Learning to Compose Domain-Specific Transformations for Data Augmentation
Data augmentation is a popular technique for increasing the size of labeled training sets by applying class-preserving transformations to create copies of labeled data points. In the image domain, it is a crucial factor in almost every state-of-the-art result today. However, the choice of types, parameterizations, and compositions of transformations applied can have a large effect on performance, and is tricky and time-consuming to tune by hand for a new dataset or task.
In this blog post we describe our new automated method for data augmentation:
- We represent transformations as sequences of incremental black-box operations.
- We then learn a generative sequence model that produces realistic, class-preserving augmentations using adversarial techniques over unlabeled data.
- We observe gains over heuristic approaches—4 points on CIFAR-10, 1.4 F1 points on a relation extraction task, and 3.4 points on a mammography tumor classification task—and demonstrate robustness to user misspecification.
Check out our paper (NIPS 2017) for detail and references, and our code to give it a spin!
Automating the Art of Data Augmentation
Modern machine learning models, such as deep neural networks, may have billions of free parameters and accordingly require massive labeled training sets—which are often not available. The technique of artificially expanding labeled training sets by transforming data points in ways which preserve class labels—known as data augmentation—has quickly become a critical and effective tool for combatting this labeled data scarcity problem. And indeed, data augmentation is cited as essential to nearly every state-of-the-art result in image classification (see below), and is becoming increasingly common in other modalities as well.
For being such a simple technique, data augmentation leads to remarkable gains. But like everything in machine learning, there’s a hidden cost: the time required to develop data augmentation pipelines. Even though it’s often simple to formulate individual transformation operations, it’s generally time-consuming and difficult to find the right parameterizations and compositions of them. And these choices are critical. Many transformation operations will have vastly different effects based on parameterization, the set of other transformations they are applied with, and even their particular order of composition. For example, a brightness shift might produce realistic images when applied with a small rotation, but produce a garbage image when applied along with a saturation enhancement. This problem is only exacerbated for a new task or domain, where performant data augmentation strategies have not been worked out by the community over time. In general, practitioners just randomly apply heuristically tuned transformations, which, while helpful, is far from optimal.
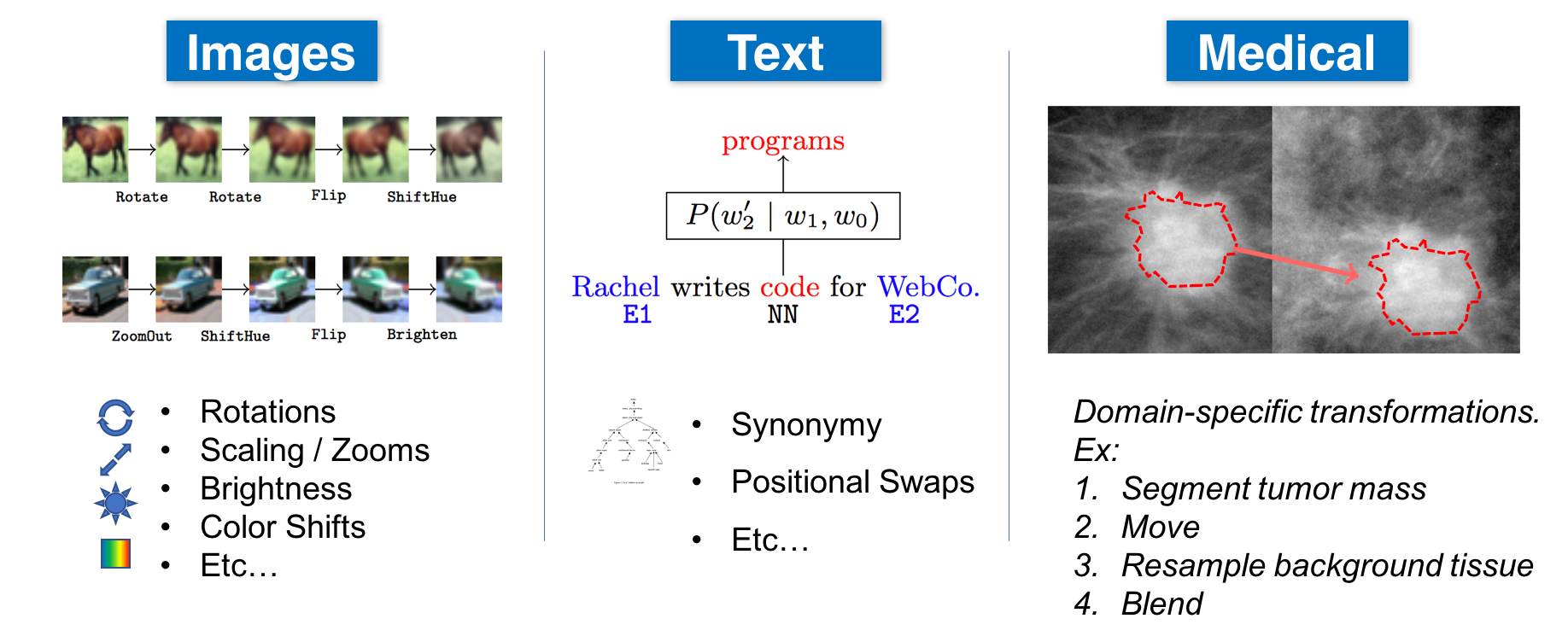
In our view, data augmentation can be seen as an important form of weak supervision, providing a way for subject matter experts (SMEs) to leverage their knowledge of invariances in a task or domain (see examples above) to improve model performance even given limited labeled training data. As such, our goal is to make it easy enough to deploy for any new, real-world task with its own specific types of invariances and transformation operations—without requiring days or weeks of tuning and tweaking. Moreover, an ideal data augmentation system should permit arbitrary, black-box transformation operations—thus serving as a flexible, model-agnostic way for SMEs to inject domain knowledge into machine learning pipelines.
In our proposed system, users provide a set of arbitrary, black-box transformation functions (TFs)—representing incremental transformation operations, such as “rotate 5 degrees” or “shift by 2 pixels”—which need not be differentiable nor deterministic, and an unlabeled dataset. We then automatically learn a generative sequence model over the TFs using adversarial techniques, so that the generated transformation sequences produce realistic augmented data points. The generative model can then be used to augment training sets for any end discriminative model.
In this blog post, we’ll start by reviewing the prevalence of heuristic data augmentation in practice, then outline our proposed approach, and finally review our empirical results.
Heuristic Data Augmentation in Practice
Data augmentation is the secret sauce in today’s state-of-the-art pipelines for benchmark image recognition tasks. To underscore both the omnipresence and diversity of heuristic data augmentation in practice, we compiled a list of the top ten models for the well documented CIFAR-10 and CIFAR-100 tasks. The takeaway? 10 out of 10 of the top CIFAR-10 results and 9 out of 10 of the top CIFAR-100 results use data augmentation, for average boosts (when reported) of 3.71 and 13.39 points in accuracy, respectively. Moreover, we see that while some sets of papers inherit a simple data augmentation strategy from prior work (in particular, all the recent ResNet variants), there are still a large variety of approaches. And in general, the particular choice of data augmentation strategy is widely reported to have large effects on performance.
Disclaimer: the below table is compiled from this wonderful list or from the latest CVPR best paper (indicated by a *) which achieves new state-of-the-art results. We compile it for illustrative purposes and it is not necessarily comprehensive.
| Dataset | Pos. | Name | Err. w/DA | Err. w/o DA | Notes |
|---|---|---|---|---|---|
| CIFAR-10 | 1 | DenseNet | 3.46 | - | Random shifts, flips |
| 2 | Fractional Max-Pooling | 3.47 | - | Randomized mix of translations, rotations, reflections, stretching, shearing, and random RGB color shift operations | |
| 3* | Wide ResNet | 4.17 | - | Random shifts, flips | |
| 4 | Striving for Simplicity: The All Convolutional Net | 4.41 | 9.08 | “Heavy” augmentation: images expanded, then scaled, rotated, color shifted randomly | |
| 5* | FractalNet | 4.60 | 7.33 | Random shifts, flips | |
| 6* | ResNet (1001-Layer) | 4.62 | 10.56 | Random shifts, flips | |
| 7* | ResNet with Stochastic Depth (1202-Layer) | 4.91 | - | Random shifts, flips | |
| 8 | All You Need is a Good Init | 5.84 | - | Random shifts, flips | |
| 9 | Generalizing Pooling Functions in Convolutional Neural Networks: Mixed, Gated, and Tree | 6.05 | 7.62 | Flips, random shifts, other simple ones | |
| 10 | Spatially-Sparse Convolutional Neural Networks | 6.28 | - | Affine transformations | |
| CIFAR-100 | 1* | DenseNet | 17.18 | - | Random shifts, flips |
| 2* | Wide ResNets | 20.50 | - | Random shifts, flips | |
| 3* | ResNet (1001-Layer) | 22.71 | 33.47 | Random shifts, flips | |
| 4* | FractalNet | 23.30 | 35.34 | Random shifts, flips | |
| 5 | Fast and Accurate Deep Network Learning by Exponential Linear Units | - | 24.28 | ||
| 6 | Spatially-Sparse Convolutional Neural Networks | 24.3 | - | Affine transformations | |
| 7* | ResNet with Stochastic Depth (1202-Layer) | 24.58 | 37.80 | Random shifts, flips | |
| 8 | Fractional Max-Pooling | 26.39 | - | Randomized mix of translations, rotations, reflections, stretching, and shearing operations, and random RGB color shifts | |
| 9* | ResNet (110-Layer) | 27.22 | 44.74 | Random shifts, flips | |
| 10 | Scalable Bayesian Optimization Using Deep Neural Networks | 27.4 | - | Hue, saturation, scalings, horizontal flips |
This medley of primarily manual approaches with widely varying results suggests that data augmentation is a prime candidate for automation. Indeed, various related lines of work all have interesting takes at automating various aspects of data augmentation–for example learning class-conditional GANs to generate data, applying transformations adversarially either over given sets of invariances or over learned local adversarial perturbations, or performing data augmentation via interpolation in feature space, to name a few. Our focus is instead on directly leveraging and exploiting SME domain knowledge of transformation operations, without assuming that this domain knowledge will be specified completely or correctly, without assuming access to large labeled datasets, and without assuming that the provided operations will be differentiable or deterministic. Our approach to learning how to augment data—described in the next section—is motivated by these practical consierations.
Learning to Compose Domain-Specific Transformations
In our setup, we make the novel choice to model data augmentation operations as sequences of incremental, black-box transformation functions (TFs) provided by users, which we do not assume to be either differentiable or deterministic. For example, these might include rotating by a few degrees, or shifting the hue in a domain-specific manner by a small amount, or shifting a segmented area of an image by a small random vector. This representation will allow us to have fine-grained control over both the (discretized) parameterization and order of composition of these TFs, and allows for a wide variety of TFs such as the below examples from our experiments with image recognition and natural language processing tasks. Our goal is then to learn a TF sequence generator that results in realistic and diverse augmented data points.
Weakening the Class-Invariance Assumption
The core assumption behind standard data augmentation in practice is that any sequence of transformation operations applied to any data point will produce an augmented point in the same class. Of course, this is unrealistic and many real-world data augmentation pipelines violate this assumption. Instead, we make a weaker modeling assumption: a sequence of transformation operations applied to a data point will produce an augmented point either in the same class or in a null class outside the distribution of interest. That is, we can reasonably assume that we won’t turn an image of a plane into one of a dog, but we might turn it into an indistiguishable garbage image! This critical assumption allows us to use unlabeled data to train our augmentation model.

We demonstrate the intuition behind this modeling assumption in the above figure by taking images from CIFAR-10 (each row) and searching for transformation sequences that map them to different classes (each column) according to a trained discriminative model. We see that the transformed images do not look much like the class they are being mapped to, but often do look like garbage.
Learning a TF Sequence Model Adversarially from Unlabeled Data
Armed with our weaker invariance assumption, we can now leverage unlabeled data to train a TF sequence generator, using adversarial techniques.
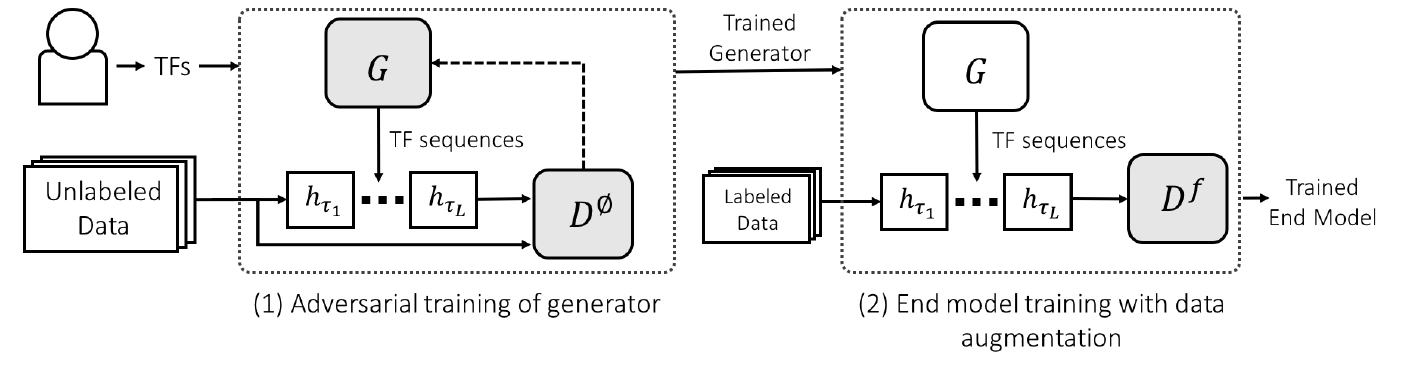
Our modeling setup is summarized in Figure 2. Given a set of TFs \(h_1,...,h_K\), our objective is to learn a TF sequence generator \(G_{\theta}\) which generates sequences of TF indices \(\tau\in\{1,K\}^L\) with fixed length \(L\) so that the augmented data point \(h_{\tau_L} \circ ... \circ h_{\tau_1}(x)\) is realistic, i.e. not in the null class. In order to estimate whether or not the augmented point is in the null class, we use a generative adversarial network (GAN) setup and simultaneously train a discriminator \(D^{\phi}_{\emptyset}\). The discriminator’s job is to produce values close to 1 for data points in the original training set and values close to 0 for augmented data points. We can write out our objective term as
\[J_{\emptyset} = \mathbb{E}_{\tau\sim G_{\theta}} \mathbb{E}_{x\sim\mathcal{U}} \left[ \log(1 - D_\phi^\emptyset(h_{\tau_L}\circ ...\circ h_{\tau_1}(x)))\right] + \mathbb{E}_{x'\sim\mathcal{U}}\left[ \log(D_\phi^\emptyset(x')) \right]\]where \(\mathcal{U}\) is a distribution of unlabeled data (our unlabeled training set). We use an alternating optimization scheme, minimizing \(J_{\emptyset}\) with respect to \(\theta\) and maximizing with respect to \(\phi\). We also include a diversity term in the objective to ensure that the original data point and augmented data point aren’t too similar. Since the TFs can be non-differentiable and/or non-deterministic, we cannot backpropagate through all of the parameters of \(G_{\theta}\) as normal and instead use a recurrent policy gradient.
We evaluated two model classes for \(G_{\theta}\):
- Mean field: each sequential TF is chosen independently, reducing the task to learning the \(K\) sampling frequencies of the TFs
- Long short-term memory network (LSTM): the input to each cell is a one-hot vector of the previously sampled TF, and the output from each cell of the network is a sampling distribution for the next TF. Making state-based decisions is critical when TFs are lossy when applied together, or are non-commutative.
Experimental Results on Image and Text Data
Our experiments thus far have been focused on pragmatics. Does learning an augmentation model produce better end classifier results than heuristic data augmentation approaches? To tackle this question, we evaluated on CIFAR-10, MNIST, and a subset of DDSM with mass segmentations.
For CIFAR-10, we used a wide range of standard TFs (incremental rotations, shears, swirls, deformations, hue, saturation, and contrast shifts, and horizontal flips). For MNIST, we used a similar set but also included erosion and dilation operators. For the DDSM mammogram tumor classification task, we used some generic TFs along with two domain-specific ones developed by radiological experts: A brightness enhancer which only shifts brightness levels to those attainable by the mammography imaging process, and a structure translator which moves segmented masses, resamples the background tissue, and then fills in gaps using Poisson blending. Due to the intricacy of these domain-specific TFs in particular, many random augmentation sequences resulted in non-realistic images, punctuating the need for a learned augmentation model.
We also ventured outside of the imaging domain into natural language processing, where data augmentation recieves less attention. We augmented sentences in the ACE corpus for a relation classification task. The TFs were based on swapping out words via sampling replacements from a trigram language model, specifying parts-of-speech and/or position with relation to the entities. For example, one TF swapped verbs in between the entity mentions.
| Task | Dataset % | None | Basic | Heuristic | MF | LSTM | Gain over Heuristic |
|---|---|---|---|---|---|---|---|
| MNIST | 1 | 90.2 | 95.3 | 95.9 | 96.5 | 96.7 | 0.8 |
| 10 | 97.3 | 98.7 | 99.0 | 99.2 | 99.1 | 0.2 | |
| CIFAR-10 | 10 | 66.0 | 73.1 | 77.5 | 79.8 | 81.5 | 4.0 |
| 100 | 87.8 | 91.9 | 92.3 | 94.4 | 94.0 | 2.1 | |
| ACE (F1 Score) | 100 | 62.7 | 59.9 | 62.8 | 62.9 | 64.2 | 1.4 |
| DDSM | 10 | 57.6 | 58.8 | 59.3 | 58.2 | 61.0 | 1.7 |
| DDSM + DS | 53.7 | 59.9 | 62.7 | 9.0 |
The above table contains our primary results, showing end model performance on subsampled (Dataset %) labeled data using no augmentation (None), simple random crops or equivalent (Basic), heuristic random sequences of TFs (Heuristic), or one of our two trained generators (trained on the full unlabeled dataset). We used off-the-shelf models as our end classifiers in order to focus on relative gains from learning composition models. We used a standard 56-layer ResNet for CIFAR-10, and much simpler convolutional neural networks for MNIST and DDSM. For ACE, we used a bidirectional long short-term memory network with word-level attention. In particular we notice:
- We get strong relative gains over heuristic (random) data augmentation
- In most cases, modeling the sequences with a state-based model helps!
- In the DDSM case, we show both with and without the domain specific (DS) TFs; we see that without learning how to apply them, they actually hurt performance—but with our method, they help!
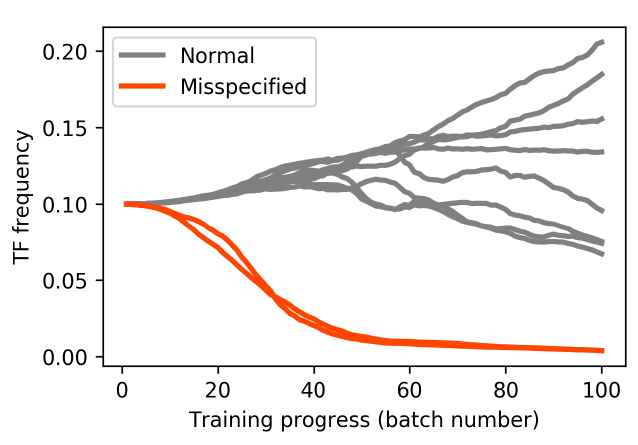
We also investigated the robustness of our method to buggy or poorly specified TFs by intentionally including some in the MNIST pipeline. The probability of applying each TF (the “TF frequency”) as learned by the mean field model, as training progresses, are shown in the figure below. Importantly, we see that the model learns to avoid applying the misspecified TFs!
Using the Approach: TANDA
Does it sound like learning data augmentation models could help your machine learning pipeline? We’ve open-sourced a TensorFlow-based implementation of our approach, TANDA (Transformation Adversarial Networks for Data Augmentation). Try it out and let us know what you think! We hope that this code not only helps to improve model performance on a variety of new and existing tasks, but also helps the exploration of exciting next-step directions such as adding in more advanced transformation regularization, exploring applications to other modalities, and advancing theoretical understanding of data augmentation!

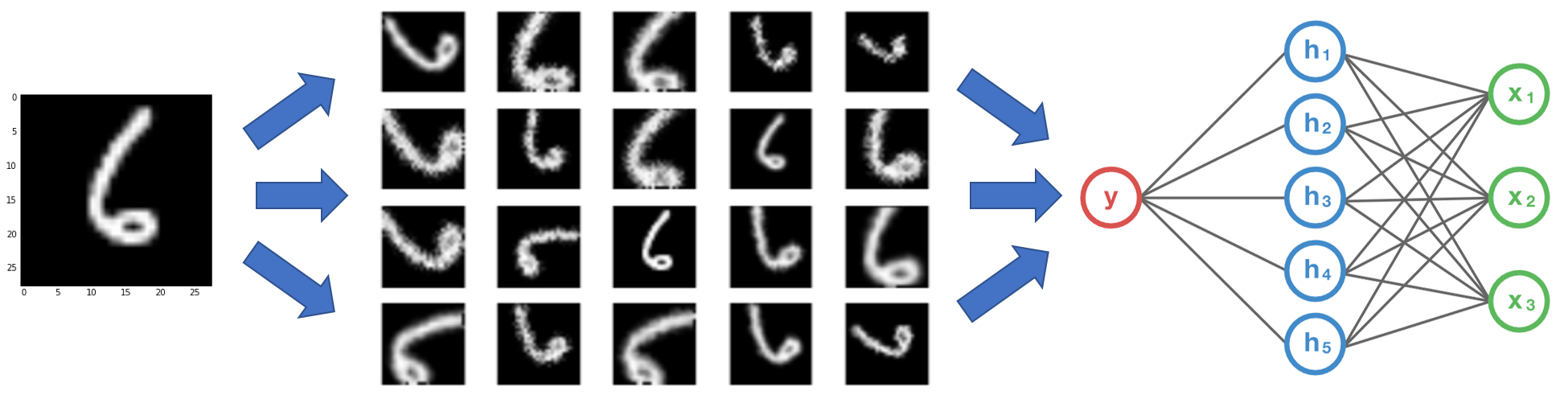
Figure: TANDA learning how to augment MNIST images to appear realistic as training progresses (with minimal diversity objective coefficient, for visual effect!).