Snorkel and The Dawn of Weakly Supervised Machine Learning
In this post, we’ll discuss our approaches to weakly supervising complex machine learning models in the age of big data. Learn more about Snorkel, our system for rapidly creating training sets with weak supervision, at snorkel.stanford.edu.
Labeled Training Data: The New New Oil

Today’s state-of-the-art machine learning models are both more powerful and easier to spin up than ever before. Whereas practitioners used to spend the bulk of their time carefully engineering features for their models, we can now feed in raw data - images, text, genomic sequences, etc. - to systems that learn their own features. These powerful models, like deep neural networks, produce state-of-the-art results on many tasks. This new power and flexibility has sparked excitement about machine learning in fields ranging from medicine to business to law.
There is a hidden cost to this success, however: these models require massive labeled training sets. And while machine learning researchers can use carefully manicured training sets to benchmark their new models, these labeled training sets do not exist for most real world tasks. Creating sufficiently large labeled training datasets is extremely expensive and slow in practice. This is exacerbated when domain expertise is required to label data, such as a radiologist labeling MRI images as containing malignant tumors or not. In addition, hand-labeled training data is not adaptable or flexible, and thus entirely unsuitable for learning tasks which change over time.
Weak Supervision
We’re quite excited about a set of approaches broadly termed weak supervision to address the bottleneck described above. The basic idea is to allow users to provide supervision at a higher level than case-by-case labeling, and then to use various statistical techniques to deal with the noisier labels that we get. Working with domain experts, we found that this type of supervision is easier and faster to provide. And surprisingly, by getting large volumes of lower-quality supervision in this way, we can train higher-quality models at a fraction of the time and cost. We see weak supervision-based systems as one of the most exciting directions in terms of how users will train, deploy, and interact with machine learning systems.
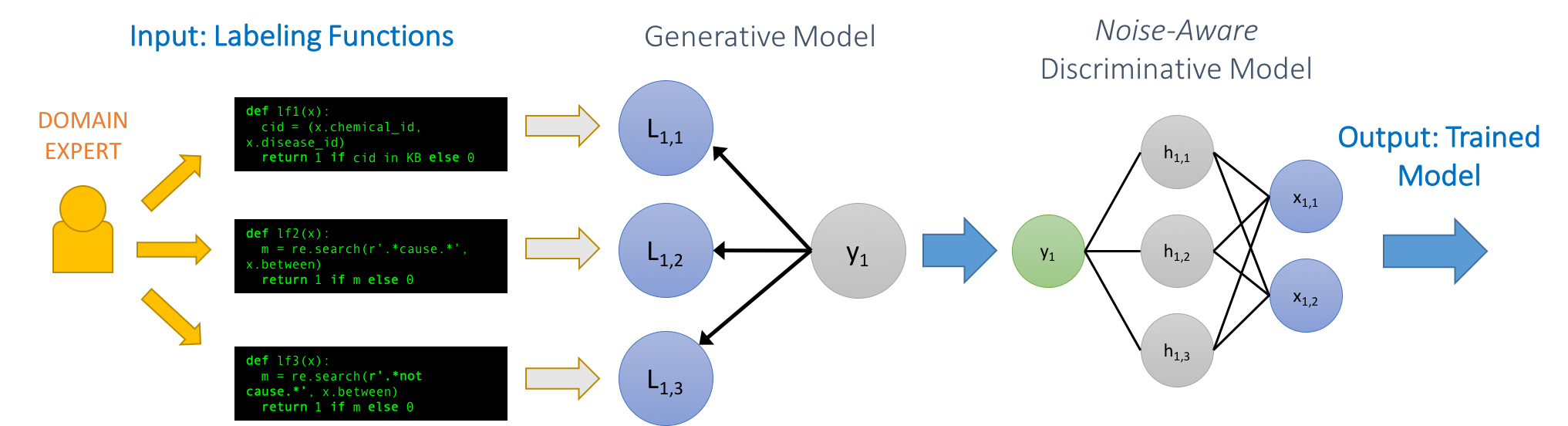
One of the main techniques that we are currently developing in this direction is called data programming (see our blog post about it here, or the NIPS 2016 paper here). In the data programming paradigm, users focus on writing a set of labeling functions, which are just small functions that programmatically label data. The labels that they produce are noisy and could conflict with each other. However, we can model this noise by learning a generative model of the labeling process, effectively synthesizing the labels created by the labeling functions. We can then use this new label set to train a noise-aware end discriminative model (such as a neural network in TensorFlow) with higher accuracy. This framework allow users to easily “program” machine learning models with high-level functions, and leverage whatever code, domain heuristics, or data resources they have at hand. And, since the supervision is provided as functions, it allows us to scale with the amount of unlabeled data!
Snorkel
Snorkel is a system built around the data programming paradigm for rapidly creating, modeling, and managing training data. Snorkel is currently focused on accelerating the development of structured or “dark” data extraction applications for domains in which large labeled training sets are not available or easy to obtain. For example, Snorkel is being currently used on text extraction applications on medical records at the Deparment of Veterans Affairs, to mine scientific literature for adverse drug reactions in collaboration with the Federal Drug Administration, and to comb through everything from surgical reports to after-action combat reports for valuable structured data.
…And Beyond
We’ve been working hard on next steps for data programming, Snorkel, and other weak supervision techniques, some of which we’ve already posted about:
-
Structure learning: How can we detect correlations and other statistical dependencies among labeling functions? Modeling these dependencies are important because a misspecified generative model can lead to misestimating the labeling functions’ accuracies. We’ve proposed a method that can quickly identify dependencies without any ground truth data.
-
Socratic learning: How can we more effectively model and debug the user-written labeling functions in data programming? We’re working on a method to use differences between the generative and discriminative models to help do this.
-
Semi-structured data extraction: How can we handle extracting structured data from data that has some structure such as tables embedded in PDFs and webpages? We’ve been working on a system called Fonduer to make this fast and easy in Snorkel!
-
Learning from natural language supervision: Can we use natural language as a form of weak supervision, parsing the semantics of natural language statements and then using these as labeling functions? We’ve done some exciting preliminary work here!