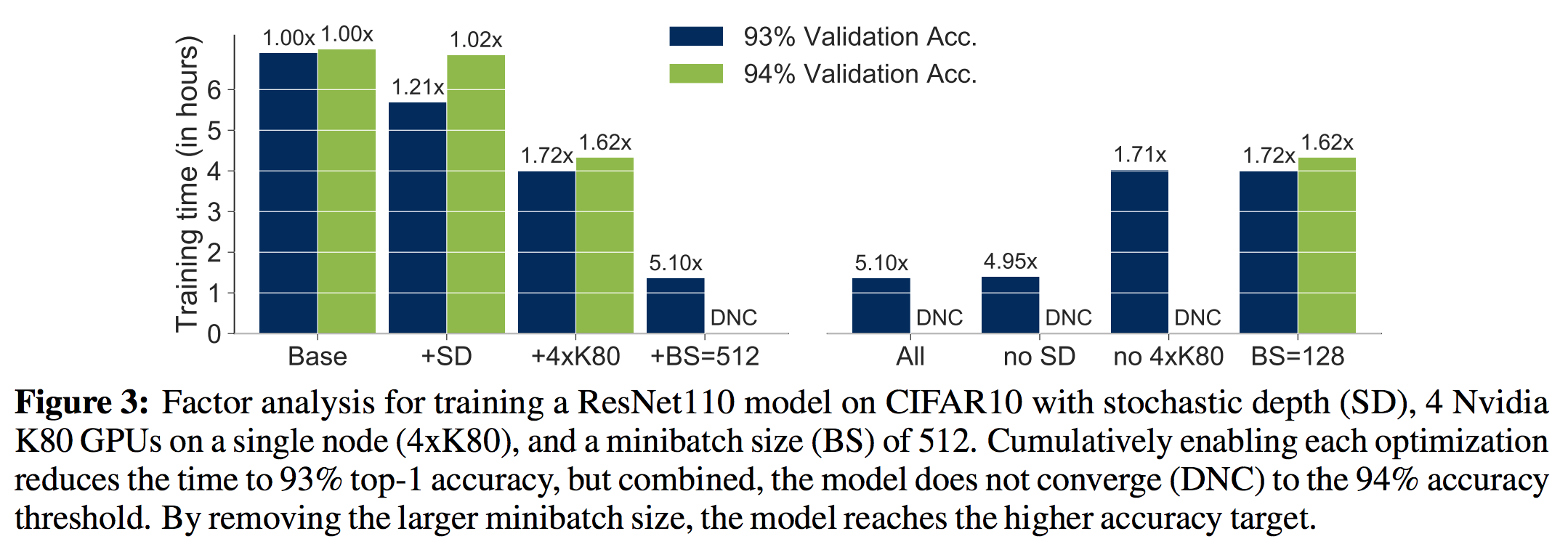
Stochastic depth should give close to a 1.25x speed up in total training time without affecting accuracy on ResNet110 according to the original paper. Using 4 GPUs rather than 1 GPU should give a 4x speed up without loss in accuracy assuming perfect scaling and a large enough batch size to saturate the additional hardware. However, our experiments show that increasing the batch size harms the overall accuracy, such that the model does not converge to the target accuracy. Keeping the batch size constant but adding stochastic depth and additional GPUs reaches the target accuracy with only a 1.62x speed-up, which is far from the ideal 5x. Without standard ways to run and tune different optimizations jointly, composing optimizations may affect the convergence rate of the algorithm, which in turn makes performance hard to reason about.
Closing Thoughts
Deep learning is a powerful tool that has proven to be successful in a variety of domains, but to wield it effectively requires expertise learned through trial and error. Through our first-hand experience developing DAWNBench, we have outlined some pitfalls in deep learning systems caused by inconsistent evaluation, underspecified metrics, conflicting implementations, and non-trivial interactions, which we hope will save researchers and practitioners time in the future. Moreover, DAWNBench provides an objective means of normalizing across differences in computation frameworks, hardware, optimization algorithms, hyperparameter settings, and other factors that affect real-world performance. By defining a concise set of tasks and metrics, our goal is to foster a quantitatively-informed dialogue around progress in deep learning systems.