Exploiting Building Blocks of Data to Efficiently Create Training Sets
The ability of deep learning models to achieve state-of-the-art performance is grounded in the availability of large, labeled training sets. However, gathering this magnitude of ground truth labels is expensive and time-consuming. While users can write rules that check for specific words or patterns in text data, developing such heuristics for image or video data is challenging since the raw pixels are difficult to interpret.
To address this issue, we present Coral, a paradigm that allows users to write heuristics to label training data efficiently using low-level, interpretable characteristics of their data. In this blog post, we
- provide examples of these interpretable building blocks and how heuristics use them to assign labels efficiently
- discuss how we can aggregate labels from these heuristics into training set labels by encoding information about the structure of these heuristics into a statistical model
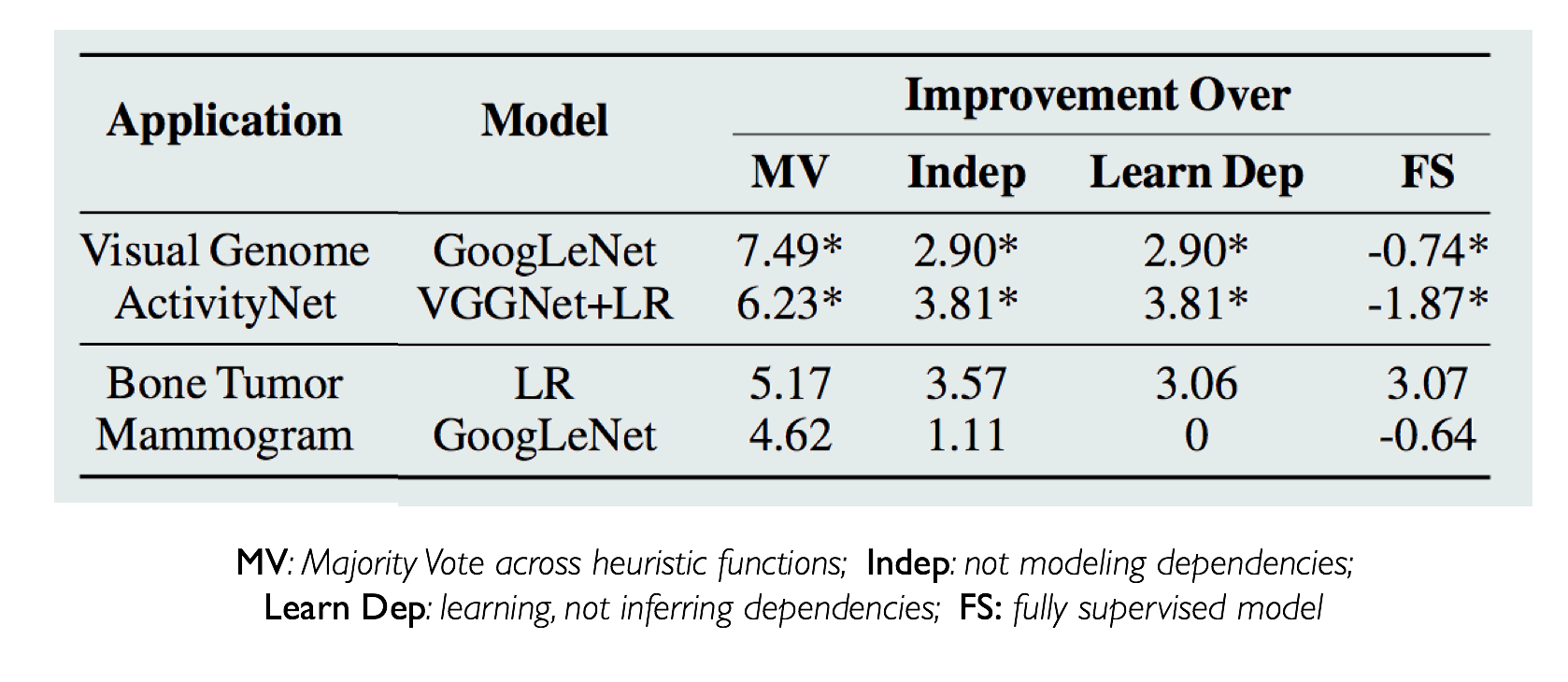
- report selected results where Coral is able to achieve within 0.74 F1 points of a fully supervised model and outperform a fully supervised model by 3.07 points when additional unlabeled data is available.
You can also read our NIPS 2017 paper for more details!
Domain-Specific Primitives: An Interpretable Vocabulary for Weak Supervision
Domain-specific primitives are interpretable, low-level characteristics of the data that allow users to write heuristics over them.
The advent of deep learning has obviated the burden of feature engineering, instead relying on large, labeled training sets. While training sets like ImageNet and YouTube 8M exist for benchmark image and video detection tasks, using these state-of-the-art models for real-world problems requires users to hand-label large magnitudes of data in their domain. A recent solution adopts weak supervision, a paradigm in which noisy sources of labels, such as user-defined heuristics, are used to label data efficiently. Previous work from our lab has shown that weak supervision can assign noisy labels to large magnitudes of unlabeled data and subsequently train complex models like CNNs and LSTMs.
While weak supervision for text-based data can come from rules that rely on complex regex patterns or parts-of-speech, describing non-text data such as video and images in a similar manner is challenging. For example, describing the size of the dark patch in the X-ray image below or counting the number of bikers is difficult via heuristics that only have access to the raw pixel values.
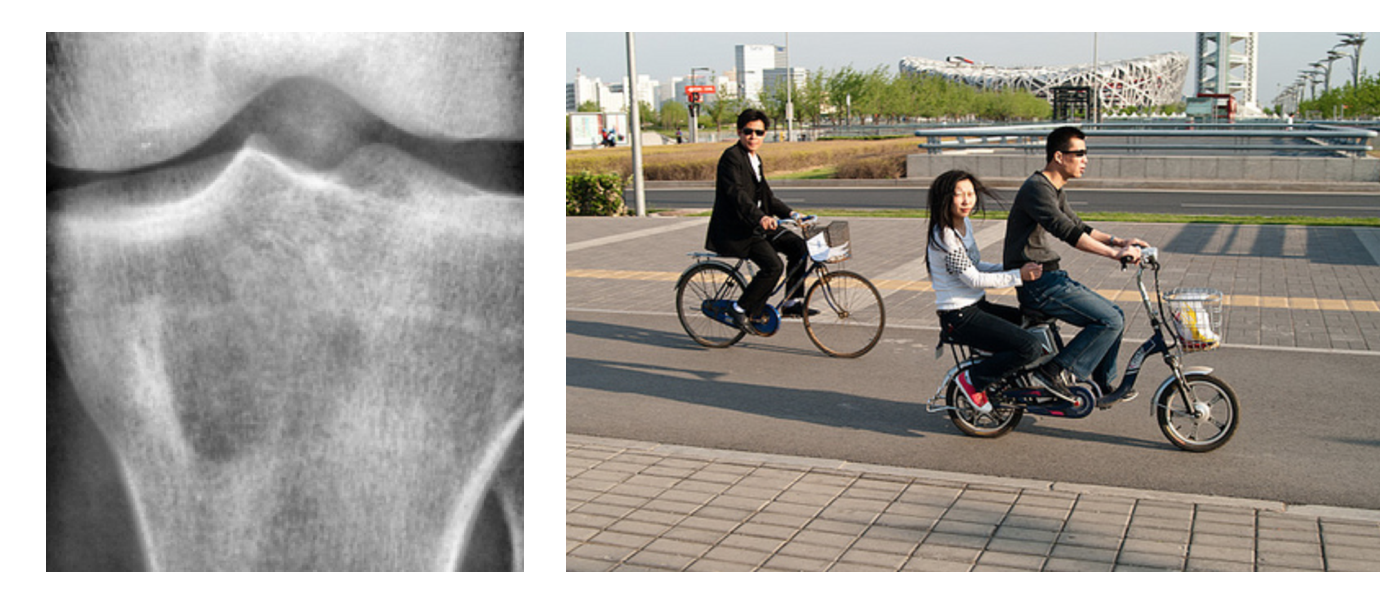
To apply weak supervision to these data types, we require an interpretable layer of abstraction, which encodes important characteristics of the raw data. We refer to these easily obtainable building blocks as domain-specific primitives (DSPs). These DPSs can take a variety of forms, such as bounding boxes and associated labels for natural images, and characteristics like area and perimeter for regions of interest in medical images. Moreover, pipelines to extract such characteristics from the raw pixels already exist, such as state-of-the art object detection pipelines and feature extraction algorithms from the pre-deep learning era.
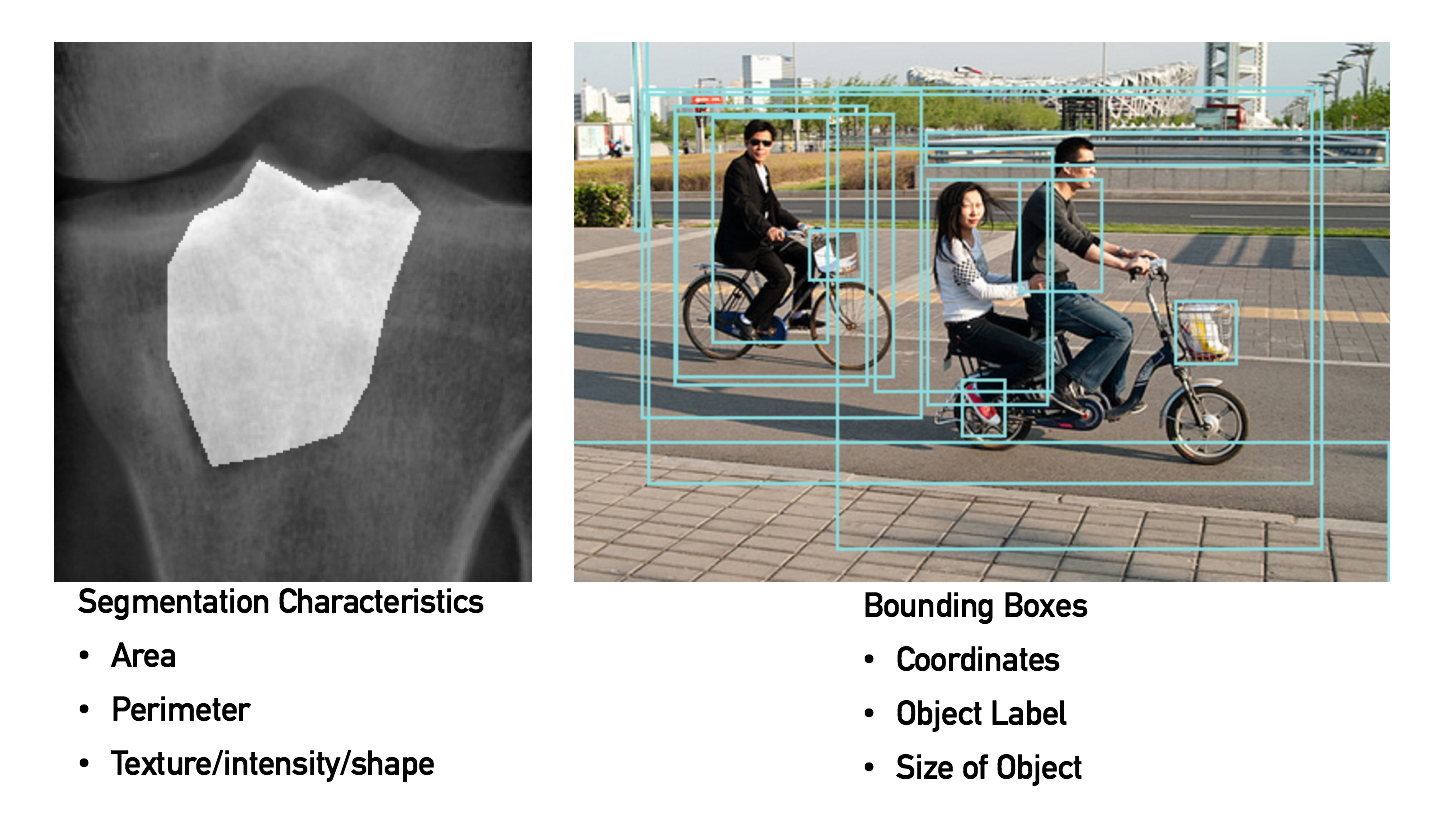
Re-purposing the outputs of existing pipelines, such as bounding boxes from object detectors, allows users to develop heuristics that encode complex relational information. For example, bounding boxes around all humans and bicycles in an image can help users write heuristics to determine whether there is a person riding a bike in a given image.
Identifying and Modeling Correlations among Heuristics
By using the structure of the code that generates domain-specific primitives and heuristics, we can account for heuristic correlations when assigning training labels.
In our paper, we describe how we combine labels from the different heuristics into a single training label for each data point. Moreover, we also incorporate knowledge about how the heuristics generate the labels into our statistical model, which helps us generate high-quality training labels. To explore how we define our statistical model using heuristic structure, we look at a specific example in which we have access to the images and bounding box attributes about objects in the image. In this case, we define our task to label images for the query “is there a person riding a bike in this image”. As shown below, these heuristics can operate over various DSPs, such as height and area, to encode relations among objects and assign labels to the images accordingly.

When combining noisy labels from various heuristics, it is essential to account for any correlations that may exist among the different sources to avoid “double-counting” votes from these sources (details here). Learning these correlations based only on the assigned labels results in a sample complexity that scales sub-linearly in the number of possible binary dependencies and exponentially in the degree of the dependencies. For real-world experiments, this translates to requiring an impossibly large number of samples to learn correlations that occur among many heuristics. However, we do not need to necessarily learn all the correlations when we know how the heuristic functions were encoded via their programmatic representation in a language like Python.
Accounting for Shared Heuristic Inputs
We use the programmatic nature of the heuristics and DSPs in order to infer, rather than learn, correlations. The simplest way to exploit the programmatic nature of the heuristics is to check whether they share primitives automatically using static analysis. In the example below, both the second and third heuristic functions rely on the height of the bounding boxes, denoted by P.h. We can simply look at the inputs to the functions and incorporate the dependency between the second and third labeling function in the generative model.

Analyzing Primitive Compositions
However, in the next example, even though there are no shared DSPs, we know that P.area and P.h have to be correlated in some manner since one encodes the area and the other the height of the bounding boxes. In this case, looking at the inputs of the different functions is not enough; we also need to look at how the DSPs are composed in order to see that P.area is created by multiplying P.h and P.w.

Learning Primitive-Level Similarities
Finally, there might be cases in which primitives can be correlated with other primitives (like P.area and P.perim) but not be explicitly composed using the same base primitives of P.h and P.w. In such a situation, just using static analysis will not be enough to pick up correlations among second and third heuristics. Therefore, we turn to statistical methods to learn correlations among the primitives, and details are described in the paper.

Relying only on static analysis to infer correlations reduces the sample complexity to quasi-linear in the number of total heuristic functions. Coral is therefore able to account for correlations among heuristics accurately, thus improving the performance of the machine learning model trained on the labels from Coral’s model by up to 3.81 F1 points.
Competing with Fully Supervised Models
Coral outperforms baseline techniques and beats fully supervised approaches given additional unlabeled data.
We apply Coral to a variety of image and video data, including natural and radiology images. Details about the data sets and specific results are included in the paper. For each task, we compare the performance of a discriminative model, like GoogLeNet, trained on labels generated by ground truth training labels (FS), majority vote (MV) across heuristics, a model that assumes independence (Indep) among the heuristics, and one that learns correlations (Learn Dep) instead of inferring them. Within the Coral paradigm, we split results by whether the dependencies only relied on heuristic correlations or also learned DSP correlations.
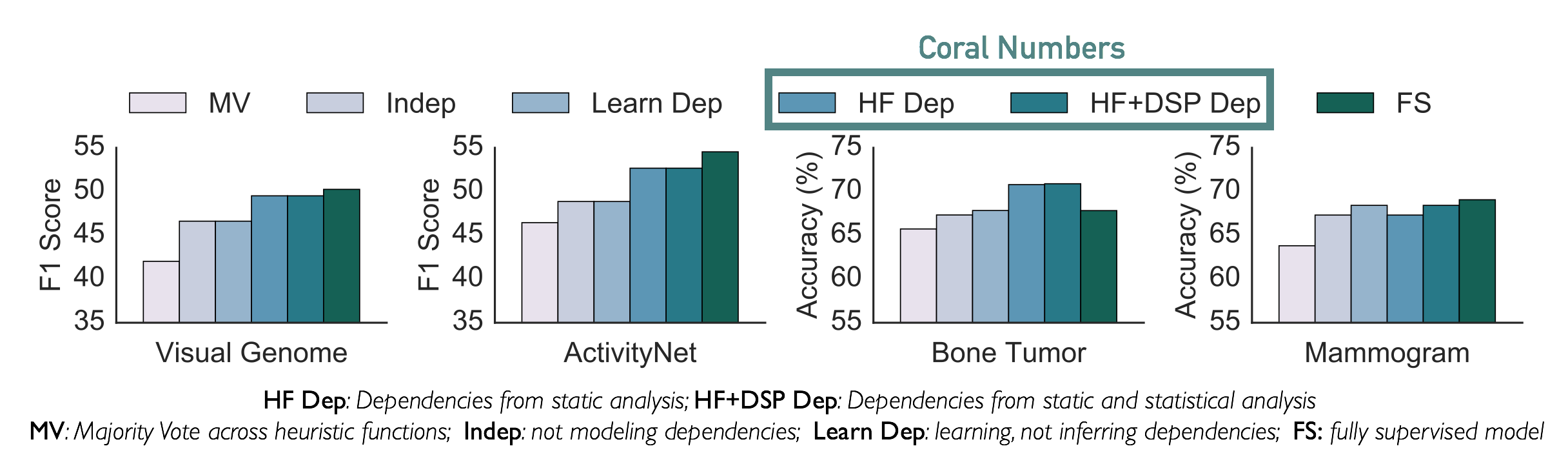
We highlight the Bone Tumor data set, in which we had a small collection of ground truth labels and access to twice as many unlabeled images. The availability of ground truth data, in addition to modeling the primitive and heuristic level correlations using Coral, led to an improvement over the fully supervised model by 3.07 points.
The second task we highlight is the Visual Genome data set, where we collected ground truth training labels from the rich, relational information available in the image database. Using only 5 heuristics and bounding box information from Visual Genome, Coral is able to get within 0.74 F1 points of the fully supervised model. The compositional nature of the DSPs allows us to write simple heuristics that are noisy, but together can capture the necessary information to train discriminative models for complex object relation-based queries.
Future Directions
With Coral, we showed that users can encode heuristics over low-level, interpretable characteristics of their data to create training sets for complex image and video classification tasks. We also showed how Coral can infer correlations among the heuristics by using the structure of the code that defines the heuristics and DSPs. We are very excited to pursue this direction and are currently looking into
- Transfer Learning for Weak Supervision: Learning primitive-level accuracies and transferring this information across different tasks.
- Estimating Heuristic Function Structure Automatically: Inferring the threshold used in the heuristics (e.g. the
2in2*P.areain the third heuristic) that users develop automatically in order to optimize training label quality.